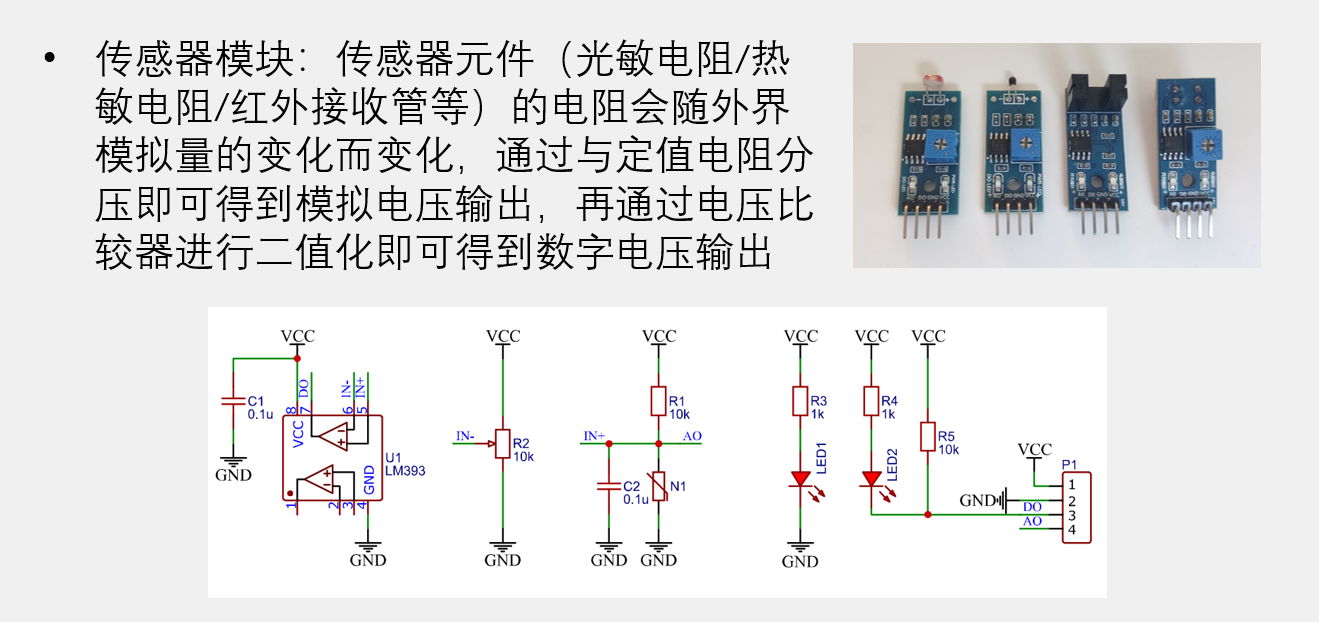
引言
在自然语言处理(NLP)中,Transformer模型自2017年提出以来,已成为许多任务的基础架构,包括机器翻译、文本摘要和问答系统等。Transformer模型的核心之一是其处理序列数据的能力,而Position Embedding在其中扮演了关键角色。

什么是Position Embedding
在处理序列数据时,模型需要理解单词在句子中的位置信息。不同于循环神经网络(RNN)或长短期记忆网络(LSTM)能够自然捕捉序列中的顺序信息,Transformer模型是一个基于自注意力(Self-Attention)的架构,它本身不具备捕捉序列顺序的能力。因此,Position Embedding被引入以提供这种顺序信息。
Position Embedding的实现
Position Embedding通常通过以下方式实现:
-
定义位置向量:为序列中的每个位置(position)定义一个唯一的向量。这些向量可以是随机初始化的,也可以是通过某种方式学习得到的。
-
位置编码:将每个位置的向量与对应的单词嵌入(Word Embedding)相加,以此来编码位置信息。
-
训练:在模型训练过程中,位置向量会通过反向传播算法进行更新,以更好地捕捉序列中的顺序信息。

