一、背景
众测项目中白帽可能会提交一些信息泄露漏洞,同时甲方可会收到一些白帽提交的公网信息泄露文件漏洞,例如百度网盘被员工分享某些文件或者某些包含敏感信息的文件可以通过如谷歌、百度等搜索引擎通过特定语法搜索到。为了可以及时发现泄露的文件,所以需要开发一个平台整合这些泄露渠道进行展示和告警,便于快速响应处理。白帽可以用来及时发现提交漏洞,甲方也可用来作为一个安全巡检的补充。
二、调研
通过分析调研信息泄露的途径,整合如下4种渠道:
1.网盘分享泄露信息
2.搜索引擎泄露信息
3.文档平台泄露信息
4.暗网情报泄露信息根据不同渠道进行细分常见场景
1.1 网盘分享泄露信息
1.1.1 百度网盘
1.1.2 阿里网盘
1.1.3 夸克网盘
设计思路:配置好关键字,若分享的文件中包含关键字则记录入库,重复则忽略,并进行钉钉告警推送。
1.2 搜索引擎泄露信息
1.2.1 谷歌搜索引擎
1.2.2 百度搜索引擎
1.2.3 duckduckgo搜索引擎
设计思路:配置好对应引擎关键字搜索语法,若根据该语法搜索到文件,则记录入库,重复则忽略,并进行钉钉告警推送。
1.3 文档平台泄露信息
1.3.1 语雀文档平台
设计思路:配置好对应关键字,若根据该关键字搜索到文档,则记录入库,重复则忽略,并进行钉钉告警推送。
1.4 暗网情报泄露信息
1.4.1 长安不夜城(中文)
设计思路:配置好对应关键字,若根据该关键字搜索到相关情报,则记录入库,重复则忽略,并进行钉钉告警推送。
相关核心功能开发后再进行展示。
三、实施
由于谷歌引擎、duckduckgo引擎、暗网访问需要国外IP,所以需要准备一台国外服务器用于相关功能的运行。
1.1 网盘分享监控开发
通过调研发现网上有很多集成的引擎搜索平台,可以利用相关平台的搜索接口来帮助我们快速发现相关信息。
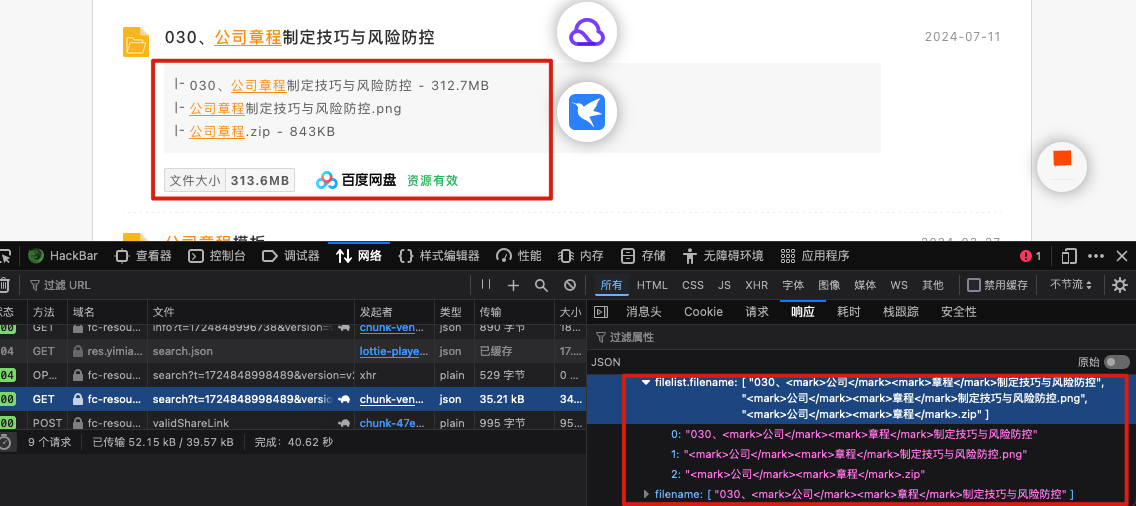
选择任意一个集成平台输入关键字分析其请求的域名和响应
t=1724848998489
version=v2
kw=%E5%85%AC%E5%8F%B8
page=1
line=0
site=dalipan
resType=baidu其中请求中kw=xxx为查询的关键字,resType=xxx为查询的网盘类型,page=xxx为当前的页数;响应中filename为分享的文件名,filelist.filename为包含的文件名,size为文件大小,utime为发现时间,updatetime为更新时间,type为网盘类型
{"resources": [{"highs": {"filelist.filename": ["030、<mark>公司</mark><mark>章程</mark>制定技巧与风险防控","<mark>公司</mark><mark>章程</mark>制定技巧与风险防控.png","<mark>公司</mark><mark>章程</mark>.zip"],"filename": ["030、<mark>公司</mark><mark>章程</mark>制定技巧与风险防控"]},"res": {"id": "c297b6141c3022e1bbc8c980566830bb","eu": "wpe2FBwwIuG7yMmAVmgwu12t1yAEGFH_hADpCkAL7QGSPeeqtWgTtR-T8mqNjS6uBwiH3hOY5SObJ138wa_LLQ==","filename": "030、公司章程制定技巧与风险防控","size": "328790789","isdir": 1,"ctime": "2024-07-11 07:13:18","utime": "2023-03-27 09:30:58","category": 6,"user": "1102841425375","updatetime": "2024-07-12 07:07:48","type": "baidu","filelist": [{"size": "327927517","filename": "公司章程.zip","ext": "zip"},{"isdir": 1,"filename": "030、公司章程制定技巧与风险防控"},{"size": "863272","filename": "公司章程制定技巧与风险防控.png","ext": "png"}]],"total": 156290
