Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
3. 方法
3.1 概述
3.2 LDM
3.3 原型嵌入
3.4 类别特征正则化
3.5 对象特定损失
4. 实验
5. 局限性
0. 摘要
大规模文本到图像生成模型在文本到图像生成领域取得了显著进展,许多微调方法已经被提出。然而,这些模型通常在处理新颖对象时遇到困难,特别是在单样本场景中。我们提出的方法旨在以对象驱动的方式解决泛化和保真度方面的挑战,仅使用单个输入图像和对象特定的感兴趣区域。为了提高泛化能力并减轻过拟合,在我们的范例中,基于对象的外观和其类别初始化了一个原型嵌入,然后对扩散模型进行微调。在微调过程中,我们提出了一种类别特征正则化方法,以保留对对象类别的先验知识。为了进一步提高保真度,我们引入了对象特定的损失,这也可以用于植入多个对象。总体而言,我们提出的用于植入新对象的对象驱动方法可以与现有概念以及高度保真度和泛化性无缝集成。我们的方法优于一些现有的作品。代码将会发布。

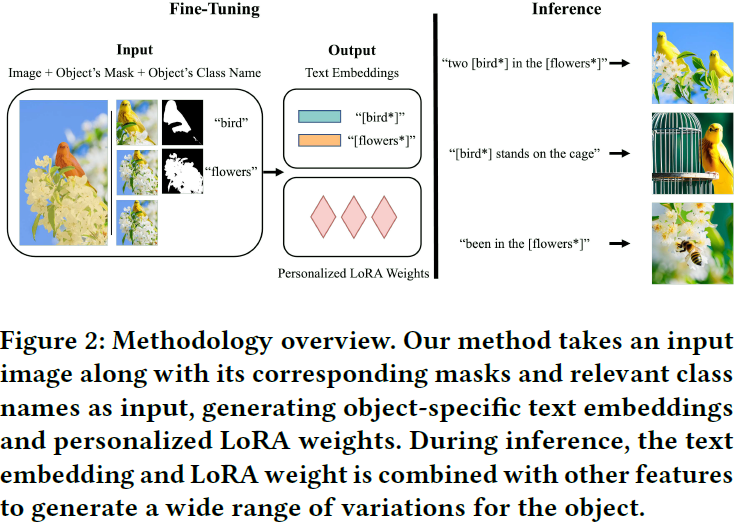
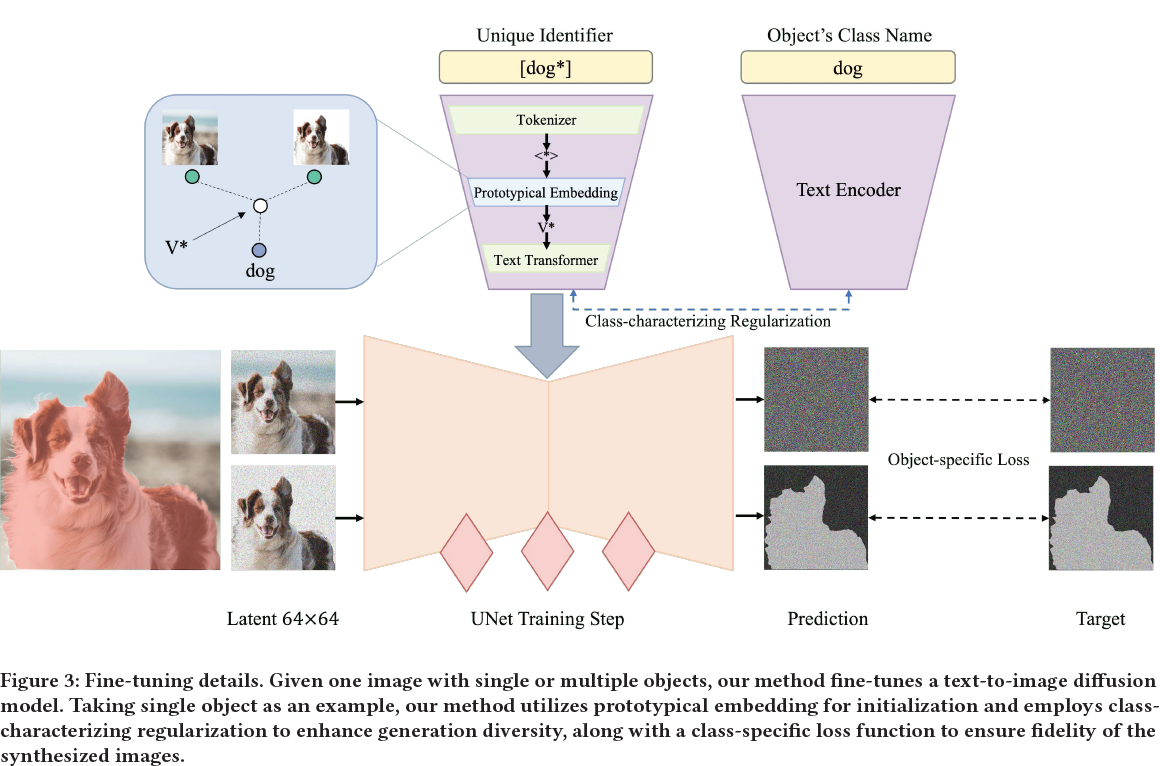
3. 方法
3.1 概述
我们提出的方法侧重于用户在一张图像中指定的单个或多个对象的对象驱动微调,如图 3 所示。为了克服现有微调方法的局限性,我们使用原型嵌入作为初始化嵌入,并提出了一个正则化损失函数,以增加生成图像的多样性并有效地保留预训练模型的先前知识。此外,我们引入了一个对象特定的掩码损失函数,用于合成高保真度的图像,也可用于多对象植入。在本节中,我们详细解释了提出的方法。
3.2 LDM
3.3 原型嵌入
在微调扩散模型时,通常会训练对象的文本嵌入。然而,当训练数据仅为一张图像时,有时会导致过拟合,使网络仅基于对象的文本嵌入生成输出,而忽略其他文本条件。在实践中,适当初始化文本嵌入可以加速网络的拟合并缓解过拟合,例如文本反演(Textual Inversion,TI)[11] 根据对象类别初始化文本嵌入。在这项工作中,为了实现更有效的初始化,我们基于输入图像的嵌入和类别名称的文本嵌入(例如,狗)找到原型嵌入。在开始扩散模型的训练之前,我们通过以下方式计算原型嵌入:

