文章目录
- 1. 第一印象
- 2. 堆之合并
- 3. 奇中求正
- 4. NPL
- 5. 左倾性
- 6. 左展右敛
1. 第一印象
在学习过常规的完全二叉堆之后,我们再来学习优先级队列的另一变种,也就是左式堆。所谓的左式堆,也就是在拓扑形态上更加倾向于向左侧倾斜的一种堆,
比如这就是一个左式堆由生到长,直至灭亡的整个生命过程。

可以看到,相对于常规的完全二叉堆,左式堆的确显得有些别致。
那么,为什么要引入这一新的变种呢?让我们从它的设计动机以及结构定义说起。
2. 堆之合并

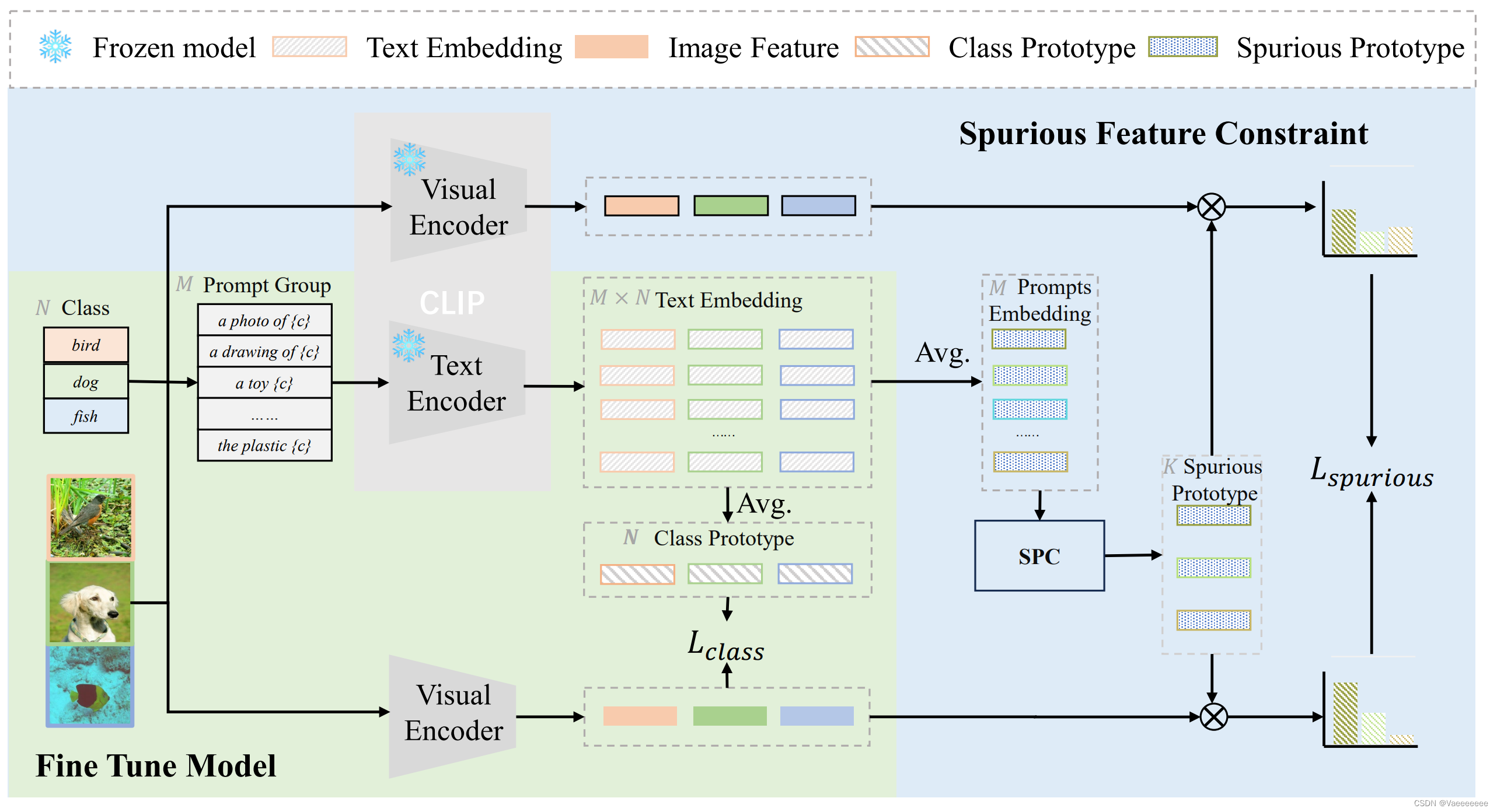
引入左式堆的动机非常直截了当,一言以蔽之,也就是为了能够有效地完成堆合并。具体的,对于任何的堆A 与堆 B,我们如何才能快速地将它们合二为一?
