通过估计数据分布的梯度进行生成建模
Paper Title:Generative Modeling by Estimating Gradients of the Data Distribution
Paper是斯坦福大学发表在NIPS 2019的工作
Paper地址
Abstract
我们引入了一种新的生成模型,其中样本通过朗之万动力学生成,使用通过得分匹配估计的数据分布梯度。
由于当数据位于低维流形上时,梯度可能定义不明确且难以估计,因此我们使用不同级别的高斯噪声扰动数据,并联合估计相应的得分,即所有噪声级别的扰动数据分布梯度的矢量场。对于采样,我们提出了一种退火朗之万动力学,其中我们使用对应于逐渐降低的噪声水平的梯度,因为采样过程越来越接近数据流形。我们的框架允许灵活的模型架构,不需要在训练期间进行采样或使用对抗方法,并提供可用于原则模型比较的学习目标。我们的模型在 MNIST、CelebA 和 CIFAR-10 数据集上产生的样本与 GAN 相当,在 CIFAR-10 上实现了 8.87 的最新inception分数。此外,我们证明我们的模型可以通过图像修复实验学习有效的表示。
1 Introduction
生成模型在机器学习中有许多应用。举几个例子,它们已被用于生成高保真图像 [26, 6],合成逼真的语音和音乐片段 [58],提高半监督学习的性能 [28, 10],检测对抗样本和其他异常数据 [54],模仿学习 [22],以及在强化学习中探索有前途的状态 [41]。最近的进展主要由两种方法驱动:基于似然的方法 [17, 29 , 11 , 60 29,11,60 29,11,60] 和生成对抗网络(GAN [15])。前者使用对数似然(或合适的替代物)作为训练目标,而后者使用对抗训练来最小化模型与数据分布之间的 f f f-散度 [40] 或积分概率度量 [ 2 , 55 ] [2,55] [2,55]。
尽管基于似然的模型和GAN已经取得了巨大的成功,但它们都有一些内在的局限性。例如,基于似然的模型要么必须使用专门的架构来构建标准化的概率模型(例如,自回归模型、流模型),要么使用替代损失(例如,在变分自动编码器中使用的证据下界 [29],能量基模型中的对比散度 [21])进行训练。GAN避免了一些基于似然模型的限制,但由于对抗训练过程,其训练可能不稳定。此外,GAN目标不适合评估和比较不同的GAN模型。虽然其他生成建模的目标存在,如噪声对比估计 [19] 和最小概率流 [50],但这些方法通常仅在低维数据中效果较好。
在本文中,我们探讨了一种新的生成建模原则,该原则基于对对数数据密度的(Stein)得分 [33] 的估计和采样,这是一种在输入数据点处对数密度函数的梯度。这是一个指向对数数据密度增长最多方向的向量场。我们使用通过得分匹配 [24] 训练的神经网络从数据中学习这个向量场。然后我们使用Langevin动力学生成样本,其大致通过沿着(估计的)得分向量场逐渐将随机初始样本移动到高密度区域来工作。然而,这种方法面临两个主要挑战。首先,如果数据分布支撑在低维流形上(正如假设的那样对于许多现实世界数据集),得分在环境空间中将未定义,并且得分匹配将无法提供一致的得分估计器。其次,低数据密度区域(例如,远离流形的区域)的训练数据稀缺,阻碍了得分估计的准确性并减缓了Langevin动力学采样的混合过程。由于Langevin动力学通常在数据分布的低密度区域初始化,因此这些区域中不准确的得分估计将对采样过程产生负面影响。此外,由于需要穿越低密度区域以在分布的模式之间进行转换,混合可能会变得困难。
为了解决这两个挑战,我们提出用不同幅度的随机高斯噪声来扰动数据。添加随机噪声可确保结果分布不会收敛到低维流形上。较大的噪声水平将在原始(未经扰动的)数据分布的低密度区域产生样本,从而改善得分估计。关键是,我们训练了一个噪声水平条件下的单个得分网络,并在所有噪声幅度下估计得分。然后我们提出了一种退火版本的Langevin动力学,在最初使用对应于最高噪声水平的得分,逐渐降低噪声水平,直到它足够小,以至于与原始数据分布无法区分。我们的采样策略受模拟退火 [30,37] 启发,该方法从启发式角度改进了多模态景观的优化。
我们的方法具有几个理想的特性。首先,我们的目标对于几乎所有得分网络的参数化都是可解的,无需特殊的约束或架构,并且可以在训练过程中无需对抗训练、MCMC采样或其他近似来优化。该目标还可用于在同一数据集上定量地比较不同的模型。在实验中,我们证明了我们的方法在MNIST、CelebA [34] 和CIFAR-10 [31] 上的有效性。我们展示了生成的样本与现代基于似然的方法和GAN生成的样本相当。在CIFAR-10上,我们的模型为无条件生成模型设定了新的最先进的Inception得分8.87,并取得了有竞争力的FID得分25.32。我们通过图像修复实验展示了模型学习数据的有意义表示。
2 Score-based generative modeling
假设我们的数据集由独立同分布(i.i.d.)样本 { x i ∈ R D } i = 1 N \left\{\mathbf{x}_i \in \mathbb{R}^D\right\}_{i=1}^N {xi∈RD}i=1N 构成,这些样本来自未知的数据分布 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x)。我们定义概率密度 p ( x ) p(\mathbf{x}) p(x) 的得分为 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x)。得分网络 s θ : R D → R D \mathbf{s}_{\boldsymbol{\theta}}: \mathbb{R}^D \rightarrow \mathbb{R}^D sθ:RD→RD 是一个由参数 θ \boldsymbol{\theta} θ 参数化的神经网络,它将被训练来逼近 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 的得分。生成建模的目标是使用数据集来学习一个模型,以从 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 中生成新的样本。基于得分的生成建模框架包含两个要素:得分匹配和Langevin动力学。
2.1 Score matching for score estimation
得分匹配 [24] 最初是为基于未知数据分布的i.i.d.样本学习非归一化统计模型而设计的。根据 [53],我们将其重新用于得分估计。使用得分匹配,我们可以直接训练得分网络 s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x) 来估计 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) ∇xlogpdata(x),而无需首先训练模型来估计 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x)。与得分匹配的典型用法不同,我们选择不使用基于能量模型的梯度作为得分网络,以避免因高阶梯度带来的额外计算。目标函数最小化 1 2 E p data [ ∥ s θ ( x ) − ∇ x log p data ( x ) ∥ 2 2 ] \frac{1}{2} \mathbb{E}_{p_{\text{data}}}\left[\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})-\nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right\|_2^2\right] 21Epdata[∥sθ(x)−∇xlogpdata(x)∥22],这可以证明与下式等价(忽略一个常数):
E p data ( x ) [ tr ( ∇ x s θ ( x ) ) + 1 2 ∥ s θ ( x ) ∥ 2 2 ] , ( 1 ) \mathbb{E}_{p_{\text{data}}(\mathbf{x})}\left[\operatorname{tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right)+\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2\right], \quad(1) Epdata(x)[tr(∇xsθ(x))+21∥sθ(x)∥22],(1)
