一.参考
zookeeper启动和选举的源码分析参考之前的帖子.
二.源码
1.职责链模式.
每次经过的processor都是异步处理,加入当前processor的队列,然后新的线程从队列里面取出数据处理.
PrepRequestProcessor 检查ACL权限,创建ChangeRecord.
SyncRequestProcessor 负责事务日志的持久化,写入snapshot和log文件.
FinalRequestProcessor 提交leader事务.向observer发送请求,提交事务.
1.1如果是leader启动的时候会倒序初始化下面6个processor,
LeaderRequestProcessor->PrepRequestProcessor->ProposalRequestProcessor(含有SyncRequestProcessor的成员变量,processRequest中先调用下一个,再调用SyncRequestProcessor)->CommitProcessor->ToBeAppliedRequestProcessor->FinalRequestProcessor.
protected void setupRequestProcessors() {RequestProcessor finalProcessor = new FinalRequestProcessor(this);RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());commitProcessor = new CommitProcessor(toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener());commitProcessor.start();ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor);proposalProcessor.initialize();prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);prepRequestProcessor.start();firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);setupContainerManager();
}1.2.如果是follower启动,会进入ZooKeeperServer#startupWithServerState倒序初始化下面三个processor,
FollowerRequestProcessor->CommitProcessor->FinalRequestProcessor.
另外两个,是在Follower的主循环中,接收到PROPOSAL请求时,会依次调用SyncRequestProcessor->SendAckRequestProcessor,在下面二.2中有详细分析.
protected void setupRequestProcessors() {RequestProcessor finalProcessor = new FinalRequestProcessor(this);commitProcessor = new CommitProcessor(finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener());commitProcessor.start();firstProcessor = new FollowerRequestProcessor(this, commitProcessor);((FollowerRequestProcessor) firstProcessor).start();syncProcessor = new SyncRequestProcessor(this, new SendAckRequestProcessor(getFollower()));syncProcessor.start();}2.处理网络请求