为什么使用Position Embedding
- 灵活性:Position Embedding允许模型学习到不同位置单词的相对重要性。
- 简单性:实现简单,易于集成到Transformer模型中。
- 有效性:已被证明在多种NLP任务中有效。
好,问题来了,NLP是什么??
NLP是自然语言处理(Natural Language Processing)的缩写,它是人工智能和语言学领域的一个分支,致力于使计算机能够理解、解释和生成人类语言的内容。NLP的目标是缩小人类语言和计算机之间的差距,使计算机能够执行如下任务:
- 语言理解:理解句子的结构和意义。
- 语言生成:生成流畅自然的语言响应。
- 语言翻译:将一种语言翻译成另一种语言。
- 情感分析:识别文本中的情感倾向,如积极、消极或中性。
- 文本摘要:生成文本内容的简短摘要。
- 命名实体识别:识别文本中的特定实体,如人名、地点、组织等。
- 关系提取:确定文本中实体之间的关系。
NLP技术的应用非常广泛,包括搜索引擎、推荐系统、语音助手、机器翻译、自动摘要、社交媒体监控等。随着深度学习技术的发展,NLP领域取得了显著的进展,使得机器在处理复杂语言任务方面变得更加高效和准确。
实现示例
以下是一个简单的Position Embedding实现示例,使用Python和PyTorch库:
python(这个是Transformer的位置编码功能,并不会出结果)
import torch
import torch.nn as nn
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()# 创建一个足够长的positional encoding矩阵self.positional_encoding = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))# 应用正弦和余弦函数编码不同频率的位置信息self.positional_encoding[:, 0::2] = torch.sin(position * div_term)self.positional_encoding[:, 1::2] = torch.cos(position * div_term)self.positional_encoding = self.positional_encoding.unsqueeze(0).transpose(0, 1)def forward(self, x):# 将positional encoding添加到输入的词嵌入中return x + self.positional_encoding[:x.size(0), :].detach()验证功能
import torch
import torch.nn as nn
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()# 初始化位置编码矩阵self.positional_encoding = torch.zeros(max_len, d_model)# 位置编码的计算position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))self.positional_encoding[:, 0::2] = torch.sin(position * div_term)self.positional_encoding[:, 1::2] = torch.cos(position * div_term)self.positional_encoding = self.positional_encoding.unsqueeze(0)def forward(self, x):# 将位置编码添加到输入的词嵌入中return x + self.positional_encoding[:, :x.size(1)]# 实例化位置编码层
d_model = 512 # 模型的维度
max_len = 100 # 序列的最大长度
positional_encoder = PositionalEncoding(d_model, max_len)# 创建一个随机的词嵌入矩阵,模拟实际的词嵌入
word_embeddings = torch.randn(max_len, d_model)# 应用位置编码
encoded_embeddings = positional_encoder(word_embeddings)# 打印词嵌入和位置编码的前几个值
print("Word Embeddings:")
print(word_embeddings[:5, :5]) # 打印前5个词的前5个维度的嵌入print("\nEncoded Embeddings with Positional Encoding:")
print(encoded_embeddings[:5, :5]) # 打印添加位置编码后的前5个词的前5个维度的嵌入# 如果你想要可视化整个编码的矩阵,可以使用以下代码
# import matplotlib.pyplot as plt
# plt.figure(figsize=(15, 10))
# plt.imshow(encoded_embeddings.detach().cpu().numpy(), aspect='auto')
# plt.colorbar()
# plt.xlabel('Embedding dimension')
# plt.ylabel('Position in sequence')
# plt.show()
运行结果分析
这是一段经过位置编码处理的词嵌入(Word Embeddings)的示例。
我只取了前5个维度的值,你们也可以直接打印。
词嵌入是将词汇映射到向量空间的表示方法,而位置编码则是向这些词嵌入中添加额外的维度,以表示每个词在序列中的位置。
输出结果分为两个部分:
原始词嵌入(Word Embeddings):
- 显示了5个词(或标记)的词嵌入向量。每个词由一个具有一定维度(d_model)的向量表示。这里显示了每个词向量的前5个维度的值。
添加位置编码后的嵌入(Encoded Embeddings with Positional Encoding):
- 显示了将位置编码添加到原始词嵌入后的向量。这些向量现在不仅包含了关于词本身的信息,还包含了它们在序列中的位置信息。
输出结果中的数值表示嵌入向量的各个维度的值。例如,第一个词的原始词嵌入向量在第一个维度上的值为0.3690,在添加位置编码后,该维度的值变为了0.9295(这可能是由于位置编码的影响)。

结论
Position Embedding是Transformer模型中不可或缺的一部分,它通过编码序列中单词的位置信息,使得模型能够捕捉到单词之间的顺序关系。通过简单的数学变换,Position Embedding为模型提供了一种有效的方式来处理序列数据,进而在各种NLP任务中取得优异的性能。













![[PHP]-Laravel中Group By引发的问题思考](https://i-blog.csdnimg.cn/direct/d8107743337647cc921a47e61a59f07d.jpeg#pic_center)