其中 ∇ x s θ ( x ) \nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) ∇xsθ(x) 表示 s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x) 的Jacobian矩阵。正如 [53] 所示,在某些正则性条件下,方程(3)的最小化结果(记作 s θ ∗ ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x}) sθ∗(x))几乎必然满足 s θ ∗ ( x ) = ∇ x log p data ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x})=\nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) sθ∗(x)=∇xlogpdata(x)。在实践中,可以使用数据样本快速估计方程(1)中 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 的期望。然而,由于需要计算 tr ( ∇ x s θ ( x ) ) \operatorname{tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right) tr(∇xsθ(x)),得分匹配无法扩展到深度网络和高维数据 [53]。下面我们讨论两种流行的大规模得分匹配方法。
式(1)的推导:
1 2 E p data [ ∥ s θ ( x ) − ∇ x log p data ( x ) ∥ 2 2 ] = E p data [ 1 2 ∥ s θ ( x ) − ∇ x log p data ( x ) ∥ 2 ] = E p data [ 1 2 ∥ s θ ( x ) ∥ 2 − s θ ( x ) T ∇ x log p data ( x ) + 1 2 ∥ ∇ x log p data ( x ) ∥ 2 ⏟ = der C 1 , independent of θ ] . \begin{aligned} \frac{1}{2} \mathbb{E}_{p_{\text{data}}}\left[\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})-\nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right\|_2^2\right] & =\mathbb{E}_{p_{\text{data}}}\left[\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathrm{x})-\nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right\|^2\right] \\ & =\mathbb{E}_{p_{\text{data}}}[\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathrm{x})\right\|^2-\mathbf{s}_{\boldsymbol{\theta}}(\mathrm{x})^T \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})+\underbrace{\frac{1}{2}\left\|\nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right\|^2}_{\underset{\text { der }}{=} C_1, \text { independent of } \boldsymbol{\theta}}] . \end{aligned} 21Epdata[∥sθ(x)−∇xlogpdata(x)∥22]=Epdata[21∥sθ(x)−∇xlogpdata(x)∥2]=Epdata[21∥sθ(x)∥2−sθ(x)T∇xlogpdata(x)+ der =C1, independent of θ 21∥∇xlogpdata(x)∥2].
最后一项与 θ \theta θ无关,因此可以忽略,第一项通过模型输出可以计算出来,重点关注第二项:
E p data [ − s θ ( x ) T ∇ x log p data ( x ) ] = ∫ p data ( x ) [ − ( ∂ log p data ( x ) ∂ x ) T s θ ( x ) ] d x = − ∫ p data ( x ) [ ∑ i = 1 N ∂ log p data ( x ) ∂ x i s θ i ( x ) ] d x = − ∑ i = 1 N ∫ p data ( x ) [ ( 1 p data ( x ) ∂ p data ( x ) ∂ x i ) s θ i ( x ) ] d x = − ∑ i = 1 N ∫ [ ∂ p data ( x ) ∂ x i s θ i ( x ) ] d x = − ∑ i = 1 N ∫ ( ∂ ( p data ( x ) s θ i ( x ) ) ∂ x i − p data ( x ) ∂ s θ i ( x ) ∂ x i ) d x = ∫ p data ( x ) [ ∑ i = 1 N ∂ s θ i ( x ) ∂ x i ] d x = ∫ p data ( x ) ( tr ( ∂ s θ ( x ) ∂ x ) ) d x \begin{aligned} \mathbb{E}_{p_{\text{data}}}\left[-\mathbf{s}_{\boldsymbol{\theta}}(\mathrm{x})^T \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right]&= \int p_{\text{data}}(\mathbf{x})\left[-\left(\frac{\partial \log p_{\text{data}}(\mathbf{x})}{\partial \mathbf{x}}\right)^T \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right] d \mathbf{x}=- \int p_{\text{data}}(\mathbf{x})\left[\sum_{i=1}^N \frac{\partial \log p_{\text{data}}(\mathbf{x})}{\partial \mathbf{x}_i} \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right] d \mathbf{x} \\ & =- \sum_{i=1}^N \int p_{\text{data}}(\mathbf{x})\left[\left(\frac{1}{p_{\text{data}}(\mathbf{x})} \frac{\partial p_{\text{data}}(\mathbf{x})}{\partial \mathbf{x}_i}\right) \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right] d \mathbf{x}=- \sum_{i=1}^N \int\left[\frac{\partial p_{\text{data}}(\mathbf{x})}{\partial \mathbf{x}_i} \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right] d \mathbf{x} \\ & =- \sum_{i=1}^N \int\left(\frac{\partial\left(p_{\text{data}}(\mathbf{x}) \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right)}{\partial \mathbf{x}_i}-p_{\text{data}}(\mathbf{x}) \frac{\partial \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})}{\partial \mathbf{x}_i}\right) d \mathbf{x}= \int p_{\text{data}}(\mathbf{x})\left[\sum_{i=1}^N \frac{\partial \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})}{\partial \mathbf{x}_i}\right] d \mathbf{x} \\ & = \int p_{\text{data}}(\mathbf{x})\left(\operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right)\right) d \mathbf{x} \end{aligned} Epdata[−sθ(x)T∇xlogpdata(x)]=∫pdata(x)[−(∂x∂logpdata(x))Tsθ(x)]dx=−∫pdata(x)[i=1∑N∂xi∂logpdata(x)sθi(x)]dx=−i=1∑N∫pdata(x)[(pdata(x)1∂xi∂pdata(x))sθi(x)]dx=−i=1∑N∫[∂xi∂pdata(x)sθi(x)]dx=−i=1∑N∫(∂xi∂(pdata(x)sθi(x))−pdata(x)∂xi∂sθi(x))dx=∫pdata(x)[i=1∑N∂xi∂sθi(x)]dx=∫pdata(x)(tr(∂x∂sθ(x)))dx
在最后一步推导中,我们从和对数几率梯度的期望相关的表达式中得到了迹(trace)的形式。让我们逐步分析这一推导过程。
我们得到了如下的中间结果:
E p data [ − s θ ( x ) T ∇ x log p data ( x ) ] = ∫ p data ( x ) [ ∑ i = 1 N ∂ s θ i ( x ) ∂ x i ] d x \mathbb{E}_{p_{\text{data}}}\left[-\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})^T \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x})\right] = \int p_{\text{data}}(\mathbf{x}) \left[\sum_{i=1}^N \frac{\partial \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})}{\partial \mathbf{x}_i}\right] d \mathbf{x} Epdata[−sθ(x)T∇xlogpdata(x)]=∫pdata(x)[i=1∑N∂xi∂sθi(x)]dx
其中, s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x) 是关于 x \mathbf{x} x 的函数,并且对于每一个 i i i, s θ i ( x ) \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x}) sθi(x) 是 i i i-th 维度的分量。现在要注意的是,在求和 ∑ i = 1 N ∂ s θ i ( x ) ∂ x i \sum_{i=1}^N \frac{\partial \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})}{\partial \mathbf{x}_i} ∑i=1N∂xi∂sθi(x) 的过程中,我们正是将每一个分量的导数加在一起,这个加和正好是梯度的雅可比矩阵(Jacobian matrix)对角元素的和。
迹(trace)是一个方阵对角线上元素的和。在这种情况下, s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x) 的雅可比矩阵的迹 tr ( ∂ s θ ( x ) ∂ x ) \operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right) tr(∂x∂sθ(x)) 就是矩阵 ∂ s θ ( x ) ∂ x \frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}} ∂x∂sθ(x) 对角线上元素(即各分量关于对应维度的导数)的和。
具体来说,对于雅可比矩阵 ∂ s θ ( x ) ∂ x \frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}} ∂x∂sθ(x):
∂ s θ ( x ) ∂ x = ( ∂ s θ 1 ( x ) ∂ x 1 ⋯ ∂ s θ 1 ( x ) ∂ x N ⋮ ⋱ ⋮ ∂ s θ N ( x ) ∂ x 1 ⋯ ∂ s θ N ( x ) ∂ x N ) \frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}} = \begin{pmatrix} \frac{\partial \mathbf{s}_{\boldsymbol{\theta_1}}(\mathbf{x})}{\partial \mathbf{x}_1} & \cdots & \frac{\partial \mathbf{s}_{\boldsymbol{\theta_1}}(\mathbf{x})}{\partial \mathbf{x}_N} \\ \vdots & \ddots & \vdots \\ \frac{\partial \mathbf{s}_{\boldsymbol{\theta_N}}(\mathbf{x})}{\partial \mathbf{x}_1} & \cdots & \frac{\partial \mathbf{s}_{\boldsymbol{\theta_N}}(\mathbf{x})}{\partial \mathbf{x}_N} \end{pmatrix} ∂x∂sθ(x)= ∂x1∂sθ1(x)⋮∂x1∂sθN(x)⋯⋱⋯∂xN∂sθ1(x)⋮∂xN∂sθN(x)
这个矩阵的迹就是所有对角元素的和:
tr ( ∂ s θ ( x ) ∂ x ) = ∑ i = 1 N ∂ s θ i ( x ) ∂ x i \operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right) = \sum_{i=1}^N \frac{\partial \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})}{\partial \mathbf{x}_i} tr(∂x∂sθ(x))=i=1∑N∂xi∂sθi(x)
倒数第二步推导中,由于 ∫ ∂ ( p data ( x ) s θ i ( x ) ) ∂ x i d x = p data ( x ) s θ i ( x ) ∣ − ∞ + ∞ = 0 \int\frac{\partial\left(p_{\text{data}}(\mathbf{x}) \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right)}{\partial \mathbf{x}_i} d \mathbf{x}=\left.p_{\text{data}}(\mathbf{x}) \mathbf{s}_{\boldsymbol{\theta_i}}(\mathbf{x})\right|_{-\infty} ^{+\infty}=0 ∫∂xi∂(pdata(x)sθi(x))dx=pdata(x)sθi(x)∣−∞+∞=0 (这里做了假设:认为 p ( ∞ ) → 0 p(\infty) \rightarrow 0 p(∞)→0 ),因此略去。
然后,将 ∫ p data ( x ) ( tr ( ∂ s θ ( x ) ∂ x ) ) d x \int p_{\text{data}}(\mathbf{x})\left(\operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right)\right) d \mathbf{x} ∫pdata(x)(tr(∂x∂sθ(x)))dx 与 1 2 ∫ p data ( x ) ∥ s θ ( x ) ∥ 2 2 d x \frac{1}{2}\int p_{\text{data}}(\mathbf{x})\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2 d \mathbf{x} 21∫pdata(x)∥sθ(x)∥22dx 合并起来,得到式(1):
