如何选择正确的 Python 并发 API模块 ?
Python 标准库提供了三种并发 API , 如何知道你的项目应该使用哪个 API?在本教程将带逐步了解各API的特性、区别以及各自应用场景,指导你选择最合适的并发 API。
多线程、多进程,还是异步?-- Python 并发 API 如何选择
Python 标准库提供了三种在程序中并发执行任务的方法。分别是 :
- multiprocessing 模块用于基于进程的并发,
- threading 模块用于基于线程的并发,
- asyncio 模块用于基于协程的并发。
实际上还有1个选择,在 Python标准库里,基于 threading 与 multiprocessing 提供了1个异步执行多任务的高阶API: concurrent.futures 模块,由于其使用 Pool Executor 执行器API, 因此,本文后面称之为Executors API.
很多人为选择哪个感到头痛:
- 例如,在选择了一个模块之后,你应该使用工作池还是应该自己编写并发任务的代码?
- 如果你选择使用工作池,你应该使用 multiprocessor Pools API 还是 Executors API?
即使是经验丰富的 Python 开发人员也对这些选项感到困惑。
你应该为你的项目使用哪个 Python 并发 API?
你需要一些经验法则来指导选择最合适的并发 API。
选择哪个 Python 并发 API?
你想在 Python 程序中使用并发。只有一个问题。你应该使用哪个 API? 这是我见到的最常见的问题之一。
这就是我写这本指南的原因。
首先,有三个主要的 Python 并发 API,它们是:
- 基于协程,由 “asyncio” 模块提供。
- 基于线程,由 “threading” 模块提供。
- 基于进程,由 “multiprocessing” 模块提供。
在这三个之间选择相对直接。我将在下一节中向你展示如何做到这一点。
问题在于,还有更多的决定要做。你需要考虑是否应该使用可重用的工作池。
例如:
- 如果你决定需要基于线程的并发,你应该使用线程池还是以某种方式使用 Thread 类?
- 如果你决定需要基于进程的并发,你应该使用进程池还是以某种方式使用 Process 类?
然后,如果你决定使用可重用的工作池进行并发,你有多个选项可供选择。
例如:
- 如果你决定需要线程池,你应该使用 ThreadPool 类还是 ThreadPoolExecutor?
- 如果你决定需要进程池,你应该使用 Pool 类还是 ProcessPoolExecutor?
下图总结了这些决策点。

你如何弄清楚这一切?
你如何选择适合你项目的 Python 并发 API?
选择 Python 并发 API 的过程
你可以使用的一种方法,也许是最常见的方法,是临时选择一个 API。许多开发决策都是这样做出的,你的程序可能会很好地工作。但也许不会。
我建议在选择适合你项目的 Python 并发 API 时,采用 3 步过程判断:
步骤如下:
- 第 1 步:任务是基于CPU 绑定 vs IO 绑定(多进程 vs 线程)
- 第 2 步:需要并发执行许多临时任务 vs 只是一个复杂任务?
- 第 3 步:用池(Pool) vs 执行器(executor)?
我还把决策分析树绘成了一个方便的图片,如下:

接下来,让我们仔细看看每个步骤并增加一些细微差别。
第 1 步:CPU 绑定任务 vs IO 绑定任务?
选择要使用的 Python 并发 API 的第一步是考虑你想要执行的任务或任务的限制因素。
任务主要是 CPU 绑定还是 IO 绑定?
如果你正确理解这部分,你需要做的其他决定就变得不那么重要了。
让我们分别仔细看看每个方面。
CPU 绑定任务
CPU 绑定任务是一种涉及执行计算而不涉及 IO 的任务类型。这些操作只涉及内存中的数据,并对该数据执行计算。因此,这些操作的限制是 CPU 的速度。这就是为什么我们称它们为 CPU 绑定任务。
示例包括:
- 估计圆周率。
- 分解质数。
- 解析 HTML、JSON 等文档。
- 处理文本。
- 运行模拟。
