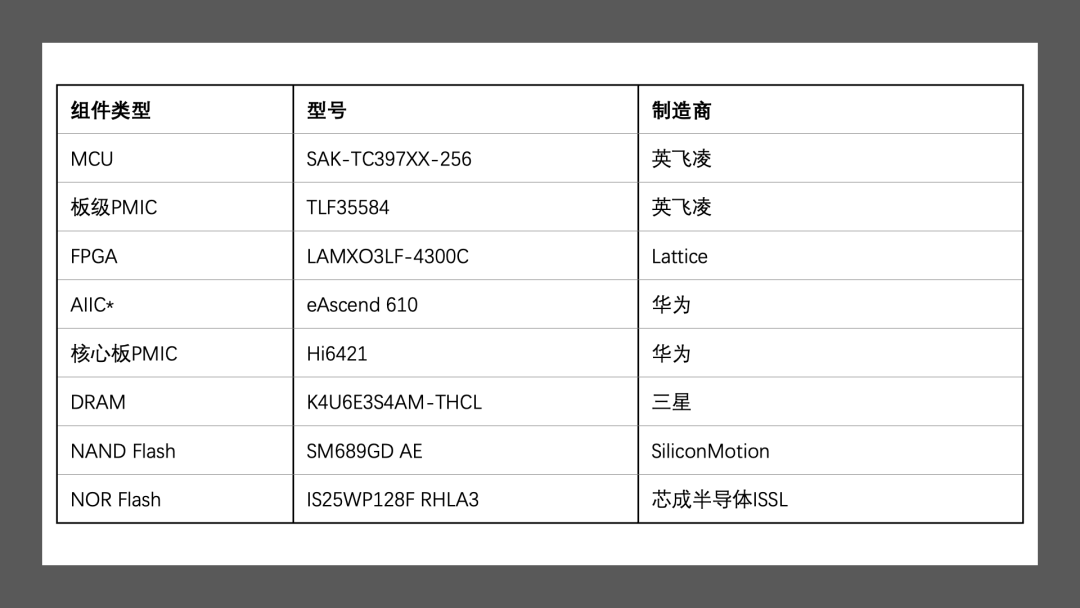
GATK(Genome Analysis Toolkit)是一个广泛使用的基因组分析工具包,它的核心库之一是htsjdk,用于处理高通量测序数据。在GATK中,ReadsPathDataSource类是负责管理和提供读取高通量测序数据文件(如BAM、SAM、CRAM)的类。
常见使用场景
- 数据加载:在GATK的基因组分析工具链中,
ReadsPathDataSource经常被用来从指定路径加载测序数据。 - 数据过滤:通过
ReadsPathDataSource,可以方便地在加载数据的同时进行预过滤,如按特定标准选择感兴趣的序列记录。 - 多文件支持:支持同时从多个文件中加载数据,使得分析多个样本的数据更加便捷。
类关系

ReadsPathDataSource源码
package org.broadinstitute.hellbender.engine;import com.google.common.annotations.VisibleForTesting;
import htsjdk.samtools.MergingSamRecordIterator;
import htsjdk.samtools.SAMException;
import htsjdk.samtools.SAMFileHeader;
import htsjdk.samtools.SAMRecord;
import htsjdk.samtools.SAMSequenceDictionary;
import htsjdk.samtools.SamFileHeaderMerger;
import htsjdk.samtools.SamInputResource;
import htsjdk.samtools.SamReader;
import htsjdk.samtools.SamReaderFactory;
import htsjdk.samtools.util.CloseableIterator;
import htsjdk.samtools.util.IOUtil;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.broadinstitute.hellbender.exceptions.GATKException;
import org.broadinstitute.hellbender.exceptions.UserException;
import org.broadinstitute.hellbender.utils.IntervalUtils;
import org.broadinstitute.hellbender.utils.SimpleInterval;
import org.broadinstitute.hellbender.utils.Utils;
import org.broadinstitute.hellbender.utils.gcs.BucketUtils;
import org.broadinstitute.hellbender.utils.iterators.SAMRecordToReadIterator;
import org.broadinstitute.hellbender.utils.iterators.SamReaderQueryingIterator;
import org.broadinstitute.hellbender.utils.read.GATKRead;
import org.broadinstitute.hellbender.utils.read.ReadConstants;import java.io.IOException;
import java.nio.channels.SeekableByteChannel;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.Function;
import java.util.stream.Collectors;/*** Manages traversals and queries over sources of reads which are accessible via {@link Path}s* (for now, SAM/BAM/CRAM files only).** Two basic operations are available:** -Iteration over all reads, optionally restricted to reads that overlap a set of intervals* -Targeted queries by one interval at a time*/
public final class ReadsPathDataSource implements ReadsDataSource {private static final Logger logger = LogManager.getLogger(ReadsPathDataSource.class);/*** Mapping from SamReaders to iterators over the reads from each reader. Only one* iterator can be open from a given reader at a time (this is a restriction* in htsjdk). Iterator is set to null for a reader if no iteration is currently* active on that reader.*/private final Map<SamReader, CloseableIterator<SAMRecord>> readers;/*** Hang onto the input files so that we can print useful errors about them*/private final Map<SamReader, Path> backingPaths;/*** Only reads that overlap these intervals (and unmapped reads, if {@link #traverseUnmapped} is set) will be returned* during a full iteration. Null if iteration is unbounded.** Individual queries are unaffected by these intervals -- only traversals initiated via {@link #iterator} are affected.*/private List<SimpleInterval> intervalsForTraversal;/*** If true, restrict traversals to unmapped reads (and reads overlapping any {@link #intervalsForTraversal}, if set).* False if iteration is unbounded or bounded only by our {@link #intervalsForTraversal}.** Note that this setting covers only unmapped reads that have no position -- unmapped reads that are assigned the* position of their mates will be returned by queries overlapping that position.** Individual queries are unaffected by this setting -- only traversals initiated via {@link #iterator} are affected.*/private boolean traverseUnmapped;/*** Used to create a merged Sam header when we're dealing with multiple readers. Null if we only have a single reader.*/private final SamFileHeaderMerger headerMerger;/*** Are indices available for all files?*/private boolean indicesAvailable;/*** Has it been closed already.*/private boolean isClosed;/*** Initialize this data source with a single SAM/BAM file and validation stringency SILENT.