文章目录
- Redis计数器
- incr 指令
- 用户计数统计
- 用户统计信息查询
- 缓存一致性
- 小结
技术派项目源码地址 :
- Gitee :技术派 - https://gitee.com/itwanger/paicoding
- Github :技术派 - https://github.com/itwanger/paicoding
用户的相关统计信息
- 文章数,文章总阅读数,粉丝数,关注作者数,文章被收藏数、被点赞数量
文章的相关统计信息
- 文章点赞数,阅读数,收藏数,评论数

Redis计数器
- redis计数器,主要是借助原生的incr指令来实现原子的+1/-1,
- 更棒的是不仅redis的string数据结构支持incr,hash、zset数据结构同样也是支持incr的
incr 指令
Redis Incr 命令将 key 中储存的数字值增一
- 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
- 如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
- 本操作的值限制在 64 位(bit)有符号数字表示之内。
接下来看下技术派的封装实现
/*** 自增** @param key* @param filed* @param cnt* @return*/
public static Long hIncr(String key, String filed, Integer cnt) {return template.execute((RedisCallback<Long>) con -> con.hIncrBy(keyBytes(key), valBytes(filed), cnt));
}
用户计数统计
我们将用户的相关计数,每个用户对应一个hash数据结构
-
key: user_statistic_${userId}
-
field:
- followCount: 关注数
- fansCount: 粉丝数
- articleCount: 已发布文章数
- praiseCount: 文章点赞数
- readCount: 文章被阅读数
- collectionCount: 文章被收藏数
-
计数器的核心就在于满足计数条件之后,实现的计数+1/-1
-
通常的业务场景中,此类计数不太建议直接与业务代码强耦合,举个例子
-
用户收藏了一个文章,若按照正常的设计,就是再收藏这里,调用计数器执行+1操作
-
上面的这样实现有问题么?当然没有问题,但是不够优雅
-
比如现在技术派的设计场景,点赞之后,除了计数器更新之外,还有前面说到的用户活跃度更新,若所有的逻辑都放在业务中,会导致业务的耦合较重
-
技术派选择消息机制来应对这种场景(扩展一下,为什么大一点的项目,会设计自己的消息总线呢?一个重要的目的就是各自业务逻辑内聚,向外只抛出自己的状态/业务变更消息,实现解耦)
-
技术派写了如下监听器 :
/*** 用户操作行为,增加对应的积分** @param msgEvent*/
@EventListener(classes = NotifyMsgEvent.class)
@Async
public void notifyMsgListener(NotifyMsgEvent msgEvent) {switch (msgEvent.getNotifyType()) {// 文章新增评论或回复case COMMENT:case REPLY:CommentDO comment = (CommentDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + comment.getArticleId(), CountConstants.COMMENT_COUNT, 1);break;// 文章删除评论或回复case DELETE_COMMENT:case DELETE_REPLY:comment = (CommentDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + comment.getArticleId(), CountConstants.COMMENT_COUNT, -1);break;// 收藏文章case COLLECT:UserFootDO foot = (UserFootDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.COLLECTION_COUNT, 1);RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.COLLECTION_COUNT, 1);break;// 取消收藏case CANCEL_COLLECT:foot = (UserFootDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.COLLECTION_COUNT, -1);RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.COLLECTION_COUNT, -1);break;// 点赞case PRAISE:foot = (UserFootDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.PRAISE_COUNT, 1);RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.PRAISE_COUNT, 