LoRA是一种流行的微调大语言模型的手段,这是因为LoRA仅需在预训练模型需要微调的地方添加旁路矩阵。LoRA 的作者们还提供了一个易于使用的库 loralib,它极大地简化了使用 LoRA 微调模型的过程。这个库允许用户轻松地将 LoRA 层添加到现有的模型架构中,而无需深入了解其底层实现细节。这使得 LoRA 成为了一种非常实用的技术,既适合研究者也适合开发人员。下面给出了一个LoRA微调Bert模型的具体例子。
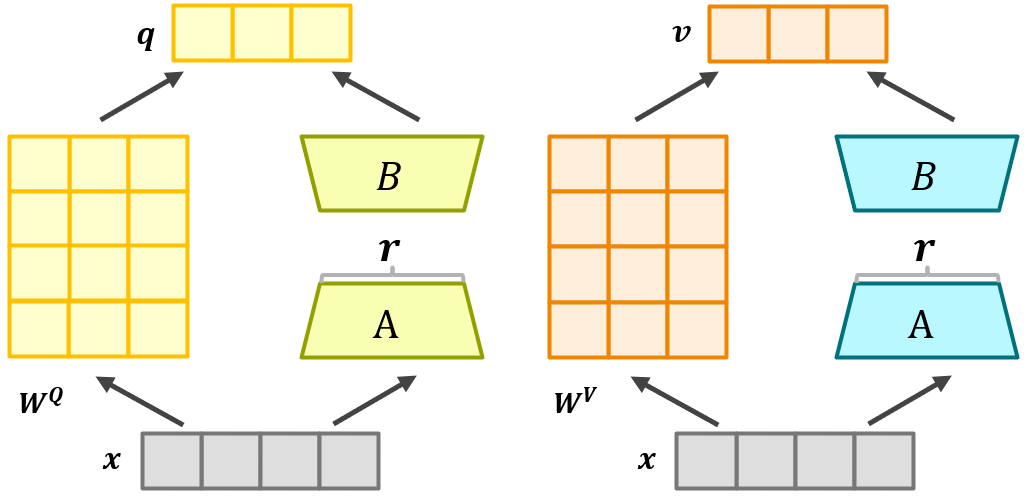
下图给出了一个LoRA微调Bert中自注意力矩阵 W Q W^Q WQ的例子。如图所示,通过冻结矩阵 W Q W^Q WQ,并且添加旁路低秩矩阵 A , B A,B A,B来进行微调。同理,使用LoRA来微调 W K W^K WK也是如此。
我们给出了通过LoRA来微调Bert模型中自注意力矩阵的具体代码。代码是基于huggingface中Bert开源模型进行改造。Bert开源项目链接如下:
https://huggingface.co/transformers/v4.3.3/_modules/transformers/models/bert/modeling_bert.html
基于LoRA微调的代码如下:
# 环境配置
# pip install loralib
# 或者
# pip install git+https://github.com/microsoft/LoRA
import loralib as loraclass LoraBertSelfAttention(BertSelfAttention):"""继承BertSelfAttention模块对Query,Value用LoRA进行微调参数:- r (int): LoRA秩的大小- config: Bert模型的参数配置"""def __init__(self, r=8, *config):super().__init__(*config)# 获得所有的注意力的头数d = self.all_head_size # 使用LoRA提供的库loralibself.lora_query = lora.Linear(d, d, r)self.lora_value = lora.Linear(d, d, r)def lora_query(self, x):"""对Query矩阵执行Wx + BAx操作"""return self.query(x) + F.linear(x, self.lora_query)def lora_value(self, x):"""对Value矩阵执行Wx + BAx操作"""return self.value(x) + F.linear(x, self.lora_value)def forward(self, hidden_states, *config):"""更新涉及到Query矩阵和Value矩阵的操作"""# 通过LoRA微调Query矩阵mixed_query_layer = self.lora_query(hidden_states)is_cross_attention = encoder_hidden_states is not Noneif is_cross_attention and past_key_value is not None:# reuse k,v, cross_attentionskey_layer = past_key_value[0]value_layer = past_key_value[1]attention_mask = encoder_attention_maskelif is_cross_attention:key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))# 通过LoRA微调Value矩阵value_layer = self.transpose_for_scores(self.lora_value(hidden_states))attention_mask = encoder_attention_maskelif past_key_value is not None:key_layer = self.transpose_for_scores(self.key(hidden_states))# 通过LoRA微调Value矩阵value_layer = self.transpose_for_scores(self.lora_value(hidden_states))key_layer = torch.cat([past_key_value[0], key_layer], dim=2)value_layer = torch.cat([past_key_value[1], value_layer], dim=2)else:key_layer = self.transpose_for_scores(self.key(hidden_states))# 通过LoRA微调Value矩阵value_layer = self.transpose_for_scores(self.lora_value(hidden_states))query_layer = self.transpose_for_scores(mixed_query_layer)if self.is_decoder:past_key_value = (key_layer, value_layer)# Query矩阵与Key矩阵算点积得到注意力分数attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":seq_length = hidden_states.size()[1]position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)distance = position_ids_l - position_ids_rpositional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibilityif self.position_embedding_type == "relative_key":relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)attention_scores = attention_scores + relative_position_scoreselif self.position_embedding_type == "relative_key_query":relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_keyattention_scores = attention_scores / math.sqrt(self.attention_head_size)if attention_mask is not None:attention_scores = attention_scores + attention_maskattention_probs = nn.Softmax(dim=-1)(attention_scores)attention_probs = self.dropout(attention_probs)if head_mask is not None:attention_probs = attention_probs * head_maskcontext_layer = torch.matmul(attention_probs, value_layer)context_layer = context_layer.permute(0, 2, 1, 3).contiguous()new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)context_layer = context_layer.view(*new_context_layer_shape)outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)if self.is_decoder:outputs = outputs + (past_key_value,)return outputsclass LoraBert(nn.Module):def __init__(self, task_type, num_classes=None, dropout_rate=0.1, model_id="bert-base-cased",lora_rank=8, train_biases=True, train_embedding=False, train_layer_norms=True):"""- task_type: 设计任务的类型,如:'glue', 'squad_v1', 'squad_v2'.- num_classes: 分类类别的数量.- model_id: 预训练好的Bert的ID,如:"bert-base-uncased","bert-large-uncased".- lora_rank: LoRA秩的大小.- train_biases, train_embedding, train_layer_norms: 这是参数是否需要训练 """super().__init__()# 1.加载权重self.model_id = model_idself.tokenizer = BertTokenizer.from_pretrained(model_id)self.model = BertForPreTraining.from_pretrained(model_id)self.model_config = self.model.config# 2.添加模块d_model = self.model_config.hidden_sizeself.finetune_head_norm = nn.LayerNorm(d_model)self.finetune_head_dropout = nn.Dropout(dropout_rate)self.finetune_head_classifier = nn.Linear(d_model, num_classes)# 3.通过LoRA微调模型self.replace_multihead_attention()self.freeze_parameters()def replace_self_attention(self, model):"""把预训练模型中的自注意力换成自己定义的LoraBertSelfAttention"""for name, module in model.named_children():if isinstance(module, RobertaSelfAttention):layer = LoraBertSelfAttention(r=self.lora_rank, config=self.model_config)layer.load_state_dict(module.state_dict(), strict=False)setattr(model, name, layer)else:self.replace_self_attention(module)def freeze_parameters(self):"""将除了涉及LoRA微调模块的其他参数进行冻结LoRA微调影响到的模块: the finetune head, bias parameters, embeddings, and layer norms """for name, param in self.model.named_parameters():is_trainable = ("lora_" in name or"finetune_head_" in name or(self.train_biases and "bias" in name) or(self.train_embeddings and "embeddings" in name) or(self.train_layer_norms and "LayerNorm" in name))param.requires_grad = is_trainablepeft库中包含了LoRA在内的许多大模型高效微调方法,并且与transformer库兼容。使用peft库对大模型flan-T5-xxl进行LoRA微调的代码例子如下:# 通过LoRA微调flan-T5-xxl
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
# 模型介绍:https://huggingface.co/google/flan-t5-xxl
model_name_or_path = "google/flan-t5-xxl"model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path, load_in_8bit=True, device_map="auto")
peft_config = LoraConfig(r=8,lora_alpha=16, target_modules=["q", "v"], # 仅对Query,Value矩阵进行微调lora_dropout=0.1,bias="none", task_type=TaskType.SEQ_2_SEQ_LM
)
model = get_peft_model(model, peft_config)
# 打印可训练的参数
model.print_trainable_parameters()