** @param samFile SAM/BAM file, not null.*/public ReadsPathDataSource( final Path samFile ) {this(samFile != null ? Arrays.asList(samFile) : null, (SamReaderFactory)null);}/*** Initialize this data source with multiple SAM/BAM files and validation stringency SILENT.** @param samFiles SAM/BAM files, not null.*/public ReadsPathDataSource( final List<Path> samFiles ) {this(samFiles, (SamReaderFactory)null);}/*** Initialize this data source with a single SAM/BAM file and a custom SamReaderFactory** @param samPath path to SAM/BAM file, not null.* @param customSamReaderFactory SamReaderFactory to use, if null a default factory with no reference and validation* stringency SILENT is used.*/public ReadsPathDataSource( final Path samPath, SamReaderFactory customSamReaderFactory ) {this(samPath != null ? Arrays.asList(samPath) : null, customSamReaderFactory);}/*** Initialize this data source with multiple SAM/BAM files and a custom SamReaderFactory** @param samPaths path to SAM/BAM file, not null.* @param customSamReaderFactory SamReaderFactory to use, if null a default factory with no reference and validation* stringency SILENT is used.*/public ReadsPathDataSource( final List<Path> samPaths, SamReaderFactory customSamReaderFactory ) {this(samPaths, null, customSamReaderFactory, 0, 0);}/*** Initialize this data source with multiple SAM/BAM/CRAM files, and explicit indices for those files.** @param samPaths paths to SAM/BAM/CRAM files, not null* @param samIndices indices for all of the SAM/BAM/CRAM files, in the same order as samPaths. May be null,* in which case index paths are inferred automatically.*/public ReadsPathDataSource( final List<Path> samPaths, final List<Path> samIndices ) {this(samPaths, samIndices, null, 0, 0);}/*** Initialize this data source with multiple SAM/BAM/CRAM files, explicit indices for those files,* and a custom SamReaderFactory.** @param samPaths paths to SAM/BAM/CRAM files, not null* @param samIndices indices for all of the SAM/BAM/CRAM files, in the same order as samPaths. May be null,* in which case index paths are inferred automatically.* @param customSamReaderFactory SamReaderFactory to use, if null a default factory with no reference and validation* stringency SILENT is used.*/public ReadsPathDataSource( final List<Path> samPaths, final List<Path> samIndices,SamReaderFactory customSamReaderFactory ) {this(samPaths, samIndices, customSamReaderFactory, 0, 0);}/*** Initialize this data source with multiple SAM/BAM/CRAM files, explicit indices for those files,* and a custom SamReaderFactory.** @param samPaths paths to SAM/BAM/CRAM files, not null* @param samIndices indices for all of the SAM/BAM/CRAM files, in the same order as samPaths. May be null,* in which case index paths are inferred automatically.* @param customSamReaderFactory SamReaderFactory to use, if null a default factory with no reference and validation* stringency SILENT is used.* @param cloudPrefetchBuffer MB size of caching/prefetching wrapper for the data, if on Google Cloud (0 to disable).* @param cloudIndexPrefetchBuffer MB size of caching/prefetching wrapper for the index, if on Google Cloud (0 to disable).*/public ReadsPathDataSource( final List<Path> samPaths, final List<Path> samIndices,SamReaderFactory customSamReaderFactory,int cloudPrefetchBuffer, int cloudIndexPrefetchBuffer) {this(samPaths, samIndices, customSamReaderFactory,BucketUtils.getPrefetchingWrapper(cloudPrefetchBuffer),BucketUtils.getPrefetchingWrapper(cloudIndexPrefetchBuffer) );}/*** Initialize this data source with multiple SAM/BAM/CRAM files, explicit indices for those files,* and a custom SamReaderFactory.** @param samPaths paths to SAM/BAM/CRAM files, not null* @param samIndices indices for all of the SAM/BAM/CRAM files, in the same order as samPaths. May be null,* in which case index paths are inferred automatically.* @param customSamReaderFactory SamReaderFactory to use, if null a default factory with no reference and validation* stringency SILENT is used.