CPU 非常快,我们通常有一个以上的 多核CPU。我们希望执行我们的任务并充分利用现代硬件中的多个 CPU 核心。
现在我们已经熟悉了 CPU 绑定任务,让我们仔细看看 IO 绑定任务。
IO 绑定任务
IO 绑定任务是一种涉及从设备、文件或套接字连接中读取或写入的任务类型。这些操作涉及输入和输出 (IO),这些操作的速度受到设备、硬盘或网络连接的限制。这就是为什么这些任务被称为 IO 绑定的原因。
CPU 真的很快。现代 CPU,像 4GHz,每秒可以执行 40 亿条指令,你的系统中可能有一个以上的 CPU。与 CPU 的速度相比,做 IO 非常慢。与设备交互、读写文件和套接字连接涉及调用操作系统中的指令(内核),它将等待操作完成。如果这个操作是你的 CPU 的主要焦点,比如在你的 Python 程序的主线程中执行,那么你的 CPU 将等待很多毫秒,甚至很多秒,什么都不做。那是潜在的数十亿次操作,它被阻止执行。
IO 绑定任务的示例包括:
- 从硬盘读取或写入文件。
- 读取或写入标准输出、输入或错误(stdin、stdout、stderr)。
- 打印文档。
- 下载或上传文件。
- 查询服务器。
- 查询数据库。
- 拍照或录像。
- 等等。
现在我们已经熟悉了 CPU 绑定和 IO 绑定任务,让我们考虑我们应该使用哪种类型的 Python 并发 API。
选择 Python 并发 API
回想一下,multiprocessing 模块提供基于进程的并发,threading 模块提供进程内的基于线程的并发。
通常,如果你有 CPU 绑定任务,你应该使用基于进程的并发。
如果你有 IO 绑定任务,你应该使用基于线程的并发。
- CPU 绑定任务:使用 “multiprocessing” 模块进行基于进程的并发。
- IO 绑定任务:使用 “threading” 模块进行基于线程的并发。
multiprocessing 模块适用于主要关注计算或计算某物的任务,这些任务之间共享的数据相对较少。由于计算开销的增加,以及所有进程之间共享的数据都必须序列化,multiprocessing 不适用于任务之间发送或接收大量数据。
多进程可以让你可以利用每1个 CPU 核心或每个物理 CPU 核心来运行任务,并最大化利用底层硬件资源。
threading 模块适用于主要关注从 IO 设备读取或写入的任务,计算相对较少。由于全局解释器锁 (GIL) 阻止一次执行多个 Python 线程,threading 不适用于执行大量 CPU 计算的任务。GIL 通常只在执行阻塞操作时释放,比如 IO,或者在一些第三方 C 库中特别如此,比如 NumPy。
你可以执行数十、数百或数千个基于线程的任务,因为 IO 大部分时间都在等待。
下图总结了在线程模块的多线程并发和 multiprocessing 模块的进程并发之间进行选择的决策点。

你可以参考本人关于 threading 和 multiprocessing 的文章:
- Python 多进程编程指南
- Python 多线程编程指南
接下来,让我们考虑 AsyncIO 是否合适。
第 1.1 步 在线程和 AsyncIO 之间进行选择
如果你的任务主要是 IO 绑定的,你有另一个决策点。你必须在 “threading” 模块和 “asyncio” 模块之间进行选择。回想一下,threading 模块提供基于线程的并发,asyncio 模块提供线程内的基于协程的并发。
通常,如果你有很多套接字连接(或者更喜欢异步编程),你应该使用基于协程的并发。否则,你应该使用基于线程的并发。
- 多个套接字连接:使用 “asyncio” 模块进行基于协程的并发。
- 否则:使用 “threading” 模块进行基于线程的并发。
asyncio 模块专注于套接字连接的并发非阻塞 IO。例如,如果你的 IO 任务是基于文件的,那么 asyncio 可能不是合适的选择,至少仅因为这一点。
原因是协程比线程更轻量级,因此一个线程可以托管比进程可以管理的线程多得多的协程。例如,asyncio 可能允许成千上万,甚至更多的协程用于基于套接字的 IO,而 threading API 可能只有几百到低数千个线程。
