本文主要文章是解决蚂蚁金服携手上海财经大学,共同出具大预言模型白皮书一文中的部分模型问题。
01 Slef-Attention
注意力机制,注意力权重可以看作是输入对输出的重要程度。这里注意,所谓注意力,即模型认为该单词有多值得被注意。该方法总,使用最广的是二分图、热力图。
自注意力(Self-Attention),模型动态计算序列内部信息之间的权重,能够建模变长序列内部的依赖关系。相比卷积神经网络,自注意力模型能够将卷积核的固定长度感受野扩大到输入序列长度的范围;相比循环神经网络,自注意力模型对长距离依赖有更强的捕获能力,并且能够并行计算。
基于以上优势,自注意力模型 被广泛应用于序列数据建模领域,自然语言处理领域中著名的 Transformer 模型是自注意力模型的典型代表。
注意力机制的优势可以归纳为以下三点。
(1)注意力机制能够有效地使模型忽略输入数据中的噪声部分,从而提升信噪比。
(2)注意力机制可以为输入数据中不同元素分配不同的权重系数,以突出与任务最相关的信息元素。
(3)注意力机制为模型结果带来了更好的解释性。例如,在翻译任务中,分析句子中不同单词的权重系数,可以找出句子中的关键词。
02 什么是 BERT 模型?
BERT
BERT,Bidirectional Encoder Representations from Transformers,不仅仅是机器学习术语海洋中的另一个缩写。它代表了机器理解语言方式的转变,使它们能够理解构成人类交流丰富而有意义的复杂细微差别和上下文依赖关系。BERT 核心是由 Transformer 驱动,也是一种神经网络模型。其中包含 Self-attention,使得 BERT 依据双向性质(上下文)作出判断,衡量重要性。这就像 BERT 反复阅读句子以深入理解每个词的作用。
模型效果
考虑句子:“The ‘lead’ singer will ‘lead’ the band.”传统模型可能难以处理“lead”这个词的歧义。然而,BERT轻松地区分出第一个“lead”是名词,而第二个是动词,展示了其在消除语言结构歧义方面的能力。BERT 是机器理解人类语言本质的一个范式转变。
掩码语言模型 Mask Language Model, MLM
MLM 可以将文本分为“有意义”的块, WordPiece Tokens:
[“Chat”, “##G”, “##PT”, “is”, “fascinating”, “.”]
注意,这其中还有单词标准化的步骤。例如,将单词回复成一般现在时。
我们在开头添加特殊token如[CLS](代表分类),在句子之间添加[SEP](代表分隔)。格式化Tokens:
[“[CLS]”, “Chat”, “##G”, “##PT”, “is”, “fascinating”, “.”, “[SEP]”]
MLM 怎么“教”BERT 模型理解句子?
在其训练过程中,一些单词在句子中被掩码(替换为[MASK]),BERT学习从上下文中预测这些单词。这有助于 BERT 理解单词如何相互关联,无论是在之前还是之后。BERT 随机选择一定比例的 token 进行掩码操作。
原始句子:“The cat is on the mat.”
掩码句子:“The [MASK] is on the mat.”