1);break;// 取消点赞case CANCEL_PRAISE:foot = (UserFootDO) msgEvent.getContent();RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.PRAISE_COUNT, -1);RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.PRAISE_COUNT, -1);break;// 关注case FOLLOW:UserRelationDO relation = (UserRelationDO) msgEvent.getContent();// 主用户粉丝数 + 1RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getUserId(), CountConstants.FANS_COUNT, 1);// 粉丝的关注数 + 1RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getFollowUserId(), CountConstants.FOLLOW_COUNT, 1);break;// 取消关注 case CANCEL_FOLLOW:relation = (UserRelationDO) msgEvent.getContent();// 主用户粉丝数 + 1RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getUserId(), CountConstants.FANS_COUNT, -1);// 粉丝的关注数 + 1RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getFollowUserId(), CountConstants.FOLLOW_COUNT, -1);break;default:}
}
不一样的地方则在于用户的文章数统计,因为消息发布时,并没有告知这个文章是从未上线状态到发布,发布到下线/删除,因此无法直接进行+1/-1 我们直接采用的是全量的更新策略
/*** 发布文章,更新对应的文章计数** @param event*/
@Async
@EventListener(ArticleMsgEvent.class)
public void publishArticleListener(ArticleMsgEvent<ArticleDO> event) {ArticleEventEnum type = event.getType();if (type == ArticleEventEnum.ONLINE || type == ArticleEventEnum.OFFLINE || type == ArticleEventEnum.DELETE) {Long userId = event.getContent().getUserId();int count = articleDao.countArticleByUser(userId);RedisClient.hSet(CountConstants.USER_STATISTIC_INFO + userId, CountConstants.ARTICLE_COUNT, count);}
}
用户统计信息查询
- 前面实现了用户的相关计数统计,查询用户的统计信息则相对更简单了,直接hgetall即可
@Override
public UserStatisticInfoDTO queryUserStatisticInfo(Long userId) {Map<String, Integer> ans = RedisClient.hGetAll(CountConstants.USER_STATISTIC_INFO + userId, Integer.class);UserStatisticInfoDTO info = new UserStatisticInfoDTO();// 关注数info.setFollowCount(ans.getOrDefault(CountConstants.FOLLOW_COUNT, 0));// 文章数info.setArticleCount(ans.getOrDefault(CountConstants.ARTICLE_COUNT, 0));// 点赞数info.setPraiseCount(ans.getOrDefault(CountConstants.PRAISE_COUNT, 0));// 收藏数info.setCollectionCount(ans.getOrDefault(CountConstants.COLLECTION_COUNT, 0));// 阅读量info.setReadCount(ans.getOrDefault(CountConstants.READ_COUNT, 0));// 粉丝数info.setFansCount(ans.getOrDefault(CountConstants.FANS_COUNT, 0));return info;
}
缓存一致性
- 通常我们会做一个校对/定时同步任务来保证缓存与实际数据中的一致性
用户统计信息每天全量同步
/*** 每天4:15分执行定时任务,全量刷新用户的统计信息*/
@Scheduled(cron = "0 15 4 * * ?")