另一个考虑是你可能会想要或需要在开发程序时使用异步编程范式,例如 async/wait。因此,这个要求将覆盖任务所施加的任何要求。同样,你可能对异步编程范式有反感,因此这种偏好将覆盖任务所施加的任何要求。
第 2 步:并发执行许多临时任务 vs 一个复杂任务?
第二步是考虑你是否需要执行独立的临时任务或一个大型复杂任务。
我们在这一点上考虑的是,你是否需要发出一个或多个可能从可重用工作池中受益的临时任务。或者,你是否需要一个单一任务,其中可重用工作池将是多余的。
另一种思考方式是,你是否有一个或几个不同但复杂的任务,如监视器、调度程序或类似的任务,可能会持续很长时间,例如程序的持续时间。这些将不是临时任务,并且可能不会从可重用工作池中受益。
- 短暂和/或许多临时:使用线程或进程池。
- 长期和/或复杂任务:使用 Thread 或 Process 类。
在你选择基于线程的并发的情况下,选择是在线程池或使用 Thread 类之间。
在你选择基于进程的并发的情况下,选择是在进程池或使用 Process 类之间。
一些额外的考虑包括:
- 异构 vs 同质任务:池可能更适合一组不同的任务(异构),而 Process/Thread 类适合一种类型任务(同质)。
- 重用 vs 一次性使用:池适合重用并发的基础,例如重用线程或进程执行多个任务,而 Process/Thread 类适合一次性任务,可能是一个长期任务。
- 多个任务 vs 单个任务:池自然支持多个任务,可能以多种方式发出,而 Process/Thread 类只支持一种类型的任务,一次配置或覆盖。
让我们通过一些例子来具体化:
- 一个 for 循环,每次迭代调用一个函数,每次使用不同的参数,可能适合线程池,因为可以自动重用工作线程完成每个任务。
- 一个监视资源的后台任务可能适合 Thread/Process 类,因为它是一个长期运行的单一任务,可能有很多复杂和专业的功能,可能分散在许多函数调用中。
- 一个下载许多文件的脚本可能适合工作池,因为每个任务持续时间很短,可能有更多的文件而不是工人,允许重用工人和排队任务以完成。
- 一个维护内部状态并与主程序交互的一次性任务可能适合 Thread/Process 类,因为类可以被覆盖以使用实例变量进行状态管理,使用方法进行模块化功能。
下图可能有助于在工作池和 Thread 或 Process 类之间进行选择。

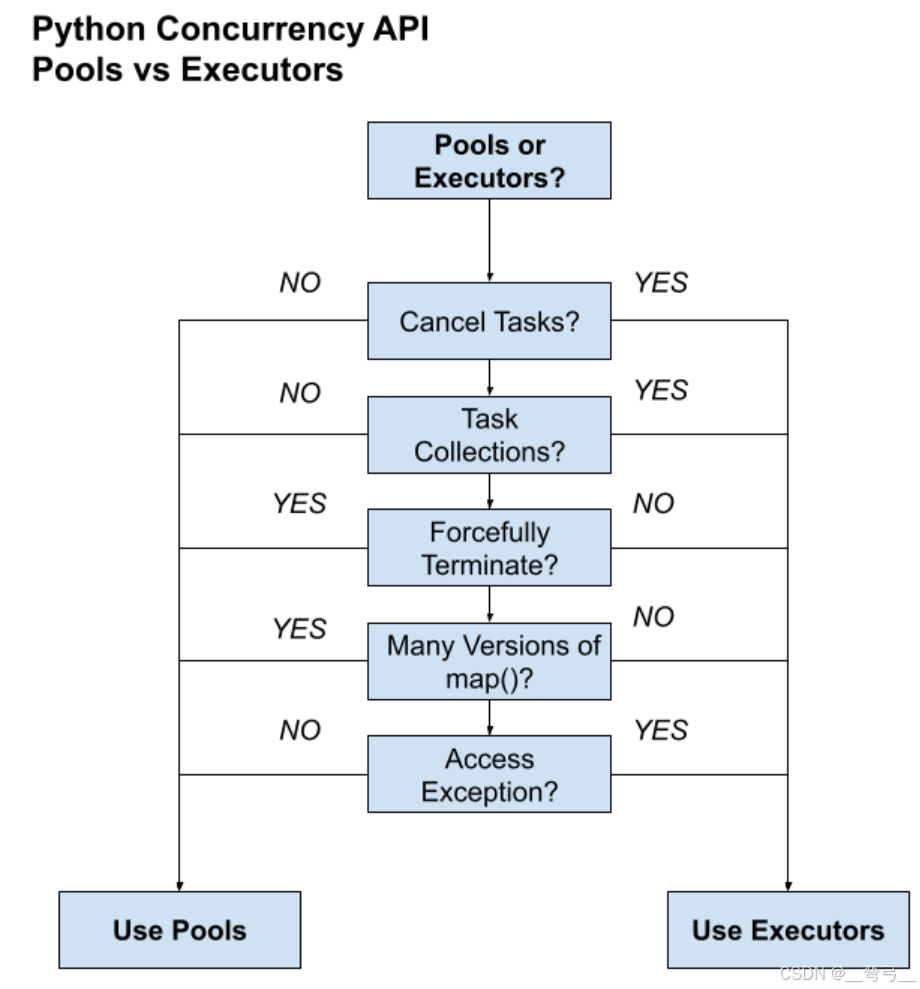
第 3 步:池 vs 执行器?
第三步是考虑要使用的工作者池的类型。
有两种主要类型,它们是:
- 池:multiprocessing.pool.Pool 和支持线程的类的移植 multiprocessing.pool.ThreadPool。
- 执行器:concurrent.futures.Executor 类和两个子类 ThreadPoolExecutor 和 ProcessPoolExecutor。
两者都提供工作者池。相似之处众多,差异很少且微妙。
例如,相似之处包括:
- 两者都有线程和基于进程的版本。
- 两者都可以执行临时任务。
- 两者都支持同步和异步任务执行。
- 两者都提供检查状态和等待异步任务的支持。
- 两者都支持异步任务的回调函数。
选择一个而不是另一个对你的程序不会有太大影响。主要区别在于每个提供的 API,特别是在任务处理的重点或方式上的微小差异。
例如:
- 执行器提供取消已发布任务的能力,而池则没有。
- 执行器提供处理不同类型任务集合的能力,而池则没有。
- 执行器没有强制终止所有任务的能力,而池有。
- 执行器没有提供多个并行版本的 map() 函数,而池有。
- 执行器提供访问任务中引发的异常的能力,而池则没有。
我认为,关于池(Pool)真正重要是,池专注于使用许多不同版本的 map() 函数进行并发 for 循环,可将函数应用于一个可迭代参数中的每个参数。
执行器具有这种能力,但重点更多地是发布临时任务并异步管理任务集合。
下图有助于总结池和执行器之间的差异。
结束语
现在你知道如何在不同的 Python 并发 API 之间进行选择。