基于任务,微调 BERT
BERT有不同的变体,如BERT-base、BERT-large等。BERT 微调的任务称为“下游任务”。示例包括情感分析、命名实体识别等。微调涉及使用特定任务的数据更新BERT的权重。
Self-Attention
查看句子中的每个单词,根据其重要性决定 应该给予其他单词多少注意力。这样,BERT可以关注相关单词,即使它们在句子中相距甚远。当 BERT 读取一个单词时,它不是孤立的;它意识到 上下文。这样,BERT 生成的嵌入考虑了单词的整个上下文。打个比方,这就像理解一个笑话不仅通过笑点,还通过铺垫。
训练
我们将揭示 BERT 训练过程的复杂性,包括其预训练阶段、掩码语言模型(MLM)目标和下一句预测(NSP)目标。
BERT 始于预训练,让模型预测缺失单词。具体做法,在预训练期间,BERT被给予一些单词被掩码(隐藏)的句子。然后它尝试根据上下文预测那些掩码单词。
下一句预测(NSP)目标:掌握句子流。在NSP目标中,BERT被训练来预测一个句子是否跟随另一个句子(之后我们将看到,去掉预测句子之间关系,会产生什么效果)。句子和句子之间关系识别,可以让 BERT 理解更长的句子。
BERT嵌入
嵌入:上下文词嵌入、WordPiece 分词、位置编码。
每个单词只有一个 token,BERT根据单词在句子中的上下文创建不同的嵌入,每个单词的表示更加细致,受周围单词的影响。
WordPiece分词:处理复杂词汇。BERT 分词的时候,可以想象成拼图,使用 WordPiece 分词将单词分解成【子词】 —— 对于处理长而复杂的单词、处理以前未见过的单词,特别有用。
位置编码被添加到嵌入中,以给BERT这种空间意识。
BERT 高级技巧
深入探讨微调策略、处理词汇表外单词、领域适应以、从 BERT 中进行知识蒸馏的策略。
微调:你不仅可以微调最终的分类层,还可以微调中间层。尝试不同层的学习率,找到最佳组合。
表外单词(OOV):可以使用 WordPiece 分词法将其拆分为子词,或用特殊标记(如“[UNK]”)替换它们。
领域知识:通过让 BERT 接触领域特定的文本,它学会了理解该领域的独特语言模式。之前讨论的攻击防御,针对的是【领域知识】。
知识蒸馏:训练一个较小的模型(学生)来模仿较大的预训练模型(教师)如 BERT 的行为。不仅学习教师的预测,还学习其信心和推理。若资源受限,可以考虑使用。
BERT 的能力更上一层楼,包括 RoBERTa、ALBERT、DistilBERT 和 ELECTRA。
03 RoBERTa
文章工作:
- 用更长的时间,更大的batch size,更多的数据进行训练
- 去掉BERT中的NSP目标(next sentence prediction)
- 在更长的句子上进行训练
- 根据训练数据动态地改变mask的模式
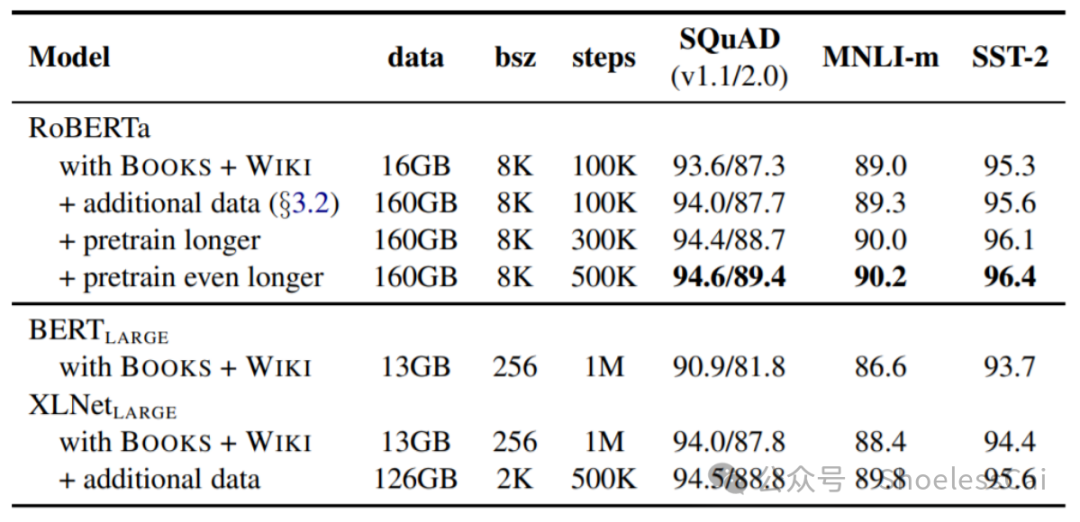
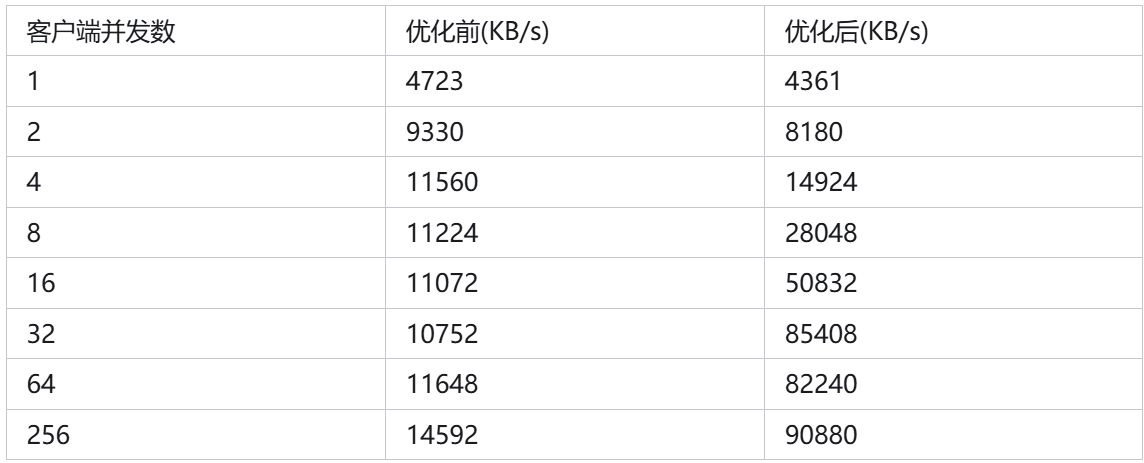
结果也很显然,团队给出 Batch Size 和 Steps 之前的成本权衡。8 * 32GB 英伟达 GPU,做该论文实验。
04 DetectGPT