public void autoRefreshAllUserStatisticInfo() {Long now = System.currentTimeMillis();log.info("开始自动刷新用户统计信息");Long userId = 0L;// 批量处理的用户数,每次处理 20 个用户int batchSize = 20;while (true) {List<Long> userIds = userDao.scanUserId(userId, batchSize);userIds.forEach(this::refreshUserStatisticInfo);// 如果用户数小于 batchSize,说明已经处理完了,退出循环if (userIds.size() < batchSize) {userId = userIds.get(userIds.size() - 1);break;} else {userId = userIds.get(batchSize - 1);}}log.info("结束自动刷新用户统计信息,共耗时: {}ms, maxUserId: {}", System.currentTimeMillis() - now, userId);
}/*** 更新用户的统计信息** @param userId*/
@Override
public void refreshUserStatisticInfo(Long userId) {// 用户的文章点赞数,收藏数,阅读计数ArticleFootCountDTO count = userFootDao.countArticleByUserId(userId);if (count == null) {count = new ArticleFootCountDTO();}// 获取关注数Long followCount = userRelationDao.queryUserFollowCount(userId);// 粉丝数Long fansCount = userRelationDao.queryUserFansCount(userId);// 查询用户发布的文章数Integer articleNum = articleDao.countArticleByUser(userId);String key = CountConstants.USER_STATISTIC_INFO + userId;RedisClient.hMSet(key, MapUtils.create(CountConstants.PRAISE_COUNT, count.getPraiseCount(),CountConstants.COLLECTION_COUNT, count.getCollectionCount(),CountConstants.READ_COUNT, count.getReadCount(),CountConstants.FANS_COUNT, fansCount,CountConstants.FOLLOW_COUNT, followCount,CountConstants.ARTICLE_COUNT, articleNum));
}
- 文章统计信息每天全量同步
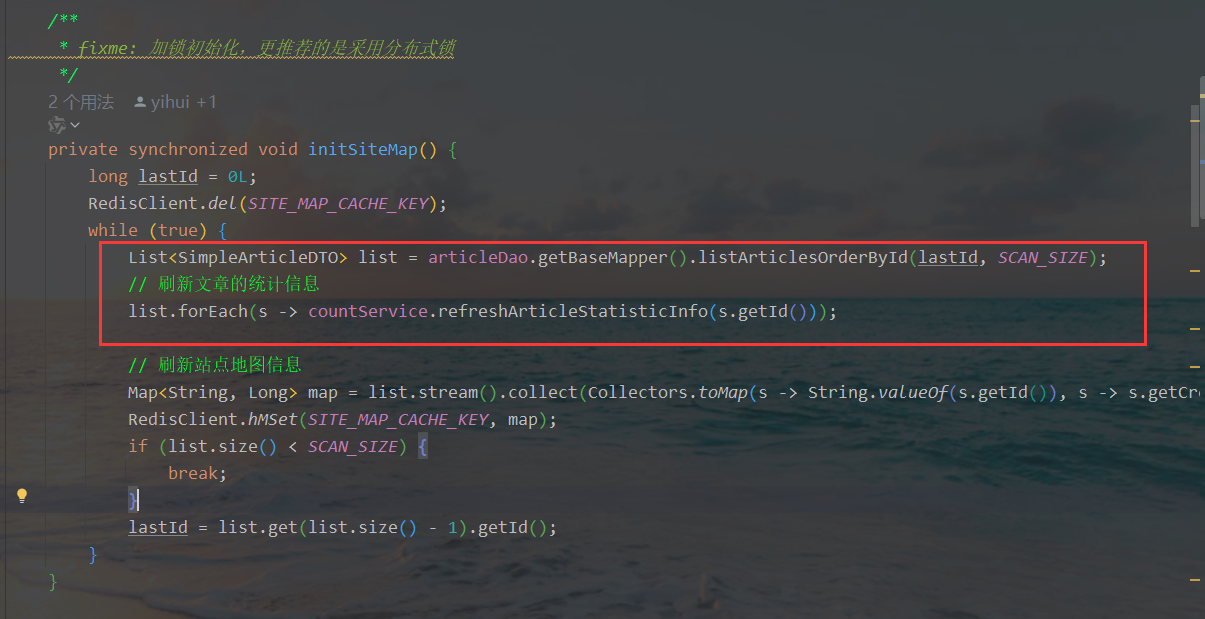
public void refreshArticleStatisticInfo(Long articleId) {ArticleFootCountDTO res = userFootDao.countArticleByArticleId(articleId);if (res == null) {res = new ArticleFootCountDTO();} else {res.setCommentCount(commentReadService.queryCommentCount(articleId));}RedisClient.hMSet(CountConstants.ARTICLE_STATISTIC_INFO + articleId,MapUtils.create(CountConstants.COLLECTION_COUNT, res.getCollectionCount(),CountConstants.PRAISE_COUNT, res.getPraiseCount(),CountConstants.READ_COUNT, res.getReadCount(),CountConstants.COMMENT_COUNT, res.getCommentCount()));
}
小结
-
基于redis的incr,很容易就可以实现计数相关的需求支撑,但是为啥我们要用redis来实现一个计数器呢?直接用数据库的原始数据进行统计有什么问题吗?
-
技术派的源码中,对于用户/文章的相关统计,同时给出了基于db计数 + redis计数两套方案
-
通常而言,项目初期,或者项目本身非常简单,访问量低,只希望快速上线支撑业务时,使用db进行直接统计即可,优势时是简单,叙述,不容易出问题;缺点则是每次都实时统计性能差,扩展性不强
-
当我们项目发展起来之后,借助redis直接存储最终的结果,在展示层直接获取即可,性能更强,满足各位的高并发的遐想,缺点则是数据的一致性保障难度更高**














![[数据集][目标检测]管道漏水泄漏破损检测数据集VOC+YOLO格式2614张4类](https://i-blog.csdnimg.cn/direct/e0833cdeb7e94eef895ce374e2b2b8ad.png)
![[windows][apache]Apache代理安装](https://i-blog.csdnimg.cn/direct/08ef6ff53e7d4f7d9c08a53fc8555b4d.png)