}
接下来只需定时发送请求,并对响应中需要的结果进行入库,如果重复的忽略,有效的入库并进行告警即可。
针对重复内容可以提取文件名转换为hash值入库,方便快速比对。
1.2 搜索引擎泄露信息开发
1.2.1 谷歌搜索引擎
因为检测内容主要针对文件泄露,所以以文件搜索语法为例。
例如,语法为:filetype:pdf "身份证" 表示搜索文件后缀为pdf的文件,且搜索结果中包含关键字“身份证”。我们只需要提取搜索结果的链接、名称即可。之后组合查询语法、引擎类型和发现时间入库,并推送告警即可。
定义一个函数,接受文件后缀和关键字,获取结果中的标题和下载链接并推送告警。
def search_google(suffix,kw):query = 'filetype:' + suffix +" "+"("+kw+")"# 谷歌搜索的API地址search_url = "https://www.google.com/search?q={}".format(query)query_list = []# 发送HTTP请求获取搜索结果response = requests.get(search_url)response.raise_for_status() # 检查请求是否成功# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, "html.parser")# 查找所有的span标签list_h3 =[]spans = soup.find_all('h3')for s in spans:list_h3.append(s.get_text())#获取文件下载链接,为列表list_herf = []list_a = soup.find_all('a')#查询文件的语法,用于去除不符合的字符串no_filetype = 'filetype:' + suffixfor i in list_a:#将得到的值转换为小写进行比较lower_i = str(i).lower()if ("data-ved" in lower_i) and ("google.com" not in lower_i) and (no_filetype not in lower_i) :href_url = i['href']# 这是一个正则表达式,用于匹配URLpattern = r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'# 使用re.findall()函数找到所有匹配的URLurls = re.findall(pattern, href_url)#增加报错提示,如果列表中没有获取到链接将赋予noif len(urls) == 0:urls.append("no")list_herf.append(urls[0])query_list.append(query)fix_type = 'google'google_num_ok = 0google_num_no = 0#输出搜索结果的 标题、链接、语法、引擎类型for j,k,l in zip(list_h3,list_herf,query_list):title = jherf = kgrammar = lwith app.app_context():try:# 转换为hash值bytes_string = title.encode('utf-8')hash_object = hashlib.sha256()hash_object.update(bytes_string)hash_value = hash_object.hexdigest()res = Result_Esearch(name_hash=hash_value