因为我本地是 windows 的系统,所以这里直接写的是通过 docker 来实现本地大模型的部署。
windows 下 WSl 的安装这里就不做重复,详见 windows 部署 mindspore GPU 开发环境(WSL)
一、Docker 部署 ollma
1. 拉取镜像(笔记本没有对象显卡,所以拉取的镜像是CPU 版本的):
docker pull ollama/ollama:0.3.7-rc6
2. 启动镜像
仅 CPU 版本启动
docker run -d -v /home/jie/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:0.3.7-rc6

此时访问本地的 11434 端口,可以看到 Ollama is running 的字样

1.1 通过对话交互的方式启动 llama3
ollma 贴心的提供了很多模型和参数,详见 Ollama library 我这里选择启动的是 llama3 模型 参数量是 8b。
docker exec -it ollama ollama run llama3.1
首次启动需要下载参数,所以会花费一些时间。

并在光标闪烁的地方开始对话

当然,8b 模型的结果有时候不太好,如果电脑内存在 60G 以上,可以大胆的尝试 70b 的模型。

1.2 通过服务的方式调用 llama3
curl http://localhost:11434/api/generate -d '{"model": "llama3.1", "prompt": "帮我写一条Elasticsearch的聚合 a 字段的查询语句","format": "json^C"stream": false
}'
参数 "model" 表示模型名,一定要 执行过 docker exec -it ollama ollama run 才可以正常响应。这种方式的响应时间比较长,原因有可能是每次请求的时候都会重新启动模型的原因(我并没有找到让模型一直保持启动状态的参数)。API列表

获取响应中的 response 字段就是大模型生成的回答。
二、附录
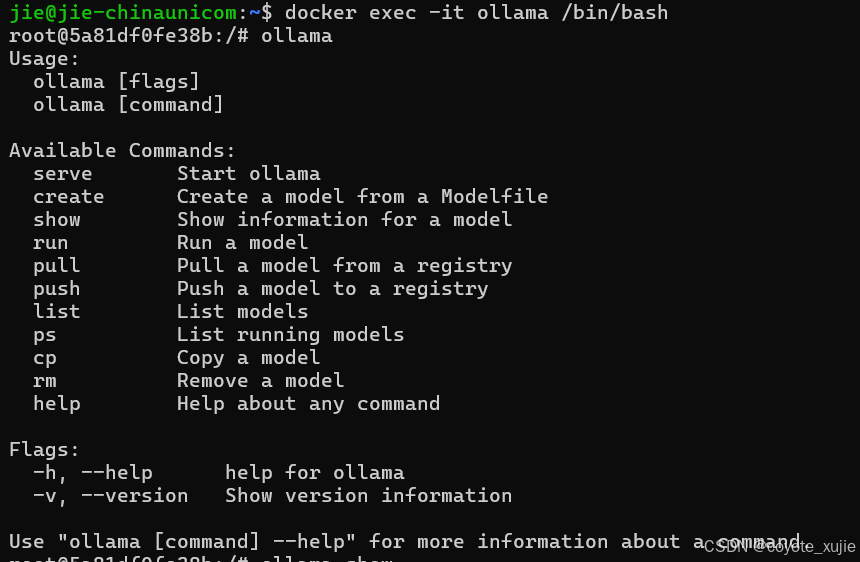
2.1 Ollama 常用命令
Usage:ollama [flags]ollama [command]Available Commands:serve Start ollama # 启动ollamacreate Create a model from a Modelfile # 从模型文件创建模型show Show information for a model # 显示模型信息run Run a model # 运行模型,会先自动下载模型pull Pull a model from a registry # 从注册仓库中拉取模型push Push a model to a registry # 将模型推送到注册仓库list List models # 列出已下载模型ps List running models # 列出正在运行的模型cp Copy a model # 复制模型rm Remove a model # 删除模型help Help about any commandFlags:-h, --help help for ollama-v, --version Show version informationUse "ollama [command] --help" for more information about a command.