前言:当我们需要批量生成一些合同文件或者简历等。如果手工处理对于我们来说不仅工作量巨大,而且难免会出现一些问题。这个时候运用python处理word实现自动生成文件可极大的提高工作效率。
python-docx是python的第三方插件,用来处理word文件,自动化生成和修改word文档。下面我们一起探讨一下如何工作的:
目录
一、安装
二、新建文档对象
三、写入内容
3.1插入文本
3.2添加图片和表格
3.3样式处理
四、保存文档
五、Word转换PDF
1.单个文件的转换
2.多个文件转换
六、总结
一、安装
1.下载安装
使用之前需要先下载安装。命令行:pip install python-docx
pip install python-docx
2.导入模块
import docx一个简单的word创建过程:1.创建一个文件对象 2.添加内容 3.保存文件
下面是一个生成word文件的简单步骤:
# 导入python-docx模块
import docx
from docx import Document#1.新建文档对象
document = Document() # 创建一个空的文档对象
#Document("storeinfo.docx") #读取现有的word 建立文档对象
#2.添加内容
document.add_heading("销售门店新增通知")
#3.保存文档
document.save("shop.docx")文件运行之后可以看到生成一个shop.docx文件。
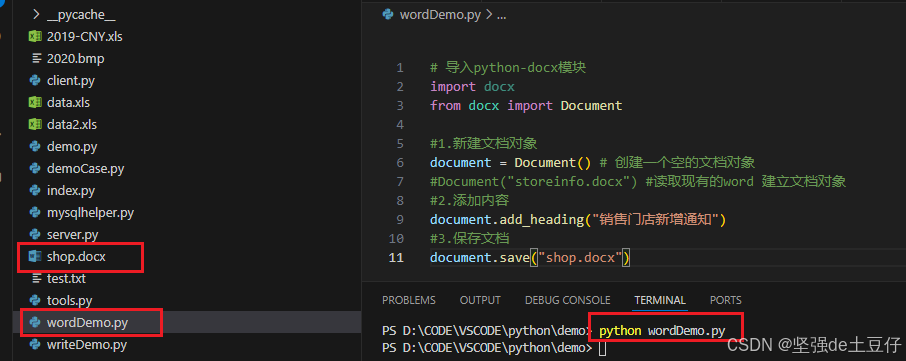

可以看到非常简单只有一个文件标题的word文件。下面我们对详细用法进一步探索。
二、新建文档对象
在这里我们直接打开用刚刚生成的word文件来修改。
#1.新建文档对象
document = Document("shop.docx") #读取现有的word 建立文档对象三、写入内容
前面我们添加的题目没有进行设置,所以默认使用一级标题显示,现在我们对添加的内容进行设置。
3.1插入文本
插入文本包括标题,段落,可以对标题进行等级设置,段落进行段落首行以及左右缩进,段落的行间距、文本的字体大小颜色字号设置,加粗、斜体、下划线常用的设置。
1)设置标题等级,首行以及左右缩进,行间距。
#2.添加内容
document.add_heading("销售门店新增通知",level=3) #设置标题是4级标题
# 插入段落
p1 = document.add_paragraph("针对市场情况有变,现在某某地区新增某某门店,请知悉。")
p1.insert_paragraph_before("补充通知:这是在刚刚的段落之前插入新的段落哦")# 段落可以设置段落属性和段落中文字属性
format = p1.paragraph_format
format.left_indent = Pt(20) #段落左侧的缩进
format.right_indent = Pt(20) # 段落右侧的缩进
format.first_line_indent = Pt(20) #首行缩进设置20镑# 行间距
format.line_spacing = 1.5 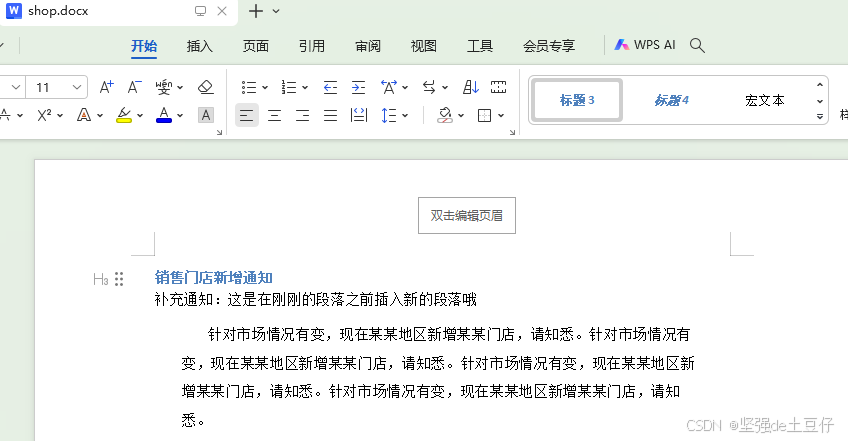
2) 字体、字号、颜色设置
记得先导入 from docx.shared import Pt,RGBColor。