∫ p data ( x ) [ 1 2 ∥ s θ ( x ) ∥ 2 2 + tr ( ∂ s θ ( x ) ∂ x ) ] d x = E p data ( x ) [ 1 2 ∥ s θ ( x ) ∥ 2 2 + tr ( ∂ s θ ( x ) ∂ x ) ] = E p data ( x ) [ tr ( ∇ x s θ ( x ) ) + 1 2 ∥ s θ ( x ) ∥ 2 2 ] \begin{aligned} & \int p_{\text{data}}(\mathbf{x})\left[\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2+ \operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right)\right] d \mathbf{x}\\ & = \mathbb{E}_{p_{\text {data }}(\mathbf{x})}\left[\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2+ \operatorname{tr}\left(\frac{\partial \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})}{\partial \mathbf{x}}\right)\right]\\ &= \mathbb{E}_{p_{\text{data}}(\mathbf{x})}\left[\operatorname{tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right)+\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2\right] \end{aligned} ∫pdata(x)[21∥sθ(x)∥22+tr(∂x∂sθ(x))]dx=Epdata (x)[21∥sθ(x)∥22+tr(∂x∂sθ(x))]=Epdata(x)[tr(∇xsθ(x))+21∥sθ(x)∥22]
去噪得分匹配 去噪得分匹配 [61] 是一种完全规避 tr ( ∇ x s θ ( x ) ) \operatorname{tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right) tr(∇xsθ(x)) 的得分匹配变体。它首先用预设的噪声分布 q σ ( x ~ ∣ x ) q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x}) qσ(x~∣x) 扰动数据点 x \mathbf{x} x,然后使用得分匹配来估计扰动后数据分布 q σ ( x ~ ) ≜ ∫ q σ ( x ~ ∣ x ) p data ( x ) d x q_\sigma(\tilde{\mathbf{x}}) \triangleq \int q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x}) p_{\text{data}}(\mathbf{x}) \mathrm{d} \mathbf{x} qσ(x~)≜∫qσ(x~∣x)pdata(x)dx 的得分。目标函数被证明等价于以下表达式:
1 2 E q σ ( x ~ ∣ x ) p data ( x ) [ ∥ s θ ( x ~ ) − ∇ x ~ log q σ ( x ~ ∣ x ) ∥ 2 2 ] . ( 2 ) \frac{1}{2} \mathbb{E}_{q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x}) p_{\text{data}}(\mathbf{x})}\left[\left\|\mathbf{s}_{\boldsymbol{\theta}}(\tilde{\mathbf{x}})-\nabla_{\tilde{\mathbf{x}}} \log q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x})\right\|_2^2\right] .\quad(2) 21Eqσ(x~∣x)pdata(x)[∥sθ(x~)−∇x~logqσ(x~∣x)∥22].(2)
如 [61] 所示,最小化方程(2)的最优得分网络(记作 s θ ∗ ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x}) sθ∗(x))几乎必然满足 s θ ∗ ( x ) = ∇ x log q σ ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x})=\nabla_{\mathbf{x}} \log q_\sigma(\mathbf{x}) sθ∗(x)=∇xlogqσ(x)。然而,只有当噪声足够小时,即 q σ ( x ) ≈ p data ( x ) q_\sigma(\mathbf{x}) \approx p_{\text{data}}(\mathbf{x}) qσ(x)≈pdata(x) 时, s θ ∗ ( x ) = ∇ x log q σ ( x ) ≈ ∇ x log p data ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x})=\nabla_{\mathbf{x}} \log q_\sigma(\mathbf{x}) \approx \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) sθ∗(x)=∇xlogqσ(x)≈∇xlogpdata(x) 才成立。
切片得分匹配 切片得分匹配 [53] 使用随机投影来近似得分匹配中的 tr ( ∇ x s θ ( x ) ) \operatorname{tr}\left(\nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right) tr(∇xsθ(x))。目标函数为
E p v E p data [ v ⊤ ∇ x s θ ( x ) v + 1 2 ∥ s θ ( x ) ∥ 2 2 ] , ( 3 ) \mathbb{E}_{p_{\mathbf{v}}} \mathbb{E}_{p_{\text{data}}}\left[\mathbf{v}^{\top} \nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) \mathbf{v}+\frac{1}{2}\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})\right\|_2^2\right],\quad(3) EpvEpdata[v⊤∇xsθ(x)v+21∥sθ(x)∥22],(3)
其中 p v p_{\mathrm{v}} pv 是简单的随机向量分布,例如多元标准正态分布。正如 [53] 所示,通过前向模式自动微分可以有效地计算 v ⊤ ∇ x s θ ( x ) v \mathbf{v}^{\top} \nabla_{\mathbf{x}} \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) \mathbf{v} v⊤∇xsθ(x)v。与去噪得分匹配估计扰动数据的得分不同,切片得分匹配为原始未扰动数据分布提供得分估计,但由于前向模式自动微分的使用,计算量大约是四倍。
2.2 Sampling with Langevin dynamics
Langevin 动力学可以仅使用得分函数 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x) 从概率密度 p ( x ) p(\mathbf{x}) p(x) 中生成样本。给定一个固定的步长 ϵ > 0 \epsilon > 0 ϵ>0,以及一个初始值 x ~ 0 ∼ π ( x ) \tilde{\mathbf{x}}_0 \sim \pi(\mathbf{x}) x~0∼π(x),其中 π \pi π 是先验分布,Langevin 方法递归地计算如下:
x ~ t = x ~ t − 1 + ϵ 2 ∇ x log p ( x ~ t − 1 ) + ϵ z t , ( 4 ) \tilde{\mathbf{x}}_t=\tilde{\mathbf{x}}_{t-1}+\frac{\epsilon}{2} \nabla_{\mathbf{x}} \log p\left(\tilde{\mathbf{x}}_{t-1}\right)+\sqrt{\epsilon} \mathbf{z}_t,\quad(4) x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt,(4)
其中 z t ∼ N ( 0 , I ) \mathbf{z}_t \sim \mathcal{N}(0, I) zt∼N(0,I)。当 ϵ → 0 \epsilon \rightarrow 0 ϵ→0 且 T → ∞ T \rightarrow \infty T→∞ 时, x ~ T \tilde{\mathbf{x}}_T x~T 的分布等于 p ( x ) p(\mathbf{x}) p(x),在某些正则性条件下,此时 x ~ T \tilde{\mathbf{x}}_T x~T 成为 p ( x ) p(\mathbf{x}) p(x) 的一个精确样本 [62]。当 ϵ > 0 \epsilon>0 ϵ>0 且 T < ∞ T<\infty T<∞ 时,需要使用 Metropolis-Hastings 更新来修正方程(4)中的误差,但在实践中通常可以忽略 [9,12,39]。在这项工作中,我们假设当 ϵ \epsilon ϵ 很小时, T T T 很大时,这个误差可以忽略不计。
注意,从方程(4)采样只需要得分函数 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x)。因此,为了从 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x) 中获取样本,我们可以先训练我们的得分网络,使得 s θ ( x ) ≈ ∇ x log p data ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) \approx \nabla_{\mathbf{x}} \log p_{\text{data}}(\mathbf{x}) sθ(x)≈∇xlogpdata(x),然后使用 Langevin 动力学与 s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x) 近似地获取样本。这就是我们基于得分的生成建模框架的关键思想。
3 Challenges of score-based generative modeling
在本节中,我们将更深入地分析基于分数的生成模型的思想。我们认为有两个主要障碍阻碍了这一思想的简单应用。
3.1 The manifold hypothesis
流形假设认为,现实世界中的数据倾向于集中在嵌入在高维空间(又称环境空间)中的低维流形上。这一假设在经验上适用于许多数据集,并已成为流形学习的基础 [3, 47]。在流形假设下,基于得分的生成模型将面临两个关键困难。首先,由于得分 ∇ x log p ( x ) \nabla_{\mathbf{x}} \log p(\mathbf{x}) ∇xlogp(x)是在环境空间中取的梯度,因此当 x 局限于低维流形时,它是不确定的。其次,得分匹配目标方程 (1) 仅当数据分布的支持是整个空间时才提供一致的得分估计量(参见 [24] 中的定理 2),而当数据位于低维流形上时将不一致。
流形假设对得分估计的负面影响可以从图 1 中清楚地看到,在此我们训练了一个 ResNet(详细信息见附录 B.1)来估计 CIFAR-10 数据的得分。为了快速训练和真实地估计数据得分,我们使用了切片得分匹配目标(方程(3))。如图 1(左图)所示,当在原始 CIFAR-10 图像上训练时,切片得分匹配损失首先减少,然后不规则地波动。相比之下,如果我们对数据进行小的高斯噪声扰动(使得扰动后的数据分布在 R D \mathbb{R}^D RD 上具有全支撑),损失曲线将收敛(右图)。请注意,对于像素值在范围 [ 0 , 1 ] [0,1] [0,1] 的图像,我们施加的高斯噪声 N ( 0 , 0.0001 ) \mathcal{N}(0,0.0001) N(0,0.0001) 非常小,几乎无法被人眼察觉。
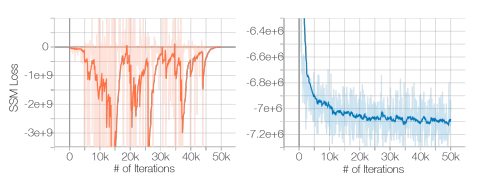
图 1:左图:相对于迭代次数的切片得分匹配 (SSM) 损失。数据中未添加任何噪声。右图:相同,但数据受到 N ( 0 , 0.0001 ) \mathcal{N}(0,0.0001) N(0,0.0001)的扰动。
3.2 Low data density regions
低密度区域的数据稀缺会给使用分数匹配进行分数估计和使用朗之万动力学进行 MCMC 采样带来困难。
3.2.1 Inaccurate score estimation with score matching
在数据密度低的区域,由于缺乏数据样本,得分匹配可能没有足够的证据来准确估计得分函数。为了说明这一点,回顾第 2.1 节中提到的,得分匹配最小化了得分估计的预期平方误差,即 1 2 E p data [ ∥ s θ ( x ) − ∇ x log p data ( x ) ∥ 2 2 ] 。 \frac{1}{2} \mathbb{E}_{p_{\text {data }}}\left[\left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x})-\nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x})\right\|_2^2\right]。 21Epdata [∥sθ(x)−∇xlogpdata (x)∥22]。 实际上,相对于数据分布的期望总是通过独立同分布样本 { x i } i = 1 N ∼ i.i.d. p data ( x ) \left\{\mathbf{x}_i\right\}_{i=1}^N \stackrel{\text { i.i.d. }}{\sim} p_{\text {data }}(\mathbf{x}) {xi}i=1N∼ i.i.d. pdata (x) 来估计。考虑任何区域 R ⊂ R D \mathcal{R} \subset \mathbb{R}^D R⊂RD,使得 p data ( R ) ≈ 0 p_{\text {data }}(\mathcal{R}) \approx 0 pdata (R)≈0。在大多数情况下, { x i } i = 1 N ∩ R = ∅ \left\{\mathbf{x}_i\right\}_{i=1}^N \cap \mathcal{R}=\varnothing {xi}i=1N∩R=∅,并且得分匹配将没有足够的数据样本来准确估计 x ∈ R \mathbf{x} \in \mathcal{R} x∈R 的 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x}) ∇xlogpdata (x)。
为了展示这一负面影响,我们在图 2 中提供了一个玩具实验的结果(详见附录 B.1),其中我们使用切片得分匹配来估计高斯混合物 p data = 1 5 N ( ( − 5 , − 5 ) , I ) + 4 5 N ( ( 5 , 5 ) , I ) p_{\text {data }}=\frac{1}{5} \mathcal{N}((-5,-5), I)+\frac{4}{5} \mathcal{N}((5,5), I) pdata =51N((−5,−5),I)+54N((5,5),I) 的得分。如图所示,得分估计仅在 p data p_{\text {data }} pdata 模式的附近区域,即数据密度高的地方是可靠的。
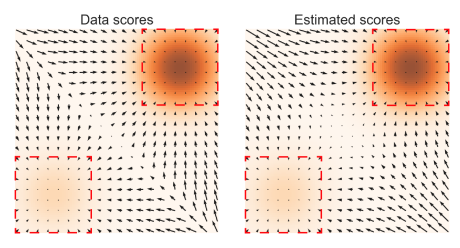
图 2:左图: ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x}) ∇xlogpdata (x);右图: s θ ( x ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) sθ(x)。数据密度 p data ( x ) p_{\text {data }}(\mathbf{x}) pdata (x) 使用橙色颜色图编码:颜色越深表示密度越高。红色矩形框突出显示了 ∇ x log p data ( x ) ≈ s θ ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x}) \approx \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}) ∇xlogpdata (x)≈sθ(x) 的区域。
