前言
由于fastgpt只提供了一个分享用的网页应用,网页访问地址没法自定义,虽然可以接入NextWeb/ChatGPT web等开源应用。但是如果我们想直接给客户应用,还需要客户去设置配置,里面还有很多我们不想展示给客户的东西怎么办?于是,我使用Chainlit实现了一个无缝快速接入fastgpt实现自定义用户使用界面的应用,代码清晰简单。还可以自定义logo、欢迎语、网站图标等。
之前写一个一篇文章 《Chainlit接入FastGpt接口快速实现自定义用户聊天界面》 文章中实现了Fastgpt的对话接口,可以实现聊天,但是有些人想。接入Fastgpt的欢迎语,获取聊天历史记录等。本此的代码更新可以实现这些,下面我主要讲一些这次代码更新实现的亮点吧!
1. 接入Fastgpt后,可以自动更新成你的网站图标和网站名称

2. 接入欢迎语

3. 接入聊天记录

- 不仅可以实现聊天记录的自动添加还可实现删除,搜索聊天记录的功能,原fastgpt的分享聊天网页可没有聊天搜索功能呦!
4 可以开启黑白主题的切换

5.可以自定义修改访问路径
当然这个功能需要你自己修改启动地址
快速开始
获取Fastgpt的信息
获取fastgpt的base_url和share_id
登录fastgpt后台,在工作台里,点击自己创建的AI应用,点击发布渠道,点击免登录窗口,创建新连接,创建后点击开始使用按钮。
- 复制
base_url和share_id,后面需要配置到Chainlit的环境变量中

获取fastgpt的API_KEY
登录fastgpt后台,在工作台里,点击自己创建的AI应用,点击发布渠道,点击API访问创建,访问API的KEY.
- 只需要复制
API_KEY即可,后面需要配置到Chainlit的环境变量中

