介绍
最近,数字和模拟技术开始加速融合。我们生活在一个人工智能技术能够显著提高质量的时代,只要模拟材料能够数字化。
例如,讨论中涉及到的纸艺软件,纸龙的移动模型被时间锁定,以大约 3 fps(每秒帧数)的速度创建视频。然而,无论连续拍摄多么细致,视频看起来都很不流畅。不过,利用不断发展的人工智能技术 RIFE(实时中间流估计),现在可以将这种 3 帧/秒的视频转换(插值)为甚至 24 帧/秒的视频。


图 1 延时视频与 RIFE 插值视频的对比
它看起来如何?人工智能技术不仅被用于生成,还被用作插值材料领域的一种新方法。
人工智能技术本身也使用神经网络等工具来提高质量。在这里,RIFE 利用中间流网络 (IFNet) 显著提高了中间帧插值的质量。
本文解释了 RIFE 和 IFNet 的工作原理,并提供了将低帧频视频转换(插值)为高帧频视频的具体示例。
用 RIFE 生成中间帧
本文讨论的 RIFE软件Flowframes是一种用于视频帧插值的实时中间流估计算法。传统方法是对双向帧的光流进行估计、缩放和反转,以近似中间流。然而,这种方法存在引入伪影(误差和失真)的问题。
为了改进性能,RIFE 使用一种名为 IFNet 的神经网络来直接、精细地估计中间流,并高速执行。参考文献[2]中的实验表明,RIFE 在多个基准测试中都达到了很高的性能,比传统方法快 4 到 27 倍。
这些数据将按以下步骤进行处理,生成中间帧。
获取输入帧


图 2 两幅连续画面(延时摄影画面 A 和画面 B)
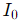
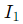 输入两个连续的帧和以启动程序。
输入两个连续的帧和以启动程序。
光流计算
两个连续帧之间的运动是通过光流来估算的。这提供了显示每个像素移动情况的矢量信息。图中显示了使用光流估算和可视化的帧前后运动。你可以看到很多矢量,显示前后帧之间的关系。
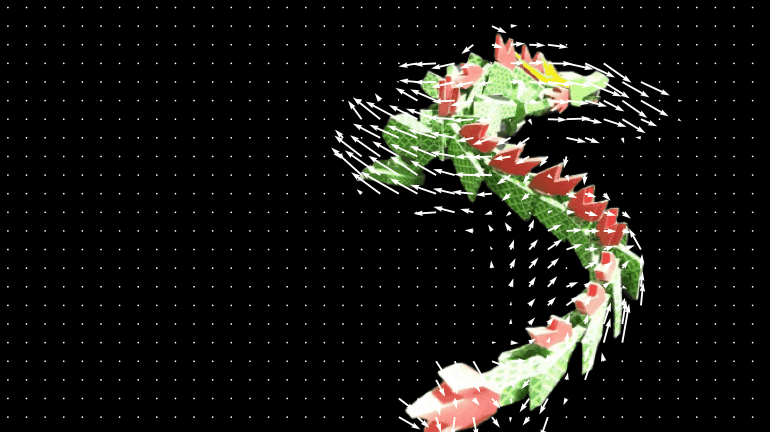
图 3-1 第 1 至第 2 帧光流的可视化效果

图 3-2 第 2 帧至第 1 帧光流的可视化效果
中间流量估算 (IFNet)
基于光流信息,IFNet 还可用于估算帧与帧之间的中间流,并了解每个像素的移动情况。
框架翘曲
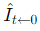
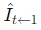 根据估计的流量,每个帧都会向后扭曲,以获得图像和中间位置的图像。
根据估计的流量,每个帧都会向后扭曲,以获得图像和中间位置的图像。
生成融合图
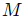
 使用融合图,将翘曲帧融合在一起,生成最终的中间帧。这就是以下公式所示的内容。
使用融合图,将翘曲帧融合在一起,生成最终的中间帧。这就是以下公式所示的内容。
生成中间帧。
计算扭曲帧。
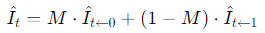
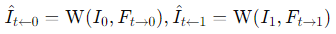
这种方法通常比其他方法更快,而且可以生成高质量的中间帧。