稍加思索,你可能会认为这并不是什么问题,因为借助已掌握的方法,我们完全可以实现这个功能。然而很遗憾,回到我们这门课程的核心,也就是计算效率。我们会发现已有的方法都不足用。
- 比如,可能会在两个堆中选择更大的那个作为基础,然后将另一堆中的元素逐一地取出并加入到前者当中,当更小的那个堆缩减为空时,也就自然完成了整体的合并。整个算法的描述也异常的简练,实际上主体的操作完全可以汇总为这样一句 A.insert(B.delMax())。
然而我们很快就会看到这个算法的效率是很低的,为此我们不妨将两个堆的规模分别记作 n 和 m,并且不失一般性地假设前者不小于后者,于是整个算法共需迭代 m 次,在每一次迭代中为了从 b 中摘除最大元,我们需要花费 log m 的时间,而为了将这个元素汇入到 a 中,我们又需要花费 log (n + m) 时间,总体而言我们大致需要 m *log n 的时间。至此,我相信你也会对这个效率不甚满意。是的,因为它的确存在改进的空间与可能。
- 是的,或许会想起 Floyd 批量建堆算法,实际上更为高效的一种办法就是将这两个堆中的元素首先简单地混合起来,然后借助 Floyd 算法将这 n + m 个元素整理为一个完全二叉堆,。
你应该记得 ,Floyd 算法只需线性时间,这一算法的效率明显优于此前的那个算法。然而即使是这个线性的效率,也依然不能令我们满意。你能看出我们不满意的原因吗?
没错,作为 Floyd 算法的输入在默认情况下,所有的元素都是无序排列。然而现在却不是这样,事实上它们被分成了两组,而且我们已经分别知道了它们内部的偏序关系,很遗憾刚才这个线性的算法却没有利用到我们已掌握的这些信息。
因此从这一角度出发,我们完全有理由相信应该会存在更为高效的数据结构及相应的算法。事实上,左式堆正是问题的答案。
3. 奇中求正

事实上,所谓的左式堆,也就是在保持堆序性的前提下,附加某种新的约束条件,从而使得在堆的合并过程中,我们只需调整少量的节点,事实上,只要这种结构及相应的算法设计得当,我们完全可以将所涉及的节点数目控制在 log(n) 的范围内。
-
那么新引入的约束条件是什么呢?
一言以蔽之,也就是所谓的单侧倾斜, 比如沿用发明者所确定的惯例,堆中各节点的分布会偏向于左侧,而相关算法之所以能够高效的诀窍在于,所有的合并操作只会涉及到全堆的右侧部分。比如这就是左式堆的典型图解,所谓的向左侧倾斜,类比于书法,就相当于把撇写得更长,而捺写得更短。准确地讲,左式堆可以将右侧肩部的长度严格地控制在大 O 意义下的 log(n) 以内。可想而知,果真如此的话,我们就可以自然地将整体的时间复杂度控制在 log(n) 的范围之内。相对于我们刚才所介绍的那个线性算法,这不得不说是一个巨大的改进。
-
那么这样一种特性是如何做到的呢?