Chainlit网页搭建
创建一个文件夹,例如“chainlit_fastgpt”
mkdir chainlit_fastgpt
进入 chainlit_chat文件夹下,执行命令创建python 虚拟环境空间(需要提前安装好python sdk。 Chainlit 需要python>=3.8。,具体操作,由于文章长度问题就不在叙述,自行百度),命令如下:
python -m venv .venv
- 这一步是避免python第三方库冲突,省事版可以跳过
.venv是创建的虚拟空间文件夹可以自定义
接下来激活你创建虚拟空间,命令如下:
#linux or mac
source .venv/bin/activate
#windows
.venv\Scripts\activate
在项目根目录下创建requirements.txt,内容如下:
chainlit~=1.1.402
aiohttp~=3.10.5
requests~=2.32.3
literalai~=0.0.607
在项目根目录下创建app.py文件,代码如下:
import hashlib
import json
import os
from typing import Optional, Dictimport aiohttp
import chainlit as cl
import chainlit.data as cl_data
import requestsfrom fastgpt_data import FastgptDataLayer, now, share_id, app_name, welcome_textfastgpt_base_url = os.getenv("FASTGPT_BASE_URL")
fastgpt_api_key = os.getenv("FASTGPT_API_KEY")
fastgpt_api_detail = os.getenv("FASTGPT_API_DETAIL", False)cl_data._data_layer = FastgptDataLayer()
cl.config.ui.name = app_namedef download_logo():local_filename = "./public/favicon.svg"directory = os.path.dirname(local_filename)os.makedirs(directory, exist_ok=True)# Streaming, so we can iterate over the response.with requests.get(f"{fastgpt_base_url}/icon/logo.svg", stream=True) as r:r.raise_for_status() # Check if the request was successfulwith open(local_filename, 'wb') as f:for chunk in r.iter_content(chunk_size=8192):# If you have chunk encoded response uncomment if# and set chunk_size parameter to None.f.write(chunk)download_logo()@cl.on_chat_start
async def chat_start():if welcome_text:# elements = [cl.Text(content=welcomeText, display="inline")]await cl.Message(content=welcome_text).send()@cl.on_message
async def handle_message(message: cl.Message):msg = cl.Message(content="")url = f"{fastgpt_base_url}/api/v1/chat/completions"print('message.thread_id',message.thread_id)headers = {"Authorization": f"Bearer {fastgpt_api_key}","Content-Type": "application/json"}data = {"messages": [{"role": "user","content": message.content}],"variables": {"cTime": now},"responseChatItemId": message.id,"shareId": share_id,"chatId": message.thread_id,"appType": "advanced","outLinkUid": cl.context.session.user.identifier,"detail": fastgpt_api_detail,"stream": True}async for data in fetch_sse(url, headers=headers, data=json.dumps(data), detail=fastgpt_api_detail):delta = data['choices'][0]['delta']if delta:await msg.stream_token(delta['content'])await msg.send()@cl.header_auth_callback
def header_auth_callback(headers: Dict) -> Optional[cl.User]:print(headers)# 创建一个md5 hash对象md5_hash = hashlib.md5()user_agent_bytes = headers.get('user-agent').encode('utf-8')# 更新这个hash对象的内容md5_hash.update(user_agent_bytes)# 获取md5哈希值的十六进制表示形式md5_hex_digest = md5_hash.hexdigest()out_link_uid = md5_hex_digestprint("MD5加密后的结果:", md5_hex_digest)return cl.User(identifier=out_link_uid, display_name="visitor")@cl.on_chat_resume
async def on_chat_resume():passasync def fetch_sse(url, headers, data, detail):async with aiohttp.ClientSession() as session:async with session.post(url, headers=headers, data=data) as response:async for line in response.content:if line: # 过滤掉空行data = line.decode('utf-8').rstrip('\n\r')# print(f"Received: {data}")# 检查是否为数据行,并且是我们感兴趣的事件类型if detail:if data.startswith('event:'):event_type = data.split(':', 1)[1].strip() # 提取事件类型elif data.startswith('data:') and event_type == 'flowNodeStatus':data = data.split(':', 1)[1].strip()flowNodeStatus = json.loads(data)current_step = cl.context.current_stepcurrent_step.name = flowNodeStatus['name']elif data.startswith('data:') and event_type == 'answer':data = data.split(':', 1)[1].strip() # 提取数据内容# 如果数据包含换行符,可能需要进一步处理(这取决于你的具体需求)# 这里我们简单地打印出来if data != '[DONE]':yield json.loads(data)else:if data.startswith('data:'):data = data.split(':', 1)[1].strip() # 提取数据内容# 如果数据包含换行符,可能需要进一步处理(这取决于你的具体需求)# 这里我们简单地打印出来if data != '[DONE]':yield json.loads(data)-