* @param cloudWrapper caching/prefetching wrapper for the data, if on Google Cloud.* @param cloudIndexWrapper caching/prefetching wrapper for the index, if on Google Cloud.*/public ReadsPathDataSource( final List<Path> samPaths, final List<Path> samIndices,SamReaderFactory customSamReaderFactory,Function<SeekableByteChannel, SeekableByteChannel> cloudWrapper,Function<SeekableByteChannel, SeekableByteChannel> cloudIndexWrapper ) {Utils.nonNull(samPaths);Utils.nonEmpty(samPaths, "ReadsPathDataSource cannot be created from empty file list");if ( samIndices != null && samPaths.size() != samIndices.size() ) {throw new UserException(String.format("Must have the same number of BAM/CRAM/SAM paths and indices. Saw %d BAM/CRAM/SAMs but %d indices",samPaths.size(), samIndices.size()));}readers = new LinkedHashMap<>(samPaths.size() * 2);backingPaths = new LinkedHashMap<>(samPaths.size() * 2);indicesAvailable = true;final SamReaderFactory samReaderFactory =customSamReaderFactory == null ?SamReaderFactory.makeDefault().validationStringency(ReadConstants.DEFAULT_READ_VALIDATION_STRINGENCY) :customSamReaderFactory;int samCount = 0;for ( final Path samPath : samPaths ) {// Ensure each file can be readtry {IOUtil.assertFileIsReadable(samPath);}catch ( SAMException|IllegalArgumentException e ) {throw new UserException.CouldNotReadInputFile(samPath.toString(), e);}Function<SeekableByteChannel, SeekableByteChannel> wrapper =(BucketUtils.isEligibleForPrefetching(samPath)? cloudWrapper: Function.identity());// if samIndices==null then we'll guess the index name from the file name.// If the file's on the cloud, then the search will only consider locations that are also// in the cloud.Function<SeekableByteChannel, SeekableByteChannel> indexWrapper =((samIndices != null && BucketUtils.isEligibleForPrefetching(samIndices.get(samCount))|| (samIndices == null && BucketUtils.isEligibleForPrefetching(samPath)))? cloudIndexWrapper: Function.identity());SamReader reader;if ( samIndices == null ) {reader = samReaderFactory.open(samPath, wrapper, indexWrapper);}else {final SamInputResource samResource = SamInputResource.of(samPath, wrapper);Path indexPath = samIndices.get(samCount);samResource.index(indexPath, indexWrapper);reader = samReaderFactory.open(samResource);}// Ensure that each file has an indexif ( ! reader.hasIndex() ) {indicesAvailable = false;}readers.put(reader, null);backingPaths.put(reader, samPath);++samCount;}// Prepare a header merger only if we have multiple readersheaderMerger = samPaths.size() > 1 ? createHeaderMerger() : null;}/*** Are indices available for all files?*/public boolean indicesAvailable() {return indicesAvailable;}/*** @return true if indices are available for all inputs.* This is identical to {@link #indicesAvailable}*/@Overridepublic boolean isQueryableByInterval() {return indicesAvailable();}/*** Restricts a traversal of this data source via {@link #iterator} to only return reads that overlap the given intervals,* and to unmapped reads if specified.** Calls to {@link #query} are not affected by this method.** @param intervals Our next full traversal will return reads overlapping these intervals* @param traverseUnmapped Our next full traversal will return unmapped reads (this affects only unmapped reads that* have no position -- unmapped reads that have the position of their mapped mates will be* included if the interval overlapping that position is included).