图 4 生成的中间帧
翘曲的含义
翘曲是指变换图像或视频中的像素。具体来说,它是指通过将像素从原始位置移动到新位置来转换图像或帧。这就像拉动或推动纸张图片以改变其形状一样。
什么是融合地图?
融合地图并不是人工智能的一种,它是人工智能创建的加权地图,是人工智能使用的类似工具的实体,如 IFNet。
融合图的作用是确定像素的融合程度。它提供了权重信息,说明在对每个像素进行扭曲处理后,应从帧(扭曲帧 A 或扭曲帧 B)中提取多少信息。
确定每个像素的权重,例如,一个像素的 70% 来自翘曲帧 A,30% 来自翘曲帧 B。这些权重信息用于融合两个帧并生成中间帧。
融合制图是一种将不同来源的数据融合在一起以创建新图像的方法。
'它将不同来源的数据结合起来,创造出新的图像,这一点与图像生成人工智能**‘**图像到图像’(Image to Image)相似。然而,生成式人工智能本身的作用和意义以及它所创建的工具却完全不同。
IFNet 概览及其运作方式
IFNet 是一个用于直接估算中间流(intermediate flow)的神经网络。该网络用于生成两个连续帧(如帧 A、帧 B)之间的中间帧。
例如,假设 IFNet 接收到连续的输入帧(帧 A 和帧 B)和时间间隔 (t)。然后,IFNet 会估算帧之间的中间流(像素移动)和融合图 (M)。然后,利用估算出的中间流对输入帧进行扭曲(变形),并通过融合图生成中间帧(融合图决定每个像素从哪个帧中获取多少信息)。
课程查找策略
生成过程采用一种称为 “流程到精细”(course-to-fine)的方法,即在低分辨率下粗略估算流量,然后随着分辨率的提高对流量进行细节修改。
IFNet 使用大量图像帧和特权蒸馏(PRD)进行训练。这使得它能够正确识别一定量的未知数据。



图 5:航迹到精细图像(低分辨率到高分辨率)
RIFE 和 IFNet 操作与图像到图像对比
每种方法都有不同的技术和方法,也有不同的目标。
RIFE 和 IFNet 合作生成中间帧。其目的之一是提高视频的流畅度,这也是该技术的重点所在。
图像到图像的图像生成人工智能 “专门从事图像转换”。它利用生成对抗网络(GAN)和扩散模型等典型实例,从输入图像生成新图像。该技术通过变换风格和改变属性(物体、人物、情感等)生成各种图像。
RIFE 和 IFNet 中间帧插值与变形技术的对比
主要区别在于方法和精度。
中间帧插值结合了光流(RIFE)和神经网络(IFNet、融合图),可实时生成极其精确和自然的中间帧。
而变形技术则主要利用形状变形来 "平滑 "两帧之间的变化。特征点之间的像素只是通过线性插值形成中间帧。这使得它处理复杂运动的能力受到限制。



图 6:变形示例。
实例
目前,除非图像与前一幅图像重叠约半帧,否则帧插值就会失败。不过,从 20 幅图像中,可以以 41 帧/秒的速度生成一段流畅的 3 秒视频,这是人工智能生成器的一项了不起的能力。
模拟材料被赋予了动态感和生命力,证实了使用生成式人工智能的艺术性。
以上是讨论中的一段话,但这种人工智能技术也不是万能的:对于两帧之间间隔较大的连续图像,插值是不完整的。这是因为物体位置和形状的变化太大,参考点的数量减少,使得光流等运动估计算法无法捕捉到运动。
当涉及旋转或复杂运动时,插值尤其困难。同样的道理也适用于物体在帧与帧之间时隐时现的视频。
不过,现在有一种名为 DAIN(深度感知视频帧插值)的帧插值技术,可以将深度信息考虑在内。未来的发展值得期待。


图 7 运动矢量短且不规则 → 中间帧不完整
总结
我们在本文中谈到了与质量改进相关的人工智能技术,比如那些幕后技术。最后,我们将引用一段话和一个视频示例来说明经过处理的讨论所表明的 “不可改变的想法”。
这些动感十足的纸艺作品是使用原创软件 "Paper Dragon "制作的,经过手工制作、组装、拍照,然后在数字环境中进行插值。作者深信,未来将通过数字-模拟-数字合作创造出新的表现技法。







![[论文笔记]Improving Retrieval Augmented Language Model with Self-Reasoning](https://img-blog.csdnimg.cn/img_convert/10f50a19d0c5b8ebb7e737cd9462c018.png)