识别概率函数(probability function)性质,并应用在识别 【生成文本】 和 【真实文本】上。文章 DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature 定义了新的标准,称为“负曲率标准” curvature-based criterion ,用于识别 【真实文本】。
这是零样本算法,一篇语料进来之后,无需其他数据,直接自己对于语料进行修正,生成其他语料进行对比。因为没其他样本,因此很依赖于基本假设。这个假设就是,基于【生成文本】的 Object Function 会有更多“负曲率点”。这时候,我的目标不是找到 Optimal,而是判别是否存在更多“负曲率点”。
文章还揭示一个亮点,其目标函数选用的,能使得二阶部分得以估算,若 H 为 Hessian 矩阵,z 为基于特征的参数向量,则曲率差异可表示为 z.THz。最后是用 H 的 trace 去替代对原来语料干扰之后所产生的差异。注意,这个 Hessian 阵可以估计出来,也是这个文章的亮点。

每个改动都要算差异,给出 N 个改动之后,基于 Object Funtion 生成 Score,再判断几个【真实文本】,DetectGPT 就有区分出 【生成文本】的能力了。
还有一点,这个 DetectGPT 必须和基础模型一起使用。
我们看一下实验结果。

在 XSum, SQuAD, WritingPrompt 上,无论基础模型是什么,表现都是占优的

在 XSum, SQuAD, WritingPrompt 上,改进 BERT 即 RoBERTa 上并没有提升太多识别能力
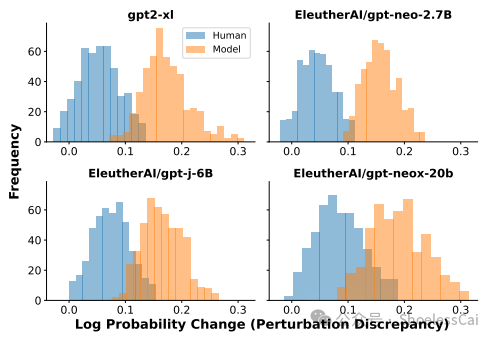