*/@Overridepublic void setTraversalBounds( final List<SimpleInterval> intervals, final boolean traverseUnmapped ) {// Set intervalsForTraversal to null if intervals is either null or emptythis.intervalsForTraversal = intervals != null && ! intervals.isEmpty() ? intervals : null;this.traverseUnmapped = traverseUnmapped;if ( traversalIsBounded() && ! indicesAvailable ) {raiseExceptionForMissingIndex("Traversal by intervals was requested but some input files are not indexed.");}}/*** @return True if traversals initiated via {@link #iterator} will be restricted to reads that overlap intervals* as configured via {@link #setTraversalBounds}, otherwise false*/@Overridepublic boolean traversalIsBounded() {return intervalsForTraversal != null || traverseUnmapped;}private void raiseExceptionForMissingIndex( String reason ) {String commandsToIndex = backingPaths.entrySet().stream().filter(f -> !f.getKey().hasIndex()).map(Map.Entry::getValue).map(Path::toAbsolutePath).map(f -> "samtools index " + f).collect(Collectors.joining("\n","\n","\n"));throw new UserException(reason + "\nPlease index all input files:\n" + commandsToIndex);}/*** Iterate over all reads in this data source. If intervals were provided via {@link #setTraversalBounds},* iteration is limited to reads that overlap that set of intervals.** @return An iterator over the reads in this data source, limited to reads that overlap the intervals supplied* via {@link #setTraversalBounds} (if intervals were provided)*/@Overridepublic Iterator<GATKRead> iterator() {logger.debug("Preparing readers for traversal");return prepareIteratorsForTraversal(intervalsForTraversal, traverseUnmapped);}/*** Query reads over a specific interval. This operation is not affected by prior calls to* {@link #setTraversalBounds}** @param interval The interval over which to query* @return Iterator over reads overlapping the query interval*/@Overridepublic Iterator<GATKRead> query( final SimpleInterval interval ) {if ( ! indicesAvailable ) {raiseExceptionForMissingIndex("Cannot query reads data source by interval unless all files are indexed");}return prepareIteratorsForTraversal(Arrays.asList(interval));}/*** @return An iterator over just the unmapped reads with no assigned position. This operation is not affected* by prior calls to {@link #setTraversalBounds}. The underlying file must be indexed.*/@Overridepublic Iterator<GATKRead> queryUnmapped() {if ( ! indicesAvailable ) {raiseExceptionForMissingIndex("Cannot query reads data source by interval unless all files are indexed");}return prepareIteratorsForTraversal(null, true);}/*** Returns the SAM header for this data source. Will be a merged header if there are multiple readers.* If there is only a single reader, returns its header directly.** @return SAM header for this data source*/@Overridepublic SAMFileHeader getHeader() {return headerMerger != null ? headerMerger.getMergedHeader() : readers.entrySet().iterator().next().getKey().getFileHeader();}/*** Prepare iterators over all readers in response to a request for a complete iteration or query** If there are multiple intervals, they must have been optimized using QueryInterval.optimizeIntervals()* before calling this method.** @param queryIntervals Intervals to bound the iteration (reads must overlap one of these intervals). If null, iteration is unbounded.* @return Iterator over all reads in this data source, limited to overlap with the supplied intervals*/private Iterator<GATKRead> prepareIteratorsForTraversal( final List<SimpleInterval> queryIntervals ) {return prepareIteratorsForTraversal(queryIntervals, false);}/*** Prepare iterators over all readers in response to a request for a complete iteration or query** @param queryIntervals Intervals to bound the iteration (reads must overlap one of these intervals). If null, iteration is unbounded.* @return Iterator over all reads in this data source, limited to overlap with the supplied intervals*/private Iterator<GATKRead> prepareIteratorsForTraversal( final List<SimpleInterval> queryIntervals, final boolean queryUnmapped ) {// htsjdk requires that only one iterator be open at a time per reader, so close out// any previous iterationsclosePreviousIterationsIfNecessary();final boolean traversalIsBounded = (queryIntervals != null && ! queryIntervals.isEmpty()) || queryUnmapped;// Set up an iterator for each reader, bounded to overlap with the supplied intervals if there are anyfor ( Map.Entry<SamReader, CloseableIterator<SAMRecord>> readerEntry : readers.entrySet() ) {if (traversalIsBounded) {readerEntry.setValue(new