3.2.2 Slow mixing of Langevin dynamics
当数据分布的两个模式被低密度区域分开时,Langevin 动力学在合理的时间内将无法正确恢复这两个模式的相对权重,因此可能无法收敛到真实分布。我们对此的分析主要受到 [63] 的启发,该文在使用得分匹配进行密度估计的背景下分析了相同的现象。
考虑一个混合分布 p data ( x ) = π p 1 ( x ) + ( 1 − π ) p 2 ( x ) p_{\text {data }}(\mathbf{x})=\pi p_1(\mathbf{x})+(1-\pi) p_2(\mathbf{x}) pdata (x)=πp1(x)+(1−π)p2(x),其中 p 1 ( x ) p_1(\mathbf{x}) p1(x) 和 p 2 ( x ) p_2(\mathbf{x}) p2(x) 是具有不相交支撑的归一化分布, π ∈ ( 0 , 1 ) \pi \in(0,1) π∈(0,1)。在 p 1 ( x ) p_1(\mathbf{x}) p1(x) 的支撑下, ∇ x log p data ( x ) = ∇ x ( log π + log p 1 ( x ) ) = ∇ x log p 1 ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x})=\nabla_{\mathbf{x}}\left(\log \pi+\log p_1(\mathbf{x})\right)=\nabla_{\mathbf{x}} \log p_1(\mathbf{x}) ∇xlogpdata (x)=∇x(logπ+logp1(x))=∇xlogp1(x),而在 p 2 ( x ) p_2(\mathbf{x}) p2(x) 的支撑下, ∇ x log p data ( x ) = ∇ x ( log ( 1 − π ) + log p 2 ( x ) ) = ∇ x log p 2 ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x})=\nabla_{\mathbf{x}}(\log (1-\pi)+\log p_2(\mathbf{x}))=\nabla_{\mathbf{x}} \log p_2(\mathbf{x}) ∇xlogpdata (x)=∇x(log(1−π)+logp2(x))=∇xlogp2(x)。无论哪种情况,得分 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x}) ∇xlogpdata (x) 都不依赖于 π \pi π。由于 Langevin 动力学使用 ∇ x log p data ( x ) \nabla_{\mathbf{x}} \log p_{\text {data }}(\mathbf{x}) ∇xlogpdata (x) 从 p data ( x ) p_{\text {data }}(\mathbf{x}) pdata (x) 中采样,因此获得的样本将不依赖于 π \pi π。在实践中,当不同模式具有近似不相交的支撑时,这一分析仍然成立——它们可能共享相同的支撑,但通过小数据密度的区域连接。在这种情况下,Langevin 动力学理论上可以生成正确的样本,但可能需要非常小的步长和非常大量的步数来混合。
为了验证这一分析,我们测试了在相同的高斯混合物上使用 Langevin 动力学进行采样的效果,并在图 3 中提供了结果。我们在使用 Langevin 动力学采样时使用了真实的得分。比较图 3(b) 和 (a),显然 Langevin 动力学生成的样本在两个模式之间具有不正确的相对密度,这与我们的分析预测一致。
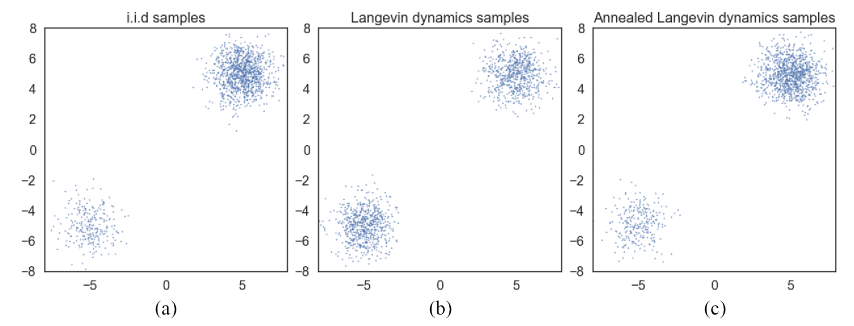
图 3:使用不同方法从高斯混合中采样。(a)精确采样。(b)使用具有精确分数的朗之万动力学进行采样。(c)使用具有精确分数的退火朗之万动力学进行采样。显然,朗之万动力学错误地估计了两种模式之间的相对权重,而退火朗之万动力学则忠实地恢复了相对权重。
4 Noise Conditional Score Networks: learning and inference
我们观察到,用随机高斯噪声扰动数据会使数据分布更适合基于分数的生成建模。首先,由于我们的高斯噪声分布的支持是整个空间,因此扰动数据不会局限于低维流形,这消除了流形假设带来的困难,并使得分估计定义明确。
其次,大高斯噪声具有填充原始未扰动数据分布中低密度区域的效果;因此得分匹配可能会获得更多的训练信号以改进分数估计。
此外,通过使用多个噪声级别,我们可以获得一系列收敛到真实数据分布的噪声扰动分布。我们可以利用这些中间分布,按照模拟退火 [30] 和退火重要性抽样 [37] 的思路,提高朗之万动力学在多峰分布上的混合率。
基于这一直觉,我们建议通过以下方式改进基于分数的生成模型:1)使用不同级别的噪声扰动数据;2)通过训练单个条件分数网络同时估计与所有噪声级别相对应的分数。训练后,在使用朗之万动力学生成样本时,我们最初使用与大噪声相对应的分数,然后逐渐降低噪声级别。这有助于将大噪声级别的好处平稳地转移到低噪声级别,其中扰动数据与原始数据几乎无法区分。接下来,我们将详细阐述我们的方法,包括分数网络的架构、训练目标和朗之万动力学的退火计划。
4.1 Noise Conditional Score Networks
设 { σ i } i = 1 L \left\{\sigma_i\right\}_{i=1}^L {σi}i=1L 为一个满足 σ 1 σ 2 = ⋯ = σ L − 1 σ L > 1 \frac{\sigma_1}{\sigma_2}=\cdots=\frac{\sigma_{L-1}}{\sigma_L}>1 σ2σ1=⋯=σLσL−1>1 的正几何数列。令 q σ ( x ) ≜ ∫ p data ( t ) N ( x ∣ t , σ 2 I ) d t q_\sigma(\mathbf{x}) \triangleq \int p_{\text {data }}(\mathbf{t}) \mathcal{N}\left(\mathbf{x} \mid \mathbf{t}, \sigma^2 I\right) \mathrm{d} \mathbf{t} qσ(x)≜∫pdata (t)N(x∣t,σ2I)dt 表示扰动数据分布。我们选择噪声级别 { σ i } i = 1 L \left\{\sigma_i\right\}_{i=1}^L {σi}i=1L,使得 σ 1 \sigma_1 σ1 足够大以缓解第 3 节中讨论的困难, σ L \sigma_L σL 足够小以最小化对数据的影响。我们的目标是训练一个条件得分网络,以联合估计所有扰动数据分布的得分,即 ∀ σ ∈ { σ i } i = 1 L : s θ ( x , σ ) ≈ ∇ x log q σ ( x ) \forall \sigma \in\left\{\sigma_i\right\}_{i=1}^L: \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) \approx \nabla_{\mathbf{x}} \log q_\sigma(\mathbf{x}) ∀σ∈{σi}i=1L:sθ(x,σ)≈∇xlogqσ(x)。注意,当 x ∈ R D \mathbf{x} \in \mathbb{R}^D x∈RD 时, s θ ( x , σ ) ∈ R D \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) \in \mathbb{R}^D sθ(x,σ)∈RD。我们称 s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 为噪声条件得分网络(Noise Conditional Score Network, NCSN)。