比较 Human 和 Model 两种语料,分数高的是 Model 语料。这两个分布叠加的部分越少越好

基本思想,对原始语料作一部分修改,输入模型计算分数,计算分数差异 d,做 N 次修正之后,产生 N 个差异 d1, … ,dn。对这 N 个样本计算标准差,再判断这个标准差是否到达标准。如果到达标准,说明是【生成文本】,如果没到标准就属于【真实文本】。
我在录音里说到,Model 样本代入时候,会有凹点。我是这么思考的,多维函数包括内部的,如果 Model 点代入应该在内部的概率更高,而 Human 会有更高概率处于函数表面。
05 ELECTRA
Electra主要针对MLM只对15%MASK的token进行训练导致训练低效的问题,通过两段式的训练,也实现了在下游任务中和MASK解耦,按论文的效果是只用1/4的时间就可以媲美Bert。
Eletra的预训练模块由以下两部分构成,分别是生成replace token的Generator,以及判别每个token是否是原始token的Descriminator,我们分别看下各自的实现。Generator的部分和Bert是基本一致,每次随机MASK15%的token,然后Generator去预测可能的原始token,所以Generator部分就是Bert的MLM任务。Descriminator的输入是Generator的预测结果,判别器负责判断每个token是否是原始的token,注意如果generator预测正确,则该token也是原始token,所以是一个二分类的判别任务。
Final Loss = Generator Loss + Descriminator Loss

06 GAN
生成对抗网络(GAN)是深度学习的一种创新架构,由Ian Goodfellow等人于2014年首次提出。其基本思想是通过两个神经网络,即检测器(Generator)和复述器(Discriminator),相互竞争来学习数据分布,分别完成生成数据,区别数据的作用。GAN 无需对数据分布进行假设。