SamReaderQueryingIterator(readerEntry.getKey(),readers.size() > 1 ?getIntervalsOverlappingReader(readerEntry.getKey(), queryIntervals) :queryIntervals,queryUnmapped));} else {readerEntry.setValue(readerEntry.getKey().iterator());}}// Create a merging iterator over all readers if necessary. In the case where there's only a single reader,// return its iterator directly to avoid the overhead of the merging iterator.Iterator<SAMRecord> startingIterator = null;if ( readers.size() == 1 ) {startingIterator = readers.entrySet().iterator().next().getValue();}else {startingIterator = new MergingSamRecordIterator(headerMerger, readers, true);}return new SAMRecordToReadIterator(startingIterator);}/*** Reduce the intervals down to only include ones that can actually intersect with this reader*/private List<SimpleInterval> getIntervalsOverlappingReader(final SamReader samReader,final List<SimpleInterval> queryIntervals ){final SAMSequenceDictionary sequenceDictionary = samReader.getFileHeader().getSequenceDictionary();return queryIntervals.stream().filter(interval -> IntervalUtils.intervalIsOnDictionaryContig(interval, sequenceDictionary)).collect(Collectors.toList());}/*** Create a header merger from the individual SAM/BAM headers in our readers** @return a header merger containing all individual headers in this data source*/private SamFileHeaderMerger createHeaderMerger() {List<SAMFileHeader> headers = new ArrayList<>(readers.size());for ( Map.Entry<SamReader, CloseableIterator<SAMRecord>> readerEntry : readers.entrySet() ) {headers.add(readerEntry.getKey().getFileHeader());}SamFileHeaderMerger headerMerger = new SamFileHeaderMerger(identifySortOrder(headers), headers, true);return headerMerger;}@VisibleForTestingstatic SAMFileHeader.SortOrder identifySortOrder( final List<SAMFileHeader> headers ){final Set<SAMFileHeader.SortOrder> sortOrders = headers.stream().map(SAMFileHeader::getSortOrder).collect(Collectors.toSet());final SAMFileHeader.SortOrder order;if (sortOrders.size() == 1) {order = sortOrders.iterator().next();} else {order = SAMFileHeader.SortOrder.unsorted;logger.warn("Inputs have different sort orders. Assuming {} sorted reads for all of them.", order);}return order;}/*** @return true if this {@code ReadsPathDataSource} supports serial iteration (has only non-SAM inputs). If any* input has type==SAM_TYPE (is backed by a SamFileReader) this will return false, since SamFileReader* doesn't support serial iterators, and can't be serially re-traversed without re-initialization of the* underlying reader (and {@code ReadsPathDataSource}.*/public boolean supportsSerialIteration() {return !hasSAMInputs();}/*** Shut down this data source permanently, closing all iterations and readers.*/@Overridepublic void close() {if (isClosed) {return;}isClosed = true;closePreviousIterationsIfNecessary();try {for ( Map.Entry<SamReader, CloseableIterator<SAMRecord>> readerEntry : readers.entrySet() ) {readerEntry.getKey().close();}}catch ( IOException e ) {throw new GATKException("Error closing SAMReader");}}boolean isClosed() {return isClosed;}/*** Close any previously-opened iterations over our readers (htsjdk allows only one open iteration per reader).*/private void closePreviousIterationsIfNecessary() {for ( Map.Entry<SamReader, CloseableIterator<SAMRecord>> readerEntry : readers.entrySet() ) {CloseableIterator<SAMRecord> readerIterator = readerEntry.getValue();if ( readerIterator != null ) {readerIterator.close();readerEntry.setValue(null);}}}// Return true if any input is has type==SAM_TYPE (is backed by a SamFileReader) since SamFileReader// doesn't support serial iterators and can't be serially re-traversed without re-initialization of the// readerprivate boolean hasSAMInputs() {return readers.keySet().stream().anyMatch(r -> r.type().equals(SamReader.Type.SAM_TYPE));}/*** Get the sequence dictionary for this ReadsPathDataSource** @return SAMSequenceDictionary from the SAMReader backing this if there is only 1 input file, otherwise the merged SAMSequenceDictionary from the merged header*/@Overridepublic SAMSequenceDictionary getSequenceDictionary() {return getHeader().getSequenceDictionary();}}