类似于基于似然的生成模型和 GANs,模型架构的设计在生成高质量样本中起着重要作用。在这项工作中,我们主要关注对图像生成有用的架构,并将其他领域的架构设计留作未来的工作。由于我们的噪声条件得分网络 s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 的输出与输入图像 x \mathbf{x} x 具有相同的形状,我们借鉴了用于图像密集预测(例如语义分割)的成功模型架构。在实验中,我们的模型 s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 结合了 U-Net [46] 的架构设计和扩张/空洞卷积 [64, 65, 8],这两者在语义分割中都被证明非常成功。此外,我们在得分网络中采用了实例归一化,受到其在某些图像生成任务中卓越表现的启发 [ 57 , 13 , 23 ] [57,13,23] [57,13,23],并使用了条件实例归一化 [13] 的修改版本来提供对 σ i \sigma_i σi 的条件支持。有关我们架构的更多细节可以在附录 A 中找到。
4.2 Learning NCSNs via score matching
切片得分匹配和去噪得分匹配都可以训练 NCSNs。我们采用去噪得分匹配,因为它稍快且自然适合估计噪声扰动数据分布的得分任务。然而,我们强调,经验上切片得分匹配可以和去噪得分匹配一样好地训练 NCSNs。我们选择噪声分布为 q σ ( x ~ ∣ x ) = N ( x ~ ∣ x , σ 2 I ) q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x})=\mathcal{N}\left(\tilde{\mathbf{x}} \mid \mathbf{x}, \sigma^2 I\right) qσ(x~∣x)=N(x~∣x,σ2I);因此 ∇ x ~ log q σ ( x ~ ∣ x ) = − ( x ~ − x ) / σ 2 \nabla_{\tilde{\mathbf{x}}} \log q_\sigma(\tilde{\mathbf{x}} \mid \mathbf{x})=-(\tilde{\mathbf{x}}-\mathbf{x}) / \sigma^2 ∇x~logqσ(x~∣x)=−(x~−x)/σ2。对于给定的 σ \sigma σ,去噪得分匹配目标(公式 (2))为
ℓ ( θ ; σ ) ≜ 1 2 E p data ( x ) E x ~ ∼ N ( x , σ 2 I ) [ ∥ s θ ( x ~ , σ ) + x ~ − x σ 2 ∥ 2 2 ] . ( 5 ) \ell(\boldsymbol{\theta} ; \sigma) \triangleq \frac{1}{2} \mathbb{E}_{p_{\text {data }}(\mathbf{x})} \mathbb{E}_{\tilde{\mathbf{x}} \sim \mathcal{N}\left(\mathbf{x}, \sigma^2 I\right)}\left[\left\|\mathbf{s}_{\boldsymbol{\theta}}(\tilde{\mathbf{x}}, \sigma)+\frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma^2}\right\|_2^2\right] .\quad(5) ℓ(θ;σ)≜21Epdata (x)Ex~∼N(x,σ2I)[ sθ(x~,σ)+σ2x~−x 22].(5)
然后,我们将公式 (5) 对所有 σ ∈ { σ i } i = 1 L \sigma \in\left\{\sigma_i\right\}_{i=1}^L σ∈{σi}i=1L 进行组合,得到一个统一的目标
L ( θ ; { σ i } i = 1 L ) ≜ 1 L ∑ i = 1 L λ ( σ i ) ℓ ( θ ; σ i ) , ( 6 ) \mathcal{L}\left(\boldsymbol{\theta} ;\left\{\sigma_i\right\}_{i=1}^L\right) \triangleq \frac{1}{L} \sum_{i=1}^L \lambda\left(\sigma_i\right) \ell\left(\boldsymbol{\theta} ; \sigma_i\right),\quad(6) L(θ;{σi}i=1L)≜L1i=1∑Lλ(σi)ℓ(θ;σi),(6)
其中 λ ( σ i ) > 0 \lambda\left(\sigma_i\right)>0 λ(σi)>0 是一个依赖于 σ i \sigma_i σi 的系数函数。假设 s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 具有足够的容量,当且仅当 s θ ∗ ( x , σ i ) = ∇ x log q σ i ( x ) \mathbf{s}_{\boldsymbol{\theta}^*}\left(\mathbf{x}, \sigma_i\right)=\nabla_{\mathbf{x}} \log q_{\sigma_i}(\mathbf{x}) sθ∗(x,σi)=∇xlogqσi(x) 几乎肯定地对所有 i ∈ { 1 , 2 , ⋯ , L } i \in\{1,2, \cdots, L\} i∈{1,2,⋯,L} 成立时, s θ ∗ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}^*}(\mathbf{x}, \sigma) sθ∗(x,σ) 最小化公式 (6),因为公式 (6) 是 L L L 个去噪得分匹配目标的圆锥组合。
λ ( ⋅ ) \lambda(\cdot) λ(⋅) 有许多可能的选择。理想情况下,我们希望所有 { σ i } i = 1 L \left\{\sigma_i\right\}_{i=1}^L {σi}i=1L 的 λ ( σ i ) ℓ ( θ ; σ i ) \lambda\left(\sigma_i\right) \ell\left(\boldsymbol{\theta} ; \sigma_i\right) λ(σi)ℓ(θ;σi) 的值大致在同一数量级上。经验上,我们观察到,当得分网络被训练到最优时,我们大约有 ∥ s θ ( x , σ ) ∥ 2 ∝ 1 / σ \left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma)\right\|_2 \propto 1 / \sigma ∥sθ(x,σ)∥2∝1/σ。这启发我们选择 λ ( σ ) = σ 2 \lambda(\sigma)=\sigma^2 λ(σ)=σ2。因为在这种选择下,我们有 λ ( σ ) ℓ ( θ ; σ ) = σ 2 ℓ ( θ ; σ ) = \lambda(\sigma) \ell(\boldsymbol{\theta} ; \sigma)=\sigma^2 \ell(\boldsymbol{\theta} ; \sigma)= λ(σ)ℓ(θ;σ)=σ2ℓ(θ;σ)= 1 2 E [ ∥ σ s θ ( x ~ , σ ) + x ~ − x σ ∥ 2 2 ] \frac{1}{2} \mathbb{E}\left[\left\|\sigma \mathbf{s}_{\boldsymbol{\theta}}(\tilde{\mathbf{x}}, \sigma)+\frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma}\right\|_2^2\right] 21E[ σsθ(x~,σ)+σx~−x 22]。由于 x ~ − x σ ∼ N ( 0 , I ) \frac{\tilde{\mathbf{x}}-\mathbf{x}}{\sigma} \sim \mathcal{N}(0, I) σx~−x∼N(0,I) 并且 ∥ σ s θ ( x , σ ) ∥ 2 ∝ 1 \left\|\sigma \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma)\right\|_2 \propto 1 ∥σsθ(x,σ)∥2∝1,我们可以轻松得出 λ ( σ ) ℓ ( ℓ ; σ ) \lambda(\sigma) \ell(\boldsymbol{\ell} ; \sigma) λ(σ)ℓ(ℓ;σ) 的数量级不依赖于 σ \sigma σ。