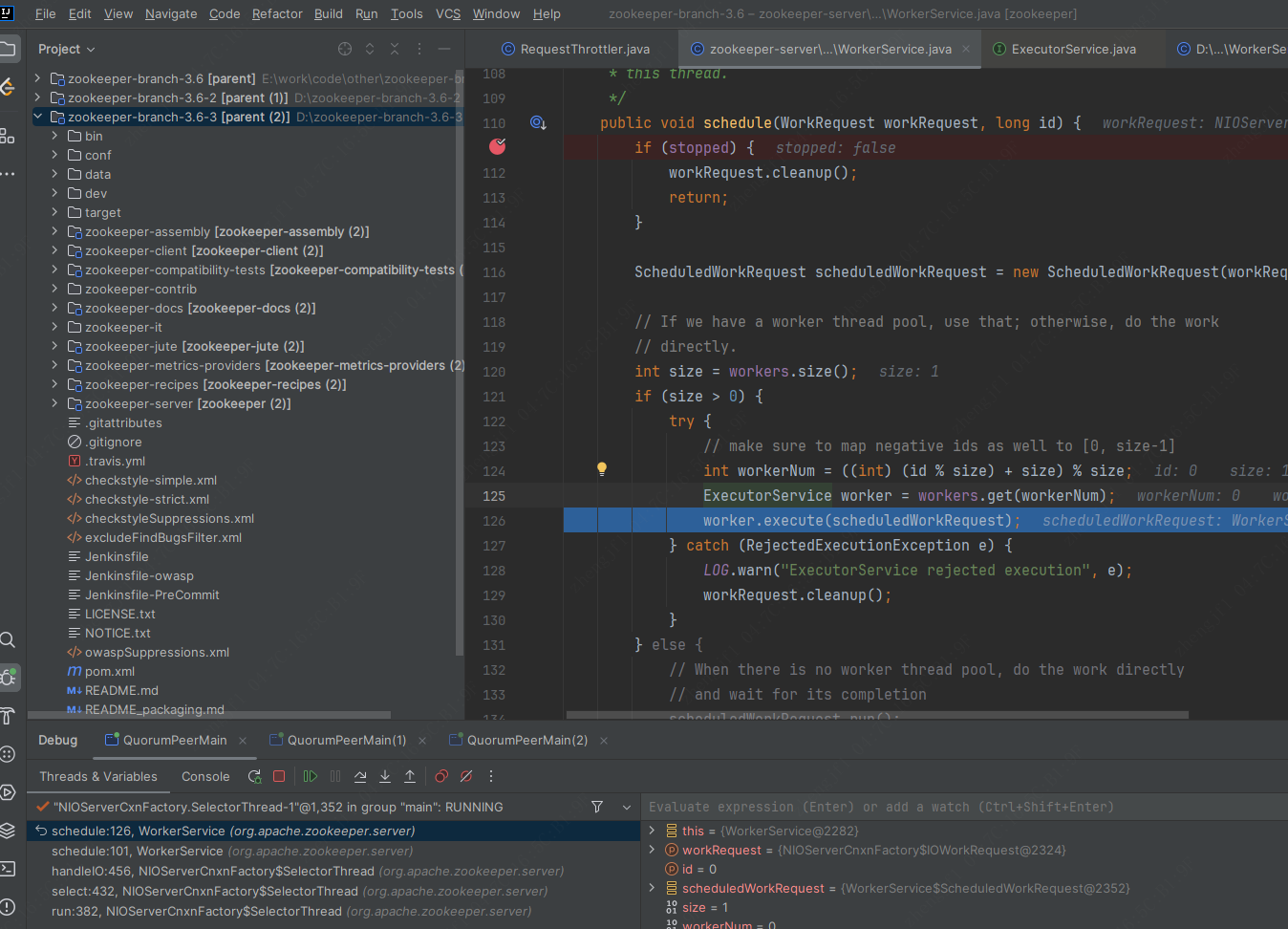
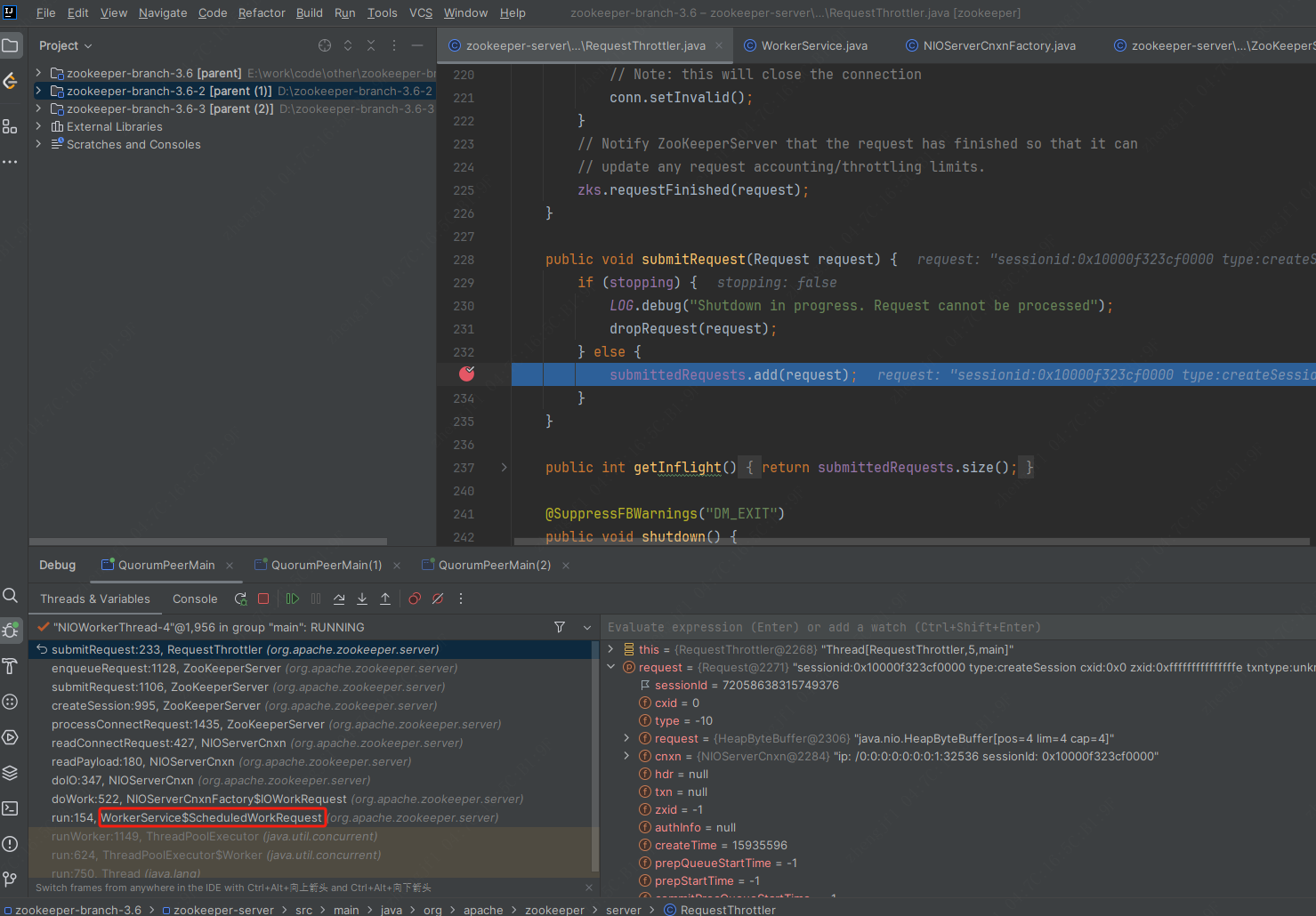
如果是follower,栈如下图所示,进入NIOServerCnxnFactory.SelectorThread#run,提交到RequestThrottler#submittedRequests队列里面,开始职责链处理.
3.ceate命令栈
发起creat /test2命令时,如果是leader,栈如下图所示:
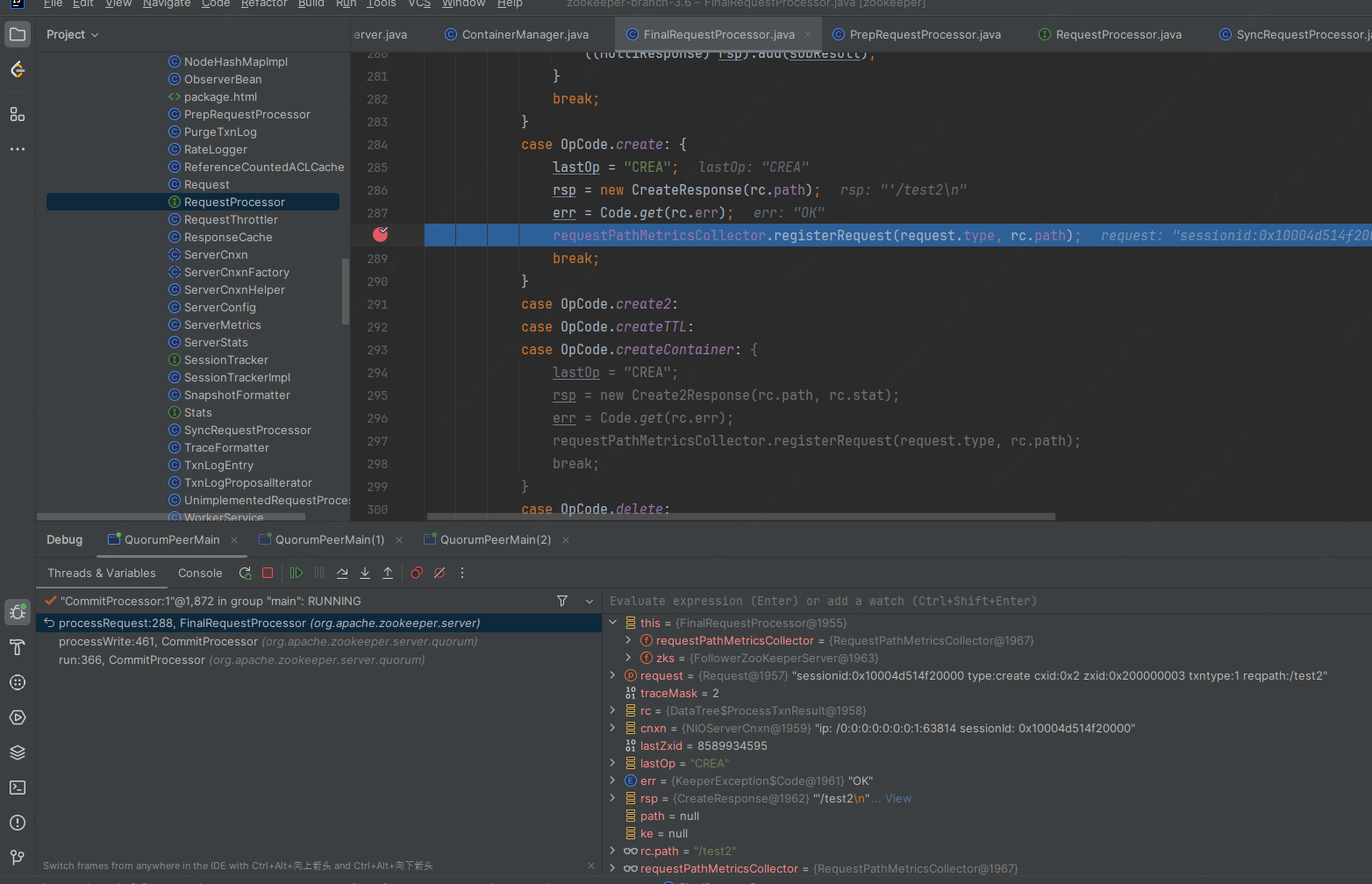
如果是follower角色,栈如下所示:
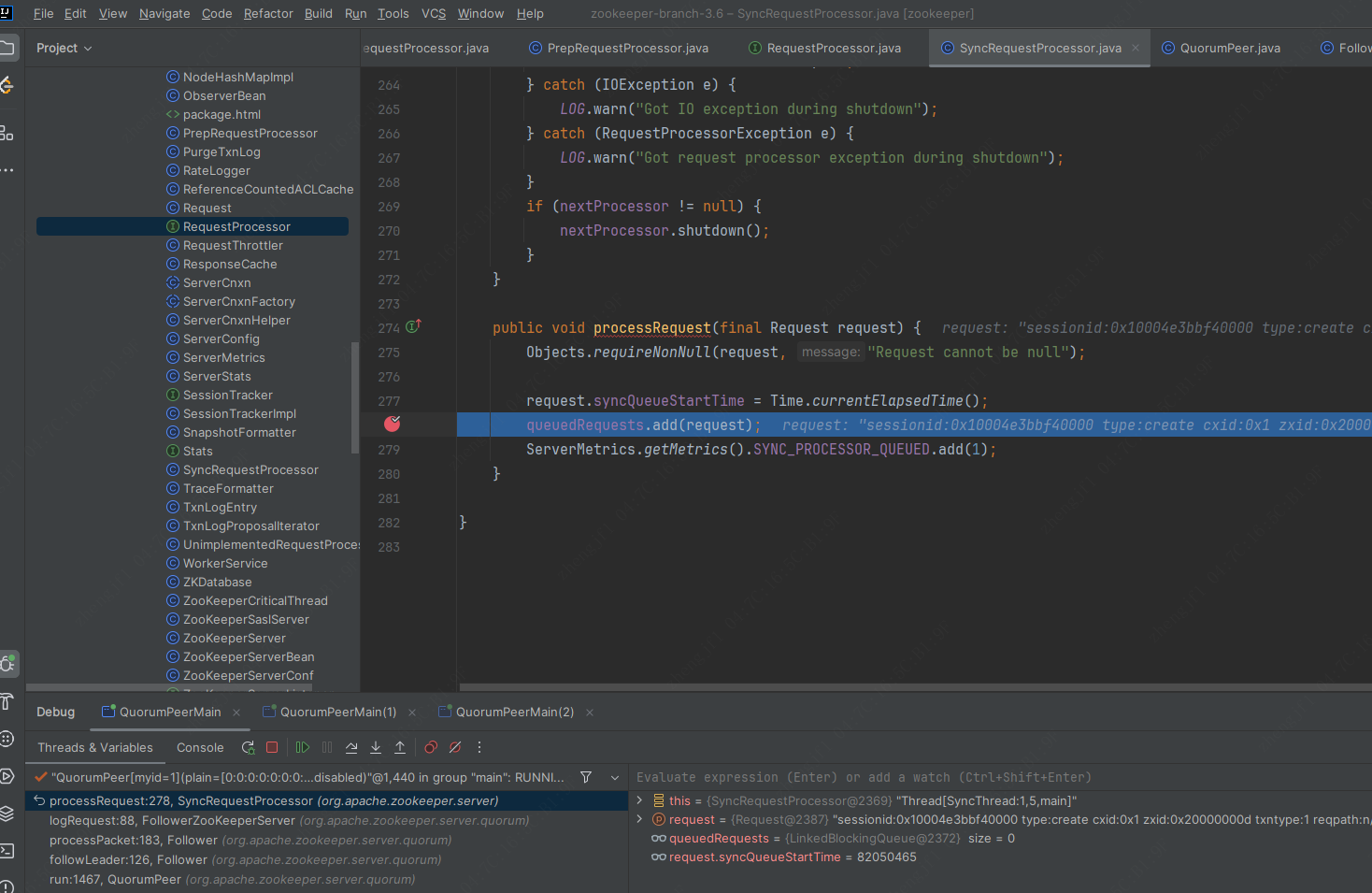
4.主循环处理create
如果是follower,进入QuorumPeer#run方法,这个是follower角色的死循环主方法,进入Follower#followLeader方法,代码如下:
void followLeader() throws InterruptedException {//xxxtry {self.setZabState(QuorumPeer.ZabState.DISCOVERY);//启动过程中,读取的选票中获取leader.QuorumServer leaderServer = findLeader();try {//连接leaderconnectToLeader(leaderServer.addr, leaderServer.hostname);connectionTime = System.currentTimeMillis();//向leader中注册自己follower的存在long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);if (self.isReconfigStateChange()) {throw new Exception("learned about role change");}//check to see if the leader zxid is lower than ours//this should never happen but is just a safety check//leader 代数比自己小,抛异常,正常不会这样.long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);if (newEpoch < self.getAcceptedEpoch()) {LOG.error("Proposed leader epoch "+ ZxidUtils.zxidToString(newEpochZxid)+ " is less than our accepted epoch "+ ZxidUtils.zxidToString(self.getAcceptedEpoch()));throw new IOException("Error: Epoch of leader is lower");}long startTime = Time.currentElapsedTime();try {self.setLeaderAddressAndId(leaderServer.addr, leaderServer.getId());self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);//向leader同步数据,主要是拉取leader比较新的事务日志syncWithLeader(newEpochZxid);self.setZabState(QuorumPeer.ZabState.BROADCAST);completedSync = true;} finally {long syncTime = Time.currentElapsedTime() - startTime;ServerMetrics.getMetrics().FOLLOWER_SYNC_TIME.add(syncTime);}if (self.getObserverMasterPort() > 0) {LOG.info("Starting ObserverMaster");om = new ObserverMaster(self, fzk, self.getObserverMasterPort());om.start();} else {om = null;}// create a reusable packet to reduce gc impactQuorumPacket qp = new QuorumPacket();while (this.isRunning()) {readPacket(qp);//处理客户端请求,在后面2处分析processPacket(qp);}} catch (Exception e) {LOG.warn("Exception when following the leader", e);closeSocket();// clear pending revalidationspendingRevalidations.clear();}} finally {//xxx}}5.进入职责链
依次进入Follower#processPacket(case Leader.PROPOSAL)->FollowerZooKeeperServer#logRequest(类中有SyncRequestProcessor成员引用)->SyncRequestProcessor#processRequest方法,加入到SyncRequestProcessor#queuedRequests队列里面.代码如下.