ReadsDataSource源码
package org.broadinstitute.hellbender.engine;import htsjdk.samtools.SAMFileHeader;
import htsjdk.samtools.SAMSequenceDictionary;
import org.broadinstitute.hellbender.utils.SimpleInterval;
import org.broadinstitute.hellbender.utils.read.GATKRead;import java.util.Iterator;
import java.util.List;/**** An interface for managing traversals over sources of reads.** Two basic operations are available:** -Iteration over all reads, optionally restricted to reads that overlap a set of intervals* -Targeted queries by one interval at a time*/
public interface ReadsDataSource extends GATKDataSource<GATKRead>, AutoCloseable {/*** Restricts a traversal of this data source via {@link #iterator} to only return reads that overlap the given intervals,* and to unmapped reads if specified.** Calls to {@link #query} are not affected by this method.** @param intervals Our next full traversal will return reads overlapping these intervals* @param traverseUnmapped Our next full traversal will return unmapped reads (this affects only unmapped reads that* have no position -- unmapped reads that have the position of their mapped mates will be* included if the interval overlapping that position is included).*/void setTraversalBounds(List<SimpleInterval> intervals, boolean traverseUnmapped);/*** Restricts a traversal of this data source via {@link #iterator} to only return reads which overlap the given intervals.* Calls to {@link #query} are not affected by setting these intervals.** @param intervals Our next full traversal will return only reads overlapping these intervals*/default void setTraversalBounds(List<SimpleInterval> intervals) {setTraversalBounds(intervals, false);}/*** Restricts a traversal of this data source via {@link #iterator} to only return reads that overlap the given intervals,* and to unmapped reads if specified.** Calls to {@link #query} are not affected by this method.** @param traversalParameters set of traversal parameters to control which reads get returned by the next call* to {@link #iterator}*/default void setTraversalBounds(TraversalParameters traversalParameters){setTraversalBounds(traversalParameters.getIntervalsForTraversal(), traversalParameters.traverseUnmappedReads());}/*** @return true if traversals initiated via {@link #iterator} will be restricted to reads that overlap intervals* as configured via {@link #setTraversalBounds}, otherwise false*/boolean traversalIsBounded();/*** @return true if this datasource supports the query() operation otherwise false.*/boolean isQueryableByInterval();/*** @return An iterator over just the unmapped reads with no assigned position. This operation is not affected* by prior calls to {@link #setTraversalBounds}. The underlying file must be indexed.*/Iterator<GATKRead> queryUnmapped();/*** Returns the SAM header for this data source.** @return SAM header for this data source*/SAMFileHeader getHeader();/*** Get the sequence dictionary for this ReadsDataSource** @return SAMSequenceDictionary for the reads backing this datasource.*/default SAMSequenceDictionary getSequenceDictionary(){return getHeader().getSequenceDictionary();}/*** @return true if this {@code ReadsDataSource} supports multiple iterations over the data*/boolean supportsSerialIteration();/*** Shut down this data source permanently, closing all iterations and readers.*/@Override //Overriden here to disallow throwing checked exceptions.void close();
}
GATKDataSource源码
package org.broadinstitute.hellbender.engine;import org.broadinstitute.hellbender.utils.SimpleInterval;import java.util.Iterator;/*** A GATKDataSource is something that can be iterated over from start to finish* and/or queried by genomic interval. It is not necessarily file-based.** @param <T> Type of data in the data source*/
public interface GATKDataSource<T> extends Iterable<T> {Iterator<T> query(final SimpleInterval interval);
}