传入的
model,temperature等参数字段均无效,这些字段由编排决定,不会根据API参数改变。 -
不会返回实际消耗
Token值,如果需要,可以设置detail=true,并手动计算responseData里的tokens值。
在项目根目录下创建fastgpt_data.py文件,代码如下:
import json
import os
import uuid
from typing import Optional, List, Dictimport requests
from chainlit import PersistedUser
from chainlit.data import BaseDataLayer
from chainlit.types import PageInfo, ThreadFilter, ThreadDict, Pagination, PaginatedResponse
from literalai.helper import utc_nowfastgpt_base_url = os.getenv("FASTGPT_BASE_URL")
share_id = os.getenv("FASTGPT_SHARE_ID")
now = utc_now()
user_cur_threads = []
thread_user_dict = {}def change_type(user_type: str):if user_type == 'AI':return 'assistant_message'if user_type == 'Human':return 'user_message'def get_app_info():with requests.get(f"{fastgpt_base_url}/api/core/chat/outLink/init?chatId=&shareId={share_id}&outLinkUid=123456") as resp:app = {}if resp.status_code == 200:res = json.loads(resp.content)app = res.get('data').get('app')appId = res.get('data').get('appId')app['id'] = appIdreturn appapp_info = get_app_info()app_id = app_info.get('id')
app_name = app_info.get('name')
welcome_text = app_info.get('chatConfig').get('welcomeText')def getHistories(user_id):histories = []if user_id:with requests.post(f"{fastgpt_base_url}/api/core/chat/getHistories",data={"shareId": share_id, "outLinkUid": user_id}) as resp:if resp.status_code == 200:res = json.loads(resp.content)data = res["data"]print(data)histories = [{"id": item["chatId"],"name": item["title"],"createdAt": item["updateTime"],"userId": user_id,"userIdentifier": user_id}for item in data]if user_cur_threads:thread = next((t for t in user_cur_threads if t["userId"] == user_id), None)if thread: # 确保 thread 不为 Nonethread_id = thread.get("id")if histories:# 检查 thread 的 ID 是否已存在于 threads 中if not any(t.get("id") == thread_id for t in histories):histories.insert(0, thread)else:# 如果 threads 是空列表,则直接插入 threadhistories.insert(0, thread)for item in histories:thread_user_dict[item.get('id')] = item.get('userId')return historiesclass FastgptDataLayer(BaseDataLayer):async def get_user(self, identifier: str):print('get_user', identifier)return PersistedUser(id=identifier, createdAt=now, identifier=identifier)async def update_thread(self,thread_id: str,name: Optional[str] = None,user_id: Optional[str] = None,metadata: Optional[Dict] = None,tags: Optional[List[str]] = None,):print('---------update_thread----------',thread_id)thread = next((t for t in user_cur_threads if t["userId"] == user_id), None)if thread:if thread_id:thread["id"] = thread_idif name:thread["name"] = nameif user_id:thread["userId"] = user_idthread["userIdentifier"] = user_idif metadata:thread["metadata"] = metadataif tags:thread["tags"] = tagsthread["createdAt"] = utc_now()else:print('---------update_thread----------thread_id ', thread_id, name)user_cur_threads.append({"id": thread_id,"name": name,"metadata": metadata,"tags": tags,"createdAt": utc_now(),"userId": user_id,"userIdentifier": user_id,})async def get_thread_author(self, thread_id: str):print('get_thread_author')return thread_user_dict.get(thread_id, None)async def list_threads(self, pagination: Pagination, filters: ThreadFilter) -> PaginatedResponse[ThreadDict]:threads = []if filters:threads = getHistories(filters.userId)search = filters.search if filters.search else ""filtered_threads = [thread for thread in threads if search in thread.get('name', '')]start = 0if pagination.cursor:for