# 使用段落和颜色设置需要用到
from docx.shared import Pt,RGBColor# p1 追加文本并对本文进行字体大小设置
run = p1.add_run("具体信息请咨询总部具体信息请咨询总部具体信息请咨询总部具体信息请咨询总部具体信息请咨询总部具体信息请咨询总部具体信息请咨询总部")
# 设置字体字号以及颜色
run.font.size = Pt(12)
run.font.name = '微软雅黑'
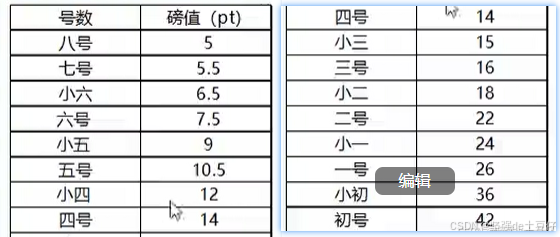
run.font.color.rgb = RGBColor(225,25,25)字号和大小对比图 如下:
3)字体加粗下划线斜体设置
# 字体加粗下划线 斜体
run1 = p1.add_run("这里是段落继续增加的文字信息")
run1.bold = True
run1.font.underline = True
run1.font.italic = True
3.2添加图片和表格
#插入图片
document.add_picture('img.jpg') #插入图片 默认大小
document.add_picture('img.jpg',Pt(50),Pt(80)) #传入参设置插入图片的大小# 插入表格
table = document.add_table(rows=1,cols=3) #设置一行三列的数据表
headerCells = table.rows[0].cells
headerCells[0].text = "月份"
headerCells[1].text = "预期产量"
headerCells[2].text = "实际产量"# 数据
data = (['一月份',100,120],['二月份',300,350],['三月份',600,500]
)for item in data:rowsCells = table.add_row().cells rowsCells[0].text = item[0]rowsCells[1].text = str(item[1])rowsCells[2].text = str(item[2])执行结果:

3.3样式处理
包括样式设置以及删除已添加样式。
# 导入文件
from docx.enum.style import WD_STYLE_TYPEstyle = document.styles.add_style('textstyle',WD_STYLE_TYPE.PARAGRAPH)
style.font.size = Pt(5)
#删除样式
#document.styles['textstyle'].delete()# 插入段落 在这里插入文本样式作为参数传递
p1 = document.add_paragraph("针对市场情况有变,现在某某地区新增某某门店,请知悉。针对市场情况有变,现在某某地区新增某某门店,请知悉。""针对市场情况有变,现在某某地区新增某某门店,请知悉。针对市场情况有变,现在某某地区新增某某门店,请知悉。" ,style='textstyle')# 插入表格 这里也是
table = document.add_table(rows=1,cols=3,style='Medium List 1') 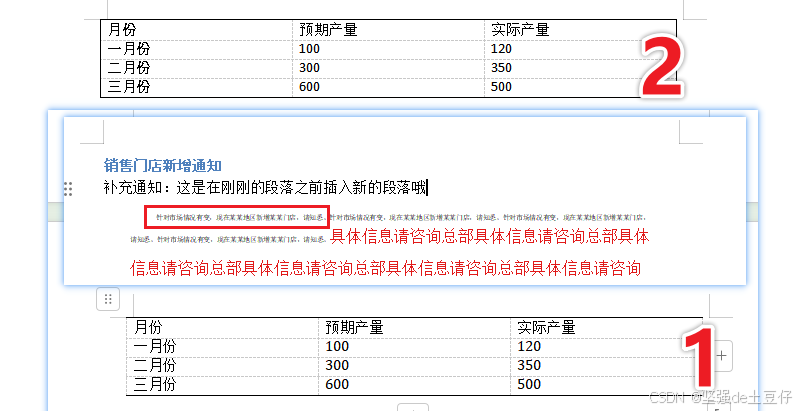
四、保存文档