protected void processPacket(QuorumPacket qp) throws Exception {switch (qp.getType()) {case Leader.PING:ping(qp);break;case Leader.PROPOSAL://提案处理//xxxfzk.logRequest(hdr, txn, digest);//xxx//xxx}
}public void logRequest(TxnHeader hdr, Record txn, TxnDigest digest) {Request request = new Request(hdr.getClientId(), hdr.getCxid(), hdr.getType(), hdr, txn, hdr.getZxid());request.setTxnDigest(digest);if ((request.zxid & 0xffffffffL) != 0) {pendingTxns.add(request);}syncProcessor.processRequest(request);
}
6.SyncRequestProcessor队列处理
进入新线程的方法SyncRequestProcessor#run.代码如下所示:
public void run() {try {// we do this in an attempt to ensure that not all of the servers// in the ensemble take a snapshot at the same timeresetSnapshotStats();lastFlushTime = Time.currentElapsedTime();while (true) {ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_SIZE.add(queuedRequests.size());long pollTime = Math.min(zks.getMaxWriteQueuePollTime(), getRemainingDelay());//从队列取出请求Request si = queuedRequests.poll(pollTime, TimeUnit.MILLISECONDS);if (si == null) {/* We timed out looking for more writes to batch, go ahead and flush immediately */flush();si = queuedRequests.take();}if (si == REQUEST_OF_DEATH) {break;}long startProcessTime = Time.currentElapsedTime();ServerMetrics.getMetrics().SYNC_PROCESSOR_QUEUE_TIME.add(startProcessTime - si.syncQueueStartTime);// track the number of records written to the log//写请求添加到DataTree数据库内,写日志文件,如下面4代码.if (zks.getZKDatabase().append(si)) {//判断是否需要重新建立快照if (shouldSnapshot()) {resetSnapshotStats();// roll the logzks.getZKDatabase().rollLog();// take a snapshotif (!snapThreadMutex.tryAcquire()) {LOG.warn("Too busy to snap, skipping");} else {new ZooKeeperThread("Snapshot Thread") {public void run() {try {//启动新线程,创建新的快照.见下面代码5zks.takeSnapshot();} catch (Exception e) {LOG.warn("Unexpected exception", e);} finally {snapThreadMutex.release();}}}.start();}}} else if (toFlush.isEmpty()) {// optimization for read heavy workloads// iff this is a read, and there are no pending// flushes (writes), then just pass this to the next// processorif (nextProcessor != null) {nextProcessor.processRequest(si);if (nextProcessor instanceof Flushable) {((Flushable) nextProcessor).flush();}}continue;}toFlush.add(si);if (shouldFlush()) {flush();}ServerMetrics.getMetrics().SYNC_PROCESS_TIME.add(Time.currentElapsedTime() - startProcessTime);}} catch (Throwable t) {handleException(this.getName(), t);}LOG.info("SyncRequestProcessor exited!");}7.写事务日志
进入FileTxnLog#append()写事务日志到文件,如下代码.
public synchronized boolean append(TxnHeader hdr, Record txn, TxnDigest digest) throws IOException {if (hdr == null) {return false;}if (hdr.getZxid() <= lastZxidSeen) {LOG.warn("Current zxid {} is <= {} for {}",hdr.getZxid(),lastZxidSeen,hdr.getType());} else {lastZxidSeen = hdr.getZxid();}if (logStream == null) {LOG.info("Creating new log file: {}", Util.makeLogName(hdr.getZxid()));//创建日志文件log-xxxlogFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));fos = new FileOutputStream(logFileWrite);logStream = new BufferedOutputStream(fos);oa = BinaryOutputArchive.getArchive(logStream);FileHeader fhdr = new FileHeader(TXNLOG_MAGIC, VERSION, dbId);fhdr.serialize(oa, "fileheader");// Make sure that the magic number is written before padding.logStream.flush();filePadding.setCurrentSize(fos.getChannel().position());streamsToFlush.add(fos);}filePadding.padFile(fos.getChannel());//事务写到buf内.byte[] buf = Util.marshallTxnEntry(hdr, txn, digest);if (buf == null || buf.length == 0) {throw new IOException("Faulty serialization for header " + "and txn");}Checksum crc = makeChecksumAlgorithm();//buf写到crc内,写到文件crc.update(buf, 0, buf.length);oa.writeLong(crc.getValue(), "txnEntryCRC");Util.writeTxnBytes(oa, buf);return true;}8.写事务日志文件
建立事务日志的快照,从上面的3过来.依次进入ZooKeeperServer#takeSnapshot()->FileTxnSnapLog#save(创建snapshot文件)->FileSnap#serialize()->SerializeUtils#serializeSnapshot->DataTree#serialize->DataTree#serializeNode.主要是向文件流中写入各种数据。



![[Python学习日记-10] Python中的流程控制(if...else...)](https://i-blog.csdnimg.cn/direct/b727f55d79c04d69ba25bf2740b58d8c.png)