其中,𝑥 是训练图像,使用 CLIP [24] 的图像编码器 I 和文本编码器 T 来获取整个图像嵌入 I(𝑥),对象掩码图像嵌入 I(𝑥_𝑚),T(𝑐_𝑐) 是对象的类别名称文本嵌入,𝜃_𝑚 是嵌入融合的方式,例如平均。我们的目标是通过这个损失函数获得一个原型文本嵌入 T(𝑐_𝑝) ,它与目标图像嵌入和类别文本嵌入相似,作为初始化。
3.4 类别特征正则化
此外,为了保留预训练模型中对象类别的合成能力,我们在训练过程中使用类别特征正则化调整文本嵌入。类别特征损失的公式如下:
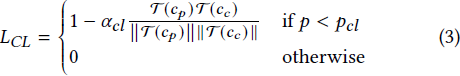
其中,T(𝑐_𝑐) 是对象的类别名称文本嵌入,𝛼_𝑐𝑙 表示余弦损失的权重,𝑝 ∼ 𝑈𝑛𝑖(0, 1),而 𝑝_𝑐𝑙 是可调的阈值。在这个背景下,需要预先确定每个对象的类别名称。进一步的实验表明,引入这个损失函数可以提高合成中的泛化能力。
3.5 对象特定损失
我们的任务是将选定的对象植入模型的输出领域,并与唯一标识符绑定。注意,所选对象通常是训练图像的部分而不是整个图像,因此我们提出了选定对象植入的对象特定损失,选定对象的保真度被提高。首先,我们使用图像分割算法,例如 SAM [17],来获取对象的掩码图像 𝑚。这些掩码图像被引入潜在空间和训练过程中。单对象植入的训练如下:
![]()
![]()
![]()
其中,𝑐_𝑚 是掩蔽的对象的文本条件,对象目标噪声 ˜𝜖,以及被掩蔽的潜在表示 ˜𝑧。我们的目标是在执行损失计算时专注于掩码区域。
(注:˜𝜖 是参考的对象区域噪声与预测的对象以外区域的噪声的组合)
此外,对于多对象植入,我们进行对象特定损失函数的组合,假设有一组 𝑟 个要植入的对象,并且每次取 𝑘 个不同的对象的子集 𝑆,𝑘 组合的数量是 𝐶^𝑘_𝑛。因此,在一次训练的步骤中,总体对象特定损失为:
![]()
请注意,对于每个掩码,文本条件 𝑐_𝑚,𝑖 是不同的,而全局文本条件 𝑐 基于所有对象的唯一标识符。
4. 实验






5. 局限性
我们还发现我们的方法存在一些局限性,例如对于具有复杂边缘的对象,掩码区域存在错误,有时会导致生成图像边缘质量的降低。此外,在植入较小对象时,生成图像的保真度稍有降低。为了解决上述问题,未来的工作将致力于改进获取掩码图像的方式,并为对象添加多尺度感知机制。