#3.保存文档
document.save("shop.docx")五、Word转换PDF
安装依赖并导入
# 安装
pip install pywin32
# 导入
from win32com.client import constants,gencache
1.单个文件的转换
def createpdf(wordPath,pdfPath):word = gencache.EnsureDispatch('Word.Application')doc = word.Documents.Open(wordPath,ReadOnly=1)# 转换方法doc.ExportAsFixedFormat(pdfPath,constants.wdExportFormatPDF)word.Quit()
#单个文件的转换
createpdf('D:\CODE\VSCODE\python\demo\shop.docx','D:\CODE\VSCODE\python\demo\shop.pdf') 执行之后可以看到生成了shop.pdf文件 。
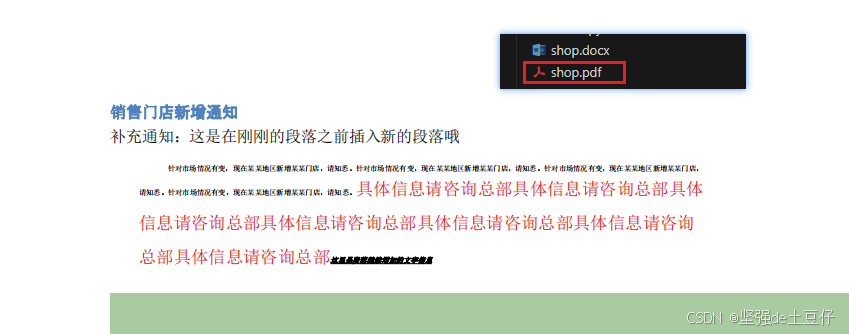
2.多个文件转换
# 对目录的操作 多文件转换pdf
import os#多个文件的转换
# print(os.listdir('.')) #当前文件夹下的所有文件#定义一个列表用来存放当前文件夹下所有的doc或者docx文件
wordfiles = []
# 遍历当前文件夹下的所有文件
for file in os.listdir('.'):if file.endswith(('doc','docx')): #如果以doc或者docx结果的都添加到wordfiles列表中wordfiles.append(file)
# print(wordfiles)
#
# 遍历doc和docx文件
for file in wordfiles:filepath = os.path.abspath(file) # 获取到当前的文件路径index = filepath.rindex('.') #找到最后一次出现‘.’的地址pdfpath = filepath[:index]+'.pdf' #filepath[:index] 获取从 filepath‘.’之前的字符 然后拼接'.pdf'# print(pdfpath) createpdf(filepath,pdfpath) # 执行转换操作执行文件之后文件夹生成了几个pdf文件。
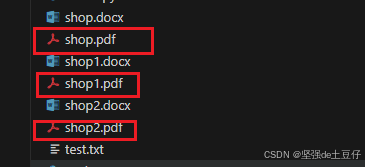
六、总结
本章主要总结了python-docx的第三方模块主要用于添加和修改word文件。
1.首先对python-docx模块进行安装并且导入依赖使用
2.模块的主要工作过程 新建文档对象 写入内容、保存文档
3.写入内容又分为写入文本、添加图片和表格
4.对添加的段落、标题以及文字进行样式设置
5.word转换pdf,单个文件和多个文件转换
有问题欢迎大家评论区留言指正,大家一起探讨学习一起进步,谢谢。
题库数据经过打乱试题和答案后生成word试卷案例



![QT 与 C++实现基于[ TCP ]的聊天室界面](https://i-blog.csdnimg.cn/direct/09f879b1b195443f8f1ff0d41fbc5919.png)