我们强调,我们的目标公式 (6) 不需要对抗训练、不需要代理损失,也不需要在训练期间从得分网络中进行采样(例如,不像对比散度)。此外,它不需要 s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 具有特殊架构以使其易于处理。另外,当 λ ( ⋅ ) \lambda(\cdot) λ(⋅) 和 { σ i } i = 1 L \left\{\sigma_i\right\}_{i=1}^L {σi}i=1L 固定时,它可以用于定量比较不同的 NCSNs。
4.3 NCSN inference via annealed Langevin dynamics
在训练完 NCSN s θ ( x , σ ) \mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma) sθ(x,σ) 之后,我们提出了一种采样方法——退火朗之万动力学(算法 1),该方法受模拟退火 [30] 和退火重要性采样 [37] 的启发。如算法 1 所示,我们通过从某个固定的先验分布(例如,均匀噪声)初始化样本来开始退火朗之万动力学。然后,我们运行朗之万动力学以步长 α 1 \alpha_1 α1 从 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 中采样。接下来,我们运行朗之万动力学以步长 α 2 \alpha_2 α2 从 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 中采样,起点是前一次模拟的最终样本。我们以这种方式继续,使用 q σ i − 1 ( x ) q_{\sigma_{i-1}}(\mathbf{x}) qσi−1(x) 的最终样本来从 q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 中采样,当 σ L ≈ 0 \sigma_L \approx 0 σL≈0 时, q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 接近 p data ( x ) p_{\text{data}}(\mathbf{x}) pdata(x)。
由于分布 { q σ i } i = 1 L \left\{q_{\sigma_i}\right\}_{i=1}^L {qσi}i=1L 都被高斯噪声扰动过,其支持集遍布整个空间,且它们的分数是良好定义的,避免了流形假设带来的困难。当 σ 1 \sigma_1 σ1 足够大时, q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的低密度区域变得较小,模式变得不那么孤立。如前所述,这可以提高得分估计的准确性,并加快朗之万动力学的混合。因此,我们可以假设朗之万动力学为 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 产生了良好的样本。这些样本可能来自 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的高密度区域,这意味着它们也可能位于 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 的高密度区域,因为 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 和 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 彼此只有很小的差异。由于得分估计和朗之万动力学在高密度区域表现较好,因此 q σ 1 ( x ) q_{\sigma_1}(\mathbf{x}) qσ1(x) 的样本将作为 q σ 2 ( x ) q_{\sigma_2}(\mathbf{x}) qσ2(x) 的朗之万动力学的良好初始样本。同样, q σ i − 1 ( x ) q_{\sigma_{i-1}}(\mathbf{x}) qσi−1(x) 为 q σ i ( x ) q_{\sigma_i}(\mathbf{x}) qσi(x) 提供了良好的初始样本,最终我们从 q σ L ( x ) q_{\sigma_L}(\mathbf{x}) qσL(x) 中获得了高质量的样本。

在算法 1 中,可能有很多方法可以根据 σ i \sigma_i σi 调整 α i \alpha_i αi。我们的选择是 α i ∝ σ i 2 \alpha_i \propto \sigma_i^2 αi∝σi2。这样做的动机是固定朗之万动力学中“信噪比” α i s θ ( x , σ i ) 2 α i z \frac{\alpha_i \mathbf{s}_\theta\left(\mathbf{x}, \sigma_i\right)}{2 \sqrt{\alpha_i} \mathbf{z}} 2αizαisθ(x,σi) 的量级。注意, E [ ∥ α i s θ ( x , σ i ) 2 α i z ∥ 2 2 ] ≈ E [ α i ∥ s θ ( x , σ i ) ∥ 2 2 4 ] ∝ 1 4 E [ ∥ σ i s θ ( x , σ i ) ∥ 2 2 ] \mathbb{E}\left[\left\|\frac{\alpha_i \mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)}{2 \sqrt{\alpha_i} \mathbf{z}}\right\|_2^2\right] \approx \mathbb{E}\left[\frac{\alpha_i\left\|\mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)\right\|_2^2}{4}\right] \propto \frac{1}{4} \mathbb{E}\left[\left\|\sigma_i \mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)\right\|_2^2\right] E[ 2αizαisθ(x,σi) 22]≈E[4αi∥sθ(x,σi)∥22]∝41E[∥σisθ(x,σi)∥22]。回想一下,经验上我们发现当得分网络接近最优训练时, ∥ s θ ( x , σ ) ∥ 2 ∝ 1 / σ \left\|\mathbf{s}_{\boldsymbol{\theta}}(\mathbf{x}, \sigma)\right\|_2 \propto 1 / \sigma ∥sθ(x,σ)∥2∝1/σ,在这种情况下, E [ ∥ σ i s θ ( x , σ i ) ∥ 2 2 ] ∝ 1 \mathbb{E}\left[\left\|\sigma_i \mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)\right\|_2^2\right] \propto 1 E[∥σisθ(x,σi)∥22]∝1。因此, ∥ α i s θ ( x , σ i ) 2 α i z ∥ 2 ∝ 1 4 E [ ∥ σ i s θ ( x , σ i ) ∥ 2 2 ] ∝ 1 4 \left\|\frac{\alpha_i \mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)}{2 \sqrt{\alpha_i} \mathbf{z}}\right\|_2 \propto \frac{1}{4} \mathbb{E}\left[\left\|\sigma_i \mathbf{s}_{\boldsymbol{\theta}}\left(\mathbf{x}, \sigma_i\right)\right\|_2^2\right] \propto \frac{1}{4} 2αizαisθ(x,σi) 2∝41E[∥σisθ(x,σi)∥22]∝41 不依赖于 σ i \sigma_i σi。
为了证明退火朗之万动力学的有效性,我们提供了一个玩具示例,目标是仅使用得分从两个分离模式的高斯混合物中采样。我们应用算法 1 来从第 3.2 节中使用的高斯混合物中采样。在实验中,我们选择 { σ i } i = 1 L \left\{\sigma_i\right\}_{i=1}^L {σi}i=1L 为几何级数,其中 L = 10 , σ 1 = 10 L=10, \sigma_1=10 L=10,σ1=10 和 σ 10 = 0.1 \sigma_{10}=0.1 σ10=0.1。结果见图 3。将图 3 (b) 与 © 进行比较,退火朗之万动力学正确恢复了两个模式之间的相对权重,而标准朗之万动力学则失败了。