现在回答这个问题还嫌过早,因为我们首先还需要回答另一个问题。我们注意到如果真的有这样一个堆,那么它已经断乎不可能继续是一棵完全二叉树,也就是说尽管在此堆序性还有可能延续,而结构性却已荡然无存,无从谈起了。是的,的确如此。然后我们需要明白的是,对于堆结构而言,只有堆序性才是其本质的要求,而结构性却不是,在必要的时候结构性完全是可以牺牲掉的。
4. NPL

为了度量和判断左式堆的单侧倾斜性,我们需要引入一个概念,也就是所谓的"空节点路径长度"。
为便于讲解和理解,继续沿用之前在红黑树和 B 树中已经多次采用的一个技巧,也就是通过引入足够多个外部节点,将整个堆假想地转换为一棵真二叉树。
~
比如,在上图中所有深色的节点都是原有的真实存在的节点,而所有浅色,也是方形的节点都是我们假想的引入的外部节点。可以看到经过这样一个转换,的确所有节点的度数都变成了偶数。
那么所谓的空节点路径长度(Null Path Length) 又是如何定义的呢? 首先作为基础,对于刚刚引入的每一个外部节点而言,其 NPL 值都统一设作0,而对于任何一个原本就存在的内部节点而言,为了确定它的 NPL 值,我们需要找到它的左孩子以及右孩子,并且在其中挑选出更小的 NPL 值。在已知的基础增加一个单位。
看到这个定义的表达式,你或许会想起点什么。没错,节点的高度。事实上,只要将这个 min() 换成 max(),也就是不折不扣的高度。通过这样的对比和类比,希望能够对这两个概念有更深刻的认识。
就这里的 NPL 而言,我们不难验证以下两个事实:
-
首先,任意节点 x 的NPL 值,必然等于 x 到所有外部节点的最近距离,比如任何一个外部节点的 NPL 值之所以为0,是因为它到所有外部节点的距离就是它自己到自己的距离,这个距离自然是0。
再来看这个节点(上图第三排由左往右第3个)它的 NPL 值为什么是2呢?因为尽管它有一个外部节点的后代与它的距离为3,但这却不是最近的距离,实际上最近的距离应该实现于这样三个后代外部节点,而且这个距离恰好是2。
类似地,这个例子中的根节点 NPL 值之所以为3,是因为这些外部节点到它的距离最近,而且这个距离都是3。
-
另一个可以验证的事实是,对于任何一个 x 而言,它的 NPL 值也是以它为根的那棵最大满树的高度。
回到我们刚才的这个实例,依然考察 NPL 值为2的这个节点(上图第三排由左往右第3个),它的 NPL 值为2,我们也可以理解为存在一棵以它为根的高度为2的满树。
事实上,对于其他的节点,也是如此:这个节点的 NPL 值为2(上图第二排由左往右第1个),是因为以它为根的极大满子树的高度也是2。而根节点的 NPL 值为3,也可以理解为以它为根的极大满子树的高度也是3。
至此,我们已经建立了 NPL 值这样一个重要的指标。以这个指标作为基准,我们就来度量堆结构的倾斜性。
5. 左倾性

是的,借助 NPL 这个指标,我们就可以简明地定义什么叫做左倾。也就是说对于任何一个节点 x, 如果在 NPL 的意义上,它的左孩子不小于它的右孩子,我们就称之为左倾。 如果在一个堆中,任何内部节点都是左倾的,我们就称这个堆为左倾堆,或者左式堆、左撇子堆。
当然根据 NPL 的定义,既然每个节点 x 的 NPL 值都是在它的孩子中间取一个小者,再累计上 1 个单位,于是很自然地在这个递推式中,我们就只需考虑每个节点的右孩子,而忽略它的左孩子。
不难确认,所谓的"左倾性"与我们此前的堆序性是彼此相容而不矛盾的。
既然左倾性是必须处处满足的,所以我们也自然地可以推知,任何一个左式堆的任何一个子堆必定依然是左式堆。
不难理解,作为左式堆,它更倾向于将更多的节点分布于左侧的分支,正像我们最初所希望的那样。然而需要指出的是,这只是一个大致的倾向,事实情况未必严格如此。
可以进一步来思考这样两个问题:
- 也就是在左式堆中,是否左子堆的规模总是大于右子堆?
- 另外左子堆的高度是否也必然总是大于右子堆?