G 最大化生成以假乱真的生成样本,D最小化自己判别错误的概率。我们这样理解 GAN,如果 z 为噪声,x 为输入的样本(数据),这个最小最大的双方博弈问题,刻画成
min{ max{ V(D, G) } } = E[ lg(D(x)) ] + E[ lg( 1-D(G(z)) ) ]
训练过程,先固定 G 再训练 D,更新 D 参数,固定 D 参数,训练 G。 Goodfellow 已经证明,当且仅当 p_z = p_data,原来的最优化问题存在最优解,达到纳什均衡,此时模型学会了真实样本 p_data。
GAN 迭代到后来未必收敛,我们首先看收敛的定义。
通常模型的收敛条件可以有以下3个:
1.loss小于某个预先设定的较小的值
2.两次迭代之间权值的变化已经很小了
3.设定最大迭代次数,当迭代超过最大次数就停止
由于 GANs采用对抗学习的方法,导致模型收敛性的不稳定,虽然 GANs在纳什均衡时达到最优,但是只有当梯度下降在凸函数的情况下才能保证实现纳什均衡。评注:该博弈收敛到纳什均衡,条件是凸函数。凸性不满足,可能不收敛。
复习一下线性回归模型的误差分解。
SST,样本与样本均值之间误差;
SSE,预测值与样本值之间误差;
SSR = SST - SSE
一些改进算法,由于时间关系,只能在这里略作介绍。
Nowozin 等人对 Nguyen 等人提出的变散度估计框架进行扩展,提出 f - GANs 模型,将散度估计扩展到模型估计,并称这种新方法为变分发散最小化(variable dispersion minimization,VDM),并证明了生成对抗训练是 VDM 框架的一个特例。
深度卷积对抗生成网络(deep convolutional GANs,DCGANs)。
Mirza 和 Osindero 提出了一种给 GANs 加上约束条件的模型,称为 CGANs(conditional GANs)。CGANs 就是一种带条件约束的 GANs,在 G 和 D 的模型中均引入条件变量 y,通过将 y 作为 G 和 D 输入层的一部分来进行调节,以此提高对模型的控制。
Karacan 等人利用反卷积神经网络和卷积神经网络构造了新的条件 GANs 属性-布局 条件生成对抗性网络(attribute-layout conditioned GAN,AL-CGAN)。
AL-CGAN 模型被拆解成两部分研究,即单属性条件的 A-CGAN 模型和单空间布局条件的 L-CGAN 模型。
Zhang等人,提出将 self-attention 机制加入 GANs中,让生成器和判别器可以自动学习图像中的重要目标,形成了模型 SAGAN(self-attention GAN)。SAGAN 克服了传统 GANs 模型均在 低分辨率特征图的空间局部点上,继续生成 高分辨率 的细节的缺陷。SAGAN 的判别器可以判别两幅具有明显差异的图像是否具有一致的高度精细特征,但仍有很大的提升空间。
07 WaterMarking
Pretalk
低小微服务,以及本科以上创始人路子。
水印算法介绍,来自机器之心。
论文原文的解读,阅读原文还是挺有必要的,对算法会更加深刻。
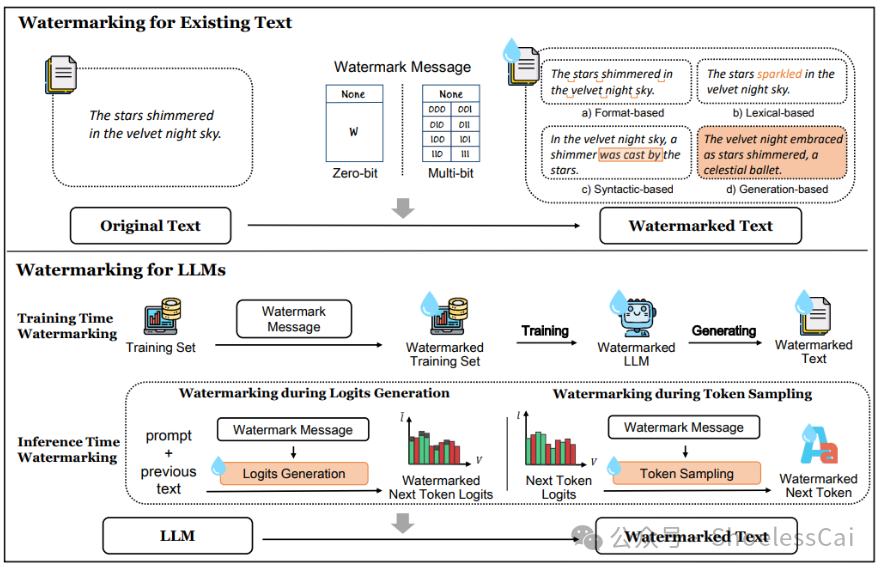
文本水印是一种信息隐藏技术,起源可以追溯到上个世纪 90 年代。它通过将机密信息(水印)嵌入文本中,实现了在共享水印规则的个体之间进行安全、隐式的消息传递。水印应具备隐蔽性、鲁棒性。
这里进一步对水印技术作阐述,在《A Survey of Text Watermarking in the Era of Large Language Models》,2023 年 12 月出版的文章中提到。水印要保证,对文本质量的影响尽量小,以及对水印移除之后,文本的稳定性要保证。这里的 Robustness 暂且理解为,文本意思不改变(原文:Robustness to watermark removal attack)。 基于规则的水印方法,通过替换、插入、删除、单词变形等操作,使得生成文本具有特定的模式或结构 —— 在文本中不可见,但能被计算机识别。
基于统计的水印方法,调整解码过程中 输出文本的概率分布(以这种方式作为水印),利用统计方法进行检测。
水印方案,水印添加阶段,估算下一个单词的 logit,依据一定的算法,将下一个单词的红色和绿色的概率估计出来(Well, simply because of logit),绿色代表正确。文本水印检测阶段,计算文本中来源于红色和绿色列表的单词所占比例,通过统计显著性检验,检验文本是造出来的,还是自然语言的。

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。