作者:51CTO技术栈
译者 | 布加迪
Kubernetes是如今最知名最流行的容器编排引擎。Kubernetes之所以成为云原生计算的中心,是由于它是开源的,还有一个快速增长的生态系统。如果观察它在过去几年的发展和采用趋势,尤其是在云原生世界方面,就会发现它不仅仅是一种容器编排工具。它已经不再是一种容器编排引擎,现在是下一代云原生生态系统的主要构建模块。
开发人员正在试用Kubernetes,绝不仅仅将其当成容器管理器。本文讨论它在开源社区中几个已确立的企业模式和流行用例。
Kubernetes作为无服务器计算的服务器
Kubernetes方面有经验的企业已认识到Kubernetes作为“无服务器的服务器”平台具有的全部潜力。无服务器现在因Kubernetes而被重新定义,而Knative最近由CNCF(Kubernetes的监管组织)推出,将Kubernetes抽象为无服务器计算。Knative的核心由三个模块组成:
1. Build—从源代码构建映像。
2. Serving—在Kubernetes集群上部署功能(映像构建),并映射扩展和路由等。
3. Eventing—用servicing映射事件和消息摄取。
就像面向Kubernetes的kubectl一样,kn是终端上新的命令,用于在Kubernetes上启用函数即服务(FaaS)。它将容器映像作为构建模块,在Kubernetes上处理一切。Kubernetes作为一个无服务器平台在加快其在企业界的采用;然而,同类产品(比如AWS Lambda、Cloud Functions和Azure Functions)仍然依赖供应商锁定(即部署到各自的云上它们才管用)。
Kubernetes解决一些现有的挑战,比如工件大小的限制、法规遵从、数据主权和企业内部的细粒度控制。Kubernetes上的无服务器Knative与传统Kubernetes之间的主要架构差异来自额外的抽象层。作为无服务器的Kubernetes消除了重复的配置和构建任务。
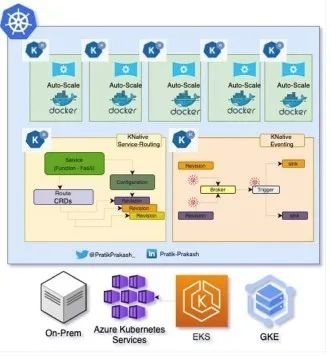
图1
Kubernetes上的无服务(Kubernetes集群概况图)
Knative充当无服务器和事件驱动平台
Knative是Kubernetes生态系统的新成员,它有望颠覆构建基于事件的架构的无服务器选项。“扩展到零”、“从零扩展”和集群内构建等功能使Kubernetes成为一种全面的无服务器平台。
Kubernetes作为大数据和机器学习平台
Kubernetes被视为数据科学和机器学习技术堆栈当中的大数据处理和有状态数据服务平台,并被广泛采用。它抽象了底层基础架构,优化了弹性计算的配置,在底层将GPU和CPU结合起来。Kubernetes非常适合机器学习,因为它本身就具备机器学习需要的所有调度和可扩展性。
与传统的数据集群环境相比,容器和Kubernetes组合在构建大数据软件时功能强大且灵活,传统的数据集群环境面临分布式集群管理的复杂性和计算规模开销。Kubernetes利用按需提供的GPU和CPU计算来改善大数据和机器学习处理。Kubernetes可以提供GPU加速计算和网络解决方案,以便在边缘运行机器学习和NLP处理。运行在协处理器上的Kubernetes正成为未来计算的重要部分。其动态资源利用的特性有利于数据科学工作负载,而训练模型或特征工程需求可以非常迅速地增减。
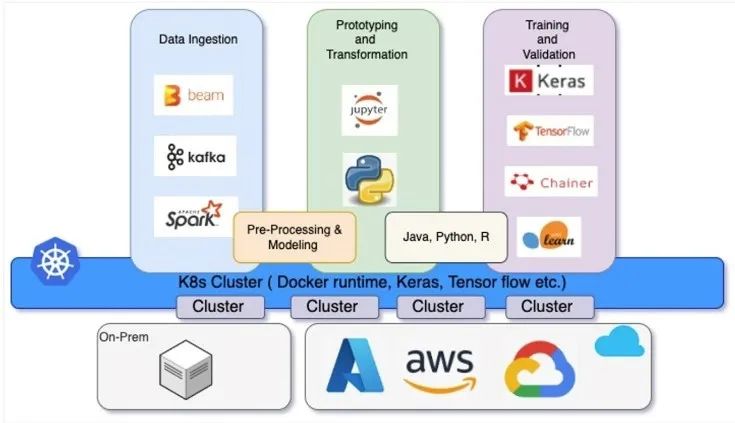
图2
基于Kubernetes的大数据和机器学习集群
用于机器学习处理的按需可扩展协处理器
KubeFlow、Spark、Hadoop、PyTorch和TensorFlow等框架现都在采用容器。有状态MLOps广泛采用容器和Kubernetes来启用多个集群,处理大型训练集和测试集,并存储学到的模型。为了简化数据建模框架的处理,一种选择是Kubeflow,这是一种面向Kubernetes的开源机器学习工具包,可以运行声明式的可配置作业。
Kubeflow对运行在Kubernetes上的复杂的大数据和机器学习管道进行抽象和编排。机器学习管道底层的Kubernetes是MLOps的骨干。它使得数据科学家和机器学习工程师很容易利用混合云(公共云或本地环境)来处理弹性和可扩展性。Kubernetes能够构建一个中立的大数据平台,避免云管理服务被供应商锁定。
Kubernetes作为企业混合和多云集群的联合体
Kubernetes与基础架构无关,企业利用它来实现复杂的基于容器的集群联合。Kubernetes有助于将混合或多云环境合并到单一平台中,从而获得明显的好处。