在这里我们也给出了一个左式堆的具体实例(上图),而刚才两个问题答案也就藏在这个实例当中。
6. 左展右敛

实际上对于左式堆而言,左子堆和右子堆在规模和高度上的差异并不是那么重要,真正重要的是全堆的右侧链。
在以 x 为根的任何一个子堆中,从这个节点出发,一路向右,不断前行所确立的那个分支就称作为右侧链。
特别地,对于全树根节点而言,它的右侧链的终点必然是全堆中深度最小的一个外部节点。
比如在上图中,相对于根节点 r,它所对应的右侧链的终点应该是这个外部节点。
刚刚介绍过,在左式堆中 r 的 NPL 值必然是在它的右孩子基础上累进一个单位。而它的右孩子也必然是在它的右孩子基础上累进一个单位。
如此递推,可以得知所谓 NPL(r)值必然是在这个终端节点, NPL 值也就是0的基础上不断累进而得。因此,如果 r 的 NPL 值为 d,则不仅意味着这个外部节点的深度也是 d,而且更重要地,按照我刚才的结论,必然存在一棵以 r 为根的高度为 d 的极大满子树。这一点对于左式堆来说至关重要,事实上这就意味着在左式堆中应该包含足够多个节点。
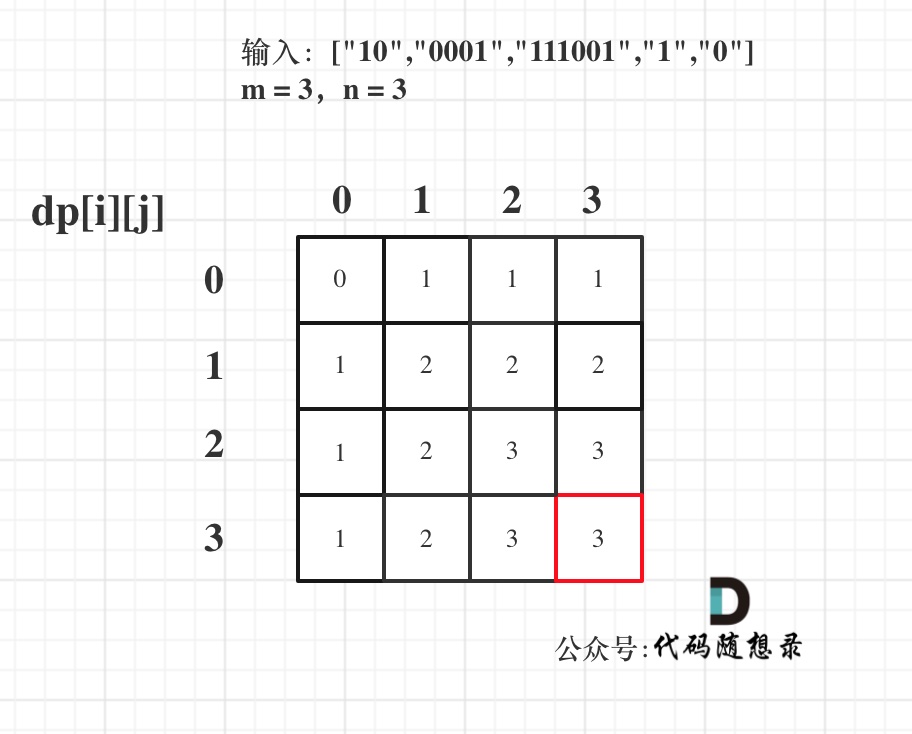
因为即便我们只记录这棵满子树,也至少应该有 2 d + 1 − 1 2^{d + 1} - 1 2d+1−1 个节点。当然,其中也至少包含 2 d − 1 2^d - 1 2d−1个内部节点。没错,如果根节点的 NPL 值为 d,那么其中就至少含有 2 d 2^d 2d个节点。
反过来,如果将左式堆的规模固定为 n,那么右侧链的长度 d 也就至多不过 log n。没错,右侧链的长度至多为 log(n)。这难道不正是我们最初的设计目标吗? 因此进一步地,如果我们所设计的堆合并算法的确也能将操作的范围限定在右侧链,那么相关算法的复杂度就很自然地也同样可以控制在log(n)的范围。那么这样的算法到底是如何运转的呢?