一、本次教程是给谁的?
如果你点进了这篇教程,相信你已经知道so-vits-svc是什么了,那么我们这里就不过多讲述了。如果你还不知道so-vits-svc能做什么,可以去b站搜索一下,你大概率会搜索到一些AI合成的音乐,是的简单来讲,so-vits-svc是一个训练并且推理声音的开源项目。它能够模仿某些角色的声音来唱歌或者单纯的文字朗读。那么,我们回到正题,本次教程是给谁的?如果你是一位开源项目爱好者并且有项目部署的经验,那么本次的教程可以作为你的参考。如果你是以为音乐爱好者,并且没有计算机基础,那么你可能需要花一些时间来学习计算机基础,在拥有了计算机基础以后,可以跟着本教程尝试部署so-vits-svc,但是如果你没有太多的时间,可能这个项目的一键包更适合你。如果你是以为ACG爱好者,想使用本教程部署so-vits-svc,并且通过这个项目推理自己喜欢的角色的声音,那么你也需要一些计算机基础,如果你时间有限,我同样建议你使用so-vits-svc的一键包。总的来说,不管是哪一类人群,不管声音推理是你的专业还是爱好,在部署so-vits-svc时,你都需要一定的计算机基础对编程语言有一定的了解并且具有解决问题的能力。
二、关于细节和遇到问题的解决方案
在本次教程之前,我已经在别的教程中讲述过pytorch的安装以及conda环境的安装,在本次教程中,我也会将往期的教程放在对应的位置。这次教程很详细,但是不会像每个单独教程那么详细。如果你想看到更多的细节,建议还是去看单独的教程。在本次的教程中,我们做的事有非常强的前后逻辑性,必须在完成前面的步骤以后你才能进行下一步。当然,在你安装时,肯定会遇到非常多的问题,所以这需要你具有一定解决问题的能力,项目开源已经有一段时间了,所以网络上的资料非常多。当你遇到问题以后,你可以在浏览器中用尽量简短的话去描述并且搜索你的问题。或者直接将报错的那一行信息直接复制到浏览器中进行搜索,这可能也需要你会查看python的报错,python报错一般都伴随着很多文件。直接搜索报错信息这种办法非常有效,可以让你快速定位错误原因和解决办法。如果你在直接搜索时没有搜素到你对应的错误那你就可以考虑用比较详细的话语描述你的错误并提交给AI,如果你使用的是目前比较新的AI语言模型,它应该都能给出比较有效的解决方案。当你在进行了以上的步骤以后,依然不能解决你的问题,那你就可以考虑去社区或者论坛中寻求帮助,但是请注意提问的艺术,你需要详细的描述你的问题并且描述你在出现这个问题之前进行了什么操作,只有这样,大佬才知道你的问题在哪儿并且给出解决方案。总的来说,这次部署过程是非常不容易的,如果你准备好了,那就让我们开始吧!
三、miniconda环境安装
本次我们将在虚拟环境中演示如何部署,这里我选择miniconda来实现虚拟环境。后面的演示也都会基于miniconda,如果你已经能够分清在系统中直接安装python和python虚拟环境的区别,那么你就可以选择自己喜欢的方式来进行下一步,如果你是一位小白,那么请跟着我进行操作。我们需要使用conda将环境隔离出来,防止别的依赖冲突问题。你可以跟着我当前的文章进行操作,也可以去看我以前的文章,那个教程会详细许多,我也建议小白前往下面的链接查看教程:
miniconda安装教程:[python]我们应该如何安装Miniconda虚拟环境?(详细)_miniconda创建虚拟环境-CSDN博客
如果你已经跟着上面的教程成功安装了miniconda,那么你可以直接跳过这个大点。下面我们开始安装miniconda。
首先我们去到miniconda官网下载安装包:


下载好以后如下图所示:

开始安装:





这里最好把所有勾打上。



在安装完成以后,启动测试一下,直接在搜索框中搜索“miniconda”,并且启动:


使用下面的命令来创建一个虚拟环境:
conda create --name so-vits-svc python=3.8
使用下面的命令进入虚拟环境:
conda activate so-vits-svc
在成功进入虚拟环境以后,conda的安装步骤就已经结束了,值得注意的是这里将python版本最好固定在3.8附近。
四、pytorch安装
因为我们的so-vits-svc依赖于pytorch运行,我们在这里需要自行安装pytorch。这里一定要将pytorch单独安装。这里pytorch的安装在以前我也提供了教程,如果你要获取详细的安装教程,请参考下面的文章,下面我会演示如何在虚拟环境中安装pytorch:
pytorch安装:[python]如何正确的安装pytorch?(详细)_pytorch安装-CSDN博客
下面我会简单的演示我的安装步骤,有一点要注意的是,我们这里要将pytorch的CUDA版本固定在11.7或者11.8,在12以后的版本都不适用,使用CPU部署的可以忽略这一条。
查看cuda版本:

去官网下载对应CUDA的最新驱动安装包:

选择好对应版本:



下载好以后如图:

下载好以后不着急安装,我们先去安装一个Visual Studio,这里在安装CUDA驱动时会用到它的C++编译环境,包括后面安装python包时也会用到,建议大家在现在就安装好。
去到Visual Studio官网下载安装包:

这里我们选择图中所示的版本:


下载好以后如图:

开始安装Visual Studio。

等待完成:

这里把C++桌面开发勾上:

更换一下安装的路径。不然默认安装在C盘。

选择好安装路径以后,直接点击安装:

等待安装完成:

在安装完成以后就可以了,出现如下界面:

可以不登录,直接关掉即可,在安装完成以后建议重启一次电脑。
在安装好vs以后,我们就可以继续安装CUDA驱动了。






等待安装完成。


打开cmd输入下面的命令查看安装是否成功。
nvcc -V注意这里的V是大写的。出现下面的输出表示CUDA驱动安装成功:

开始在虚拟环境中安装pytorch。
进入虚拟环境:

选择pytorch版本。因为要固定CUDA版本,所以,我们选择下面版本的pytorch。

在固定CUDA版本的同时pytorch不要太新,这里选择2.0的。复制到命令行中,开始安装:

等待安装完成。
在安装完成以后,使用“pip list” 查看已经安装的包,出现以下结果就表示安装完成。

这里显示的pytorch的版本和对应的CUDA的版本。如果你安装的是GPU版的pytorch但是这里没有出现CUDA的版本,那你就要考虑看看是不是在安装时哪里出了问题。可以尝试重新安装。如果你反复重试都无法成功就可以尝试去看一下上面链接中的文章,这个文章讲述了详细安装教程。
我们可以在已经安装了pytorch的虚拟环境中依次输入下面的命令进行验证:
pythonimport torchprint(torch.cuda.is_available())
如果安装成功则会返回“True”

当你安装完pytorch以后,才能进行下一步。
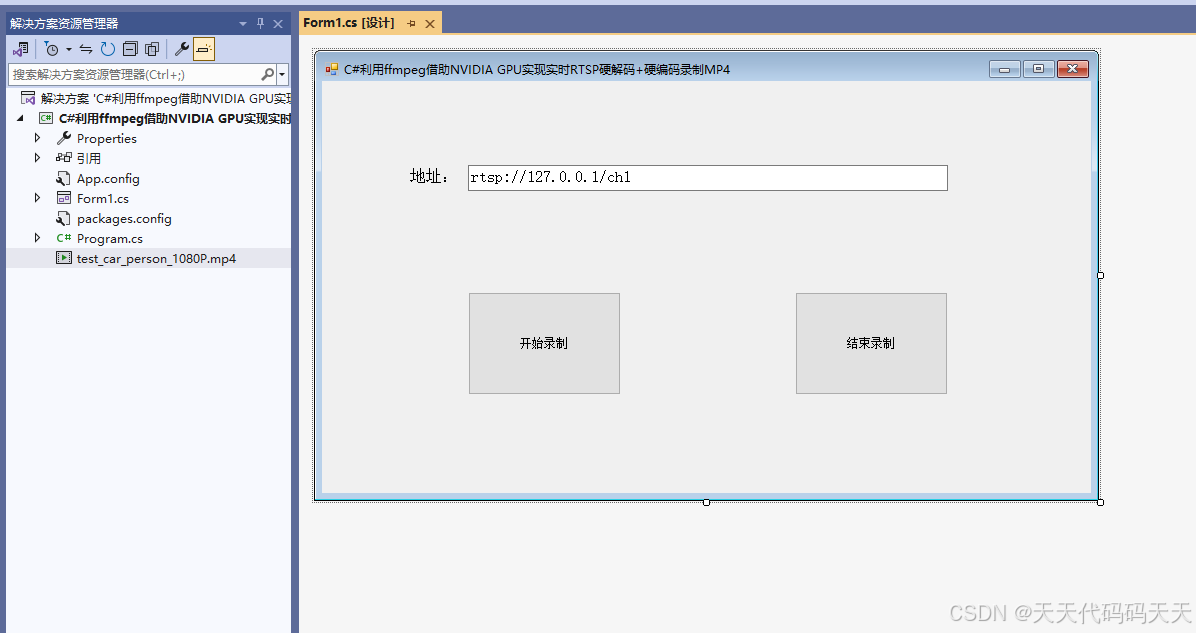
五、FFmpeg安装
FFmpeg的安装相对简单,所以没有专门的文章教程,大家跟着我操作即可。
去到FFmpeg的官网下载FFmpeg的安装包,FFmpeg官网:FFmpeg