i, thread in enumerate(filtered_threads):if thread["id"] == pagination.cursor: # Find the start index using pagination.cursorstart = i + 1breakend = start + pagination.firstpaginated_threads = filtered_threads[start:end] or []has_next_page = len(paginated_threads) > endstart_cursor = paginated_threads[0]["id"] if paginated_threads else Noneend_cursor = paginated_threads[-1]["id"] if paginated_threads else Nonereturn PaginatedResponse(pageInfo=PageInfo(hasNextPage=has_next_page,startCursor=start_cursor,endCursor=end_cursor,),data=paginated_threads,)async def get_thread(self, thread_id: str):print('get_thread', thread_id)user_id = thread_user_dict.get(thread_id, None)thread = Noneif user_id:params = {'chatId': thread_id,'shareId': share_id,'outLinkUid': user_id,}with requests.get(f"{fastgpt_base_url}/api/core/chat/outLink/init",params=params,) as resp:if resp.status_code == 200:res = json.loads(resp.content)data = res["data"]if data:history = data['history']files = []texts = []for item in history:for entry in item['value']:if entry.get('type') == 'text':text = {"id": item["_id"],"threadId": thread_id,"name": item["obj"],"type": change_type(item["obj"]),"input": None,"createdAt": utc_now(),"output": entry.get('text').get('content'),}texts.append(text)if entry.get('type') == 'file':file = {"id": str(uuid.UUID),"threadId": thread_id,"forId": item["_id"],"name": entry.get('file').get('name'),"type": entry.get('file').get('type'),"url": entry.get('file').get('url'),"display": "inline","size": "medium"}files.append(file)thread = {"id": thread_id,"name": data.get("title", ''),"createdAt": utc_now(),"userId": "admin","userIdentifier": "admin","metadata": {"appId": data["appId"]},"steps": texts,"elements": files,}return threadreturn threadasync def delete_thread(self, thread_id: str):print('delete_thread')thread = next((t for t in user_cur_threads if t["id"] == thread_id), None)user_id = thread_user_dict.get(thread_id, None)if thread:user_cur_threads.remove(thread)if user_id:params = {'appId': app_id,'chatId': thread_id,'shareId': share_id,'outLinkUid': user_id,}requests.get(f"{fastgpt_base_url}/api/core/chat/delHistory",params=params)在项目根目录下创建.env环境变量,配置如下:
CHAINLIT_AUTH_SECRET="xOIPIMBGfI7N*VK6O~KOVIRC/cGRNSmk%bmO4Q@el647hR?^mdW6=8KlQBuWWTbk"
FASTGPT_BASE_URL="https://share.fastgpt.in"
FASTGPT_API_KEY="fastgpt-key"
FASTGPT_SHARE_ID=""
FASTGPT_API_DETAIL=False
- 项目根目录下,执行
chainlit create-secret命令,可以获得CHAINLIT_AUTH_SECRET FASTGPT_BASE_URL为你Fastgpt服务器,网页端分享地址的的base_url。FASTGPT_API_KEY为你Fastgpt服务器f发布渠道中->API访问的密匙。FASTGPT_SHARE_ID为你Fastgpt服务器f发布渠道中->免登录窗口中的url的中参数shareId=后面的值。
执行以下命令安装依赖:
pip install -r .\requirements.txt
- 安装后,项目根目录下会多出
.chainlit和.files文件夹和chainlit.md文件
运行应用程序
要启动 Chainlit 应用程序,请打开终端并导航到包含的目录app.py。然后运行以下命令:
chainlit run app.py -w
- 该
-w标志告知Chainlit启用自动重新加载,因此您无需在每次更改应用程序时重新启动服务器。您的聊天机器人 UI 现在应该可以通过http://localhost:8000访问。 - 自定义端口可以追加
--port 80
启动后界面如下:
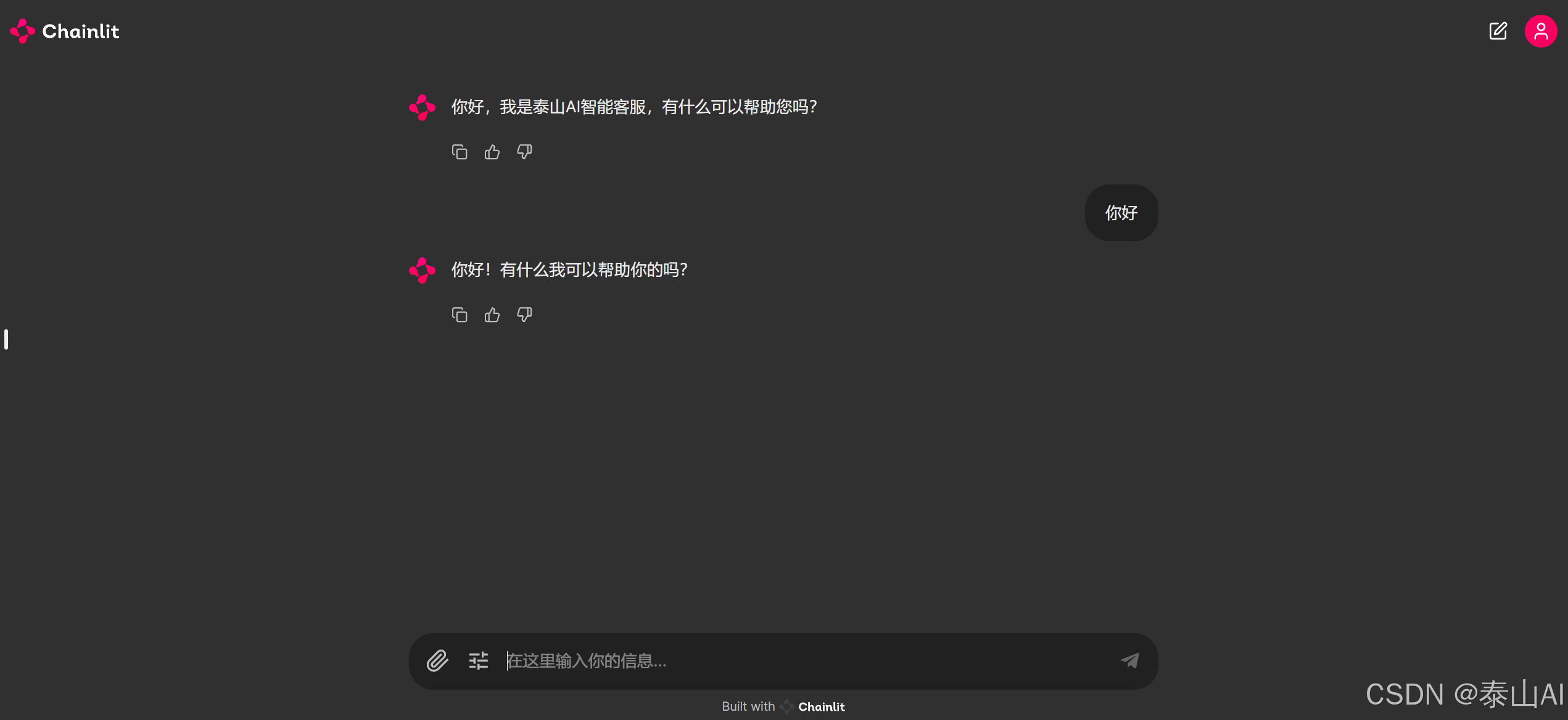
- 由于时间关系,这个应用和fastgpt的文件上传接口、语音对话还未实现,后续会在更新一次,实现完美对接!
相关文章推荐
《使用 Xinference 部署本地模型》
《Fastgpt接入Whisper本地模型实现语音输入》
《Fastgpt部署和接入使用重排模型bge-reranker》
《Fastgpt部署接入 M3E和chatglm2-m3e文本向量模型》
《Fastgpt 无法启动或启动后无法正常使用的讨论(启动失败、用户未注册等问题这里)》
《vllm推理服务兼容openai服务API》
《vLLM模型推理引擎参数大全》
《解决vllm推理框架内在开启多显卡时报错问题》
《Ollama 在本地快速部署大型语言模型,可进行定制并创建属于您自己的模型》
![[数据集][目标检测]街灯路灯检测数据集VOC+YOLO格式1893张1类别](https://i-blog.csdnimg.cn/direct/ad3532845c834a06bc2863a9ba997498.png)











![[Linux#47][网络] 网络协议 | TCP/IP模型 | 以太网通信](https://i-blog.csdnimg.cn/direct/1783339e86994d6ba4c8eda6b9075588.png)




![LCP:60 排列序列[leetcode-4]](https://i-blog.csdnimg.cn/direct/78539127ef4d45e299cf4dc70e292c69.png)