托管服务不是解决所有问题的方案。公共云和私有主权云的便利性之间总是需要兼顾。Kubernetes被认为是这方面的解决之道,因为它支持多云访问,可以跨基于行业标准的API (Kubernetes接口)无缝交付应用程序。它通过将私有云和公共云集成抽象为单一联合平台,有助于企业借助Kubernetes实现法规遵从。
企业利用Kubernetes提供混合和多云集群方面的灵活性,从而避免供应商锁定。当前基于云的架构模式如何采用Kubernetes值得拭目以待。基于云的企业以及开源社区已意识到,Kubernetes不仅仅是一种容器管理工具。现在很显然,Kubernetes是一种完整的平台,可以为在混合云或多云模式上运行的应用程序管理生命周期。
Kubernetes作为平台即服务(PaaS)被广泛采用。然而在早期,Kubernetes的官方文档提到它是容器即服务(CaaS)。最近,人们观察到Kubernetes的采用模式和使用已远远超出了CaaS,因此更新后的文档称Kubernetes是下一代PaaS。
Kubernetes是新时代的PaaS,意味着:
Kubernetes结合超融合基础架构(HCI)是一种新的私有或混合云替代方案。它让企业可以全面控制服务,并遵从监管法规。
Kubernetes使企业能够实现单一的抽象和简化型平台,以便在混合和多云环境上操作SRE、DevOps和DevSecOps。
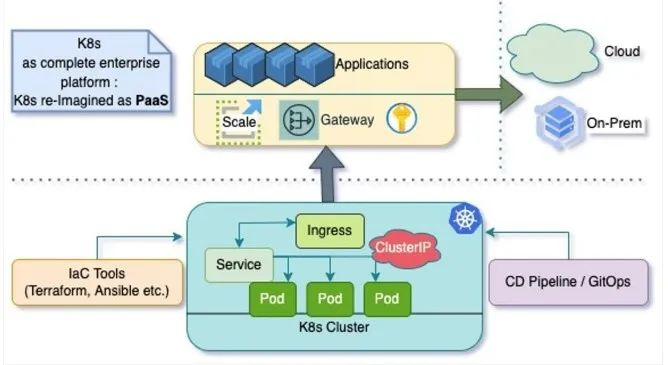
图3
Kubernetes作为新一代PaaS
混合和多云容器联合作为新一代PaaS
大型组织通常不愿意将平台控制权交给AWS Lambda、AWS Fargate或Azure Functions等。Kubernetes已成为一种事实上的选择,它集两者之所长:控制性和本地稳健性,以及来自声明式容器化生态系统的云原生计算弹性、可扩展性和弹性。Kubernetes结合Helm(IaC)、Grafana(遥测仪表板和警报)以及Prometheus(度量指标获取器)等开源工具,使其成为支持DevOps、对SRE友好的企业生态系统的完美组成部分。
数据科学和机器学习企业在加快采用Kubernetes作为大数据处理平台。最近,机器学习和大数据框架正变得容器化,这使得Kubernetes成为底层数据集群和建模生态系统的首选。备受青睐的特性还包括Kubernetes抽象弹性GPU和CPU,以及按需可扩展和状态性。
Knative之类的Kubernetes抽象框架将Kubernetes带到了另一个层面。Kubernetes正在成为无服务器架构的新服务器,而且势头正猛。它正在为AWS Fargate和OpenShift提供开源替代方案。Kubernetes已被赋予了多种新的角色,而不仅仅“只是”一种容器编排工具。
围绕Kubernetes的平台和工具,将赋予企业新的机遇
无疑不说明K8s在企业的应用已相当广泛。但就目前来看,国内企业在使用K8s时,大多是在做云计算方面的相关调度,针对大数据领域,企业还在管理另一套纷繁复杂的系统,即传统大数据平台。现在,将这样的大数据平台迁移至K8s上趋势逐渐兴起。
换句话说,随着以Kubernetes技术为代表的云原生技术浪潮的袭来,大数据平台的云原生化已经成为大势所趋。基于此,智领云自主研发的市场上首个可完全在Kubernetes上部署的容器化云原生大数据平台--Kubernetes Data Platform (简称KDP)。
让用户完全去除了对Hadoop的依赖,可以直接在K8s环境中运行所有工作负载,统一资源管理,便于多租户计费管理,大幅降低运维成本。
此外,“云原生大数据平台”的底层支撑,是一个全局共享的平台。用户可以将既有的系统迁移至资源池,实现更高的资源利用率。同时,云原生的存算分离架构,还可以分别管理冷热数据存储,即针对不同的应用场景,选择机械硬盘、固态硬盘、对象存储等不同的存储介质,以降低存储成本。
在过去几年里,Kubernetes 经历了不可思议的发展,随着越来越多的企业投身使用,它已经成为了 IT 行业的主流技术,接下来将会有越来越多围绕Kubernetes的平台和工具将实现新功能,赋予企业新的机遇。
原文链接:
https://dzone.com/articles/kubernetes-beyond-container-orchestration
- FIN -

更多精彩推荐
容器化云原生大数据平台什么样?智领云KDP给你打个样儿
享受云原生技术红利,大数据不应该被落下
2023中国智能应用发展论坛在京开幕,智领云受邀参加,并取得圆满成功
【博云+智领云】携手云原生大数据领域,开展深度合作
揭秘 ChatGPT 背后的技术栈:OpenAI 如何将 Kubernetes 扩展到了 7500 个节点
 点击“阅读原文”详细了解KDP
点击“阅读原文”详细了解KDP