下载好以后如图所示:

解压以后得到如下文件夹:

文件夹下有一个名为“bin”的文件夹,文件夹中有如下内容:

我们需要将这个“bin”文件夹的路径添加到环境变量。
右键”此电脑“点击属性,得到以下界面:

在这个界面中点击“高级系统设置”:

在高级系统设置中点击“环境变量”:

我们要对“系统变量”进行设置:

选中“Path”后点击“编辑”:

在编辑中点击“浏览”:

将刚才的路径选中进来。

这里要注意路径中不能有中文和一些不明字符。
当路径选入以后,点击确定,然后将打开的所有窗口一路确定下去。
在配置完以上以后,就可以打开cmd命令行窗口输入下面的命令检查是否安装成功了。
ffmpeg -version输入以后回车,应该会有类似于一下图中的输出。

如果你在输入命令以后,没有得到上面图中这样的输出,或者提示未知命令,找不到命令,这些提示都表示安装没有完成,可以考虑重试上面的步骤或者查阅相关资料
至此,我们的FFmpeg已经安装完成。
六、拉取项目
我们需要将整个so-vits-svc项目克隆下来,大家可以自行安装git使用下面的命令进项克隆,或者是直接下载项目压缩包再解压。
git clone https://github.com/svc-develop-team/so-vits-svc.git项目文件夹如图所示:

七、其它依赖项的安装
我们在项目文件夹中找到“requirements_win.txt”并且使用记事本打开。

这里面就是我们项目所依赖的所有库了。我们需要单独安装“fairseq”这个库。这个库安装可能会出现许多错误,请你在安装这个库之前已经安装了Visual Studio 2022并且在其中安装的C++的开发环境。
在虚拟环境中使用下面的命令安装“fairseq”库:
pip install fairseq==0.12.2![]()
第一次安装出现了非常多的警告,并且还伴随着错误,在你完全看不懂这些警告和错误的情况下,将它们复制给AI是一个不错的解决方案:


AI给出了如下解决方案,我们可以逐一尝试:

使用AI的解决方案,如果再有报错就再将错误提交给AI,直到所有的错误解决为止,这个过程可以提高你解决问题的能力。如图,我们的“fairseq”库已经安装完成了。

既然已经安装完成,我们就可以到“requirements_win.txt”中将这个库删除,然后我们可以在终端中执行下面的命令,安装“requirements_win.txt”中的所有依赖:
pip install -r requirements_win.txt如果你在安装时出现报错,可以尝试重新执行上面的命令进行安装,如果你反复出现错误,可以尝试将“requirements_win.txt”的库一个一个进行安装。
如果你在安装时出现网络问题,可以使用下面的命令将你的pip换源:
# 设置清华大学下载镜像
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config set global.trusted-host pypi.tuna.tsinghua.edu.cn如图所示,就已经安装完成了,可以看到安装了非常多的库:

在保证上面的库安装没有问题以后,使用下面的命令将指定的库固定到指定版本:
pip install --upgrade fastapi==0.84.0
pip install --upgrade pydantic==1.10.12
pip install --upgrade gradio==3.41.2在确认上面的库安装没有问题以后,使用下面的命令来打开webui。记得在项目根路径下执行命令,不然会找不到这个文件:
python .\webUI.py如果在启动时报错,可以重新查看是否是库的缺失或者是不是库的版本冲突。可以使用上面的办法将错误直接复制给AI进行分析。在输入上面的命令后,如果没有出现错误,过一会儿就可以看到以下输出,并且会自动打开浏览器并且打开webui。

它这里给出了一个提示,我们可以升级这个库,大家根据自己的情况选择升级。
如下图所示,我们的so-vits-svc webui已经成功启动了:

webui能够正常启动说明我们的环境并没有问题。至此,我们“so-vits-svc webui”的所有依赖项已经安装完成。
八、载入底模与相关配置文件
我们这里,不管是推理还是训练,都需要有底模的参与,so-vits-svc的开源库中提供了非常多的底模,不同参数的底模训练和推理出的声音不一样。下面我会进行一个底模以及配置文件的导入和推理测试。
在此处的配置可以参考文章:so-vits-svc-Deployment-Documents/README_zh_CN.md at 4.1 · SUC-DriverOld/so-vits-svc-Deployment-Documents · GitHub
如果你在环境配置还有问题也可以参考上面的文档。下面会用到一些文件资源,资源来自下面这些UP主:
底模提供以及部署教程:【视频已过时仅作参考】最详细的AI音色转换So-vits-SVC4.1本地配置/训练/推理/使用教程/非整合包/从零开始配置!_哔哩哔哩_bilibili
芙宁娜模型提供:分享一个so-vits-svc4.0芙宁娜的AI语音模型【第二期】_原神 (bilibili.com)
上面视频的教程大家也可以看,我的流程和视频中是一样的。我会整理后面会用到的文件,大家自行下载以后,就可以跟着我继续操作了。
相关文件下载:
在下载好相关文件以后,我们就可以继续下一步了。
将压缩文件解压以后得到以下文件夹:

下面的配置会使用到这些文件。
我们首先打开“Sovits4.x”文件夹。

我们将“Sovits4.x”文件夹的“checkpoint_best_legacy_500.pt”文件复制到项目文件夹的“”

将“Sovits4.x”文件夹下的“D_0.pth”和“G_0.pth”文件复制到项目文件夹目录下的“logs/44k”目录下。

将“Sovits4.x”文件夹下的“model_0.pt”复制到项目文件夹下的“logs\44k\diffusion”目录下。

在以上文件都复制完成以后,请多确认几次准确无误。
至此我们相关的配置就已经完成了。
九、使用训练好的模型进行推理测试
当你进行到这一步时,相信你已经完成了上面的步骤。如果你没有完成上面的步骤,可以多尝试几次,之前提到过,我们整个部署过程有非常强的逻辑性,只有完成了前面的步骤,我们这一步才算成功才算真的部署好了这个项目。当你遇到问题时,可以参考上面我提到的文章也可以去看我给出的视频链接。
在你确定上面的步骤没有问题以后,那就开始我们本次部署的最后一步,使用训练好的模型进行推理测试吧。
我们首先启动webui。

我们点击图中所示的地方将“芙宁娜so-vits4.0”文件夹中的“G_46400.pth”文件选中进来。

出现模型大小就表示导入成功了。
我们点击图中所示的地方将“芙宁娜so-vits4.0”文件夹中的“config.json”文件选中进来。

在完成以上步骤以后,我们就可以点击“加载模型”:

点击了“加载模型”以后,会出现出现说话人,如果一个模型在训练的时候训练了多个说话人,这里就能选择,当然,我们目前这个模型只有一个说话人。

在选择了说话人以后,我们可以选择我们的推理设备,auto表示自动选择,如果你安装了CUDA版的pytorch但是这里却没有你的显卡,说明你的pytorch没有安装成功,请回去检查以下,或者使用cpu进行推理。

在设置好以上以后,我们将这个页面滑到最下面,我们这里选择“文字转音频”:

我们这里在文字框中输入想要转换的文字,然后选择说话人的性别,这里说话人的性别很重要,如果说话人的性别和这里没对应转换出来的声音就会很怪,这里芙宁娜的模型我们要选择女声。随后点击“音频转换”:

开始转换以后,会有一个预估时间:

出现音频以后,就表示转换成功了,大家可以试听一下,大家也可以去下载别的模型进行体验,模型最主要的是一个模型文件一个配置文件,只需要导入这两个文件,模型就能最基本运行。

至此,我们的so-vits-svc webui部署与推理已经完成,如果你在导入模型或者推理时出现错误可以参考上面我给出的文章,或者使用我最开始给出的遇到错误解决办法。
十、结语
我们部署了so-vits-svc,大家可以使用这个开源项目推理自己喜欢的角色的声音,大家可以自行去下载已经训练好的模型,后面有趣的玩法留给大家自行探索吧!











![[Arxiv 2024] Self-Rewarding Language Models](https://i-blog.csdnimg.cn/direct/4f38d34f0d3c4a0192d9c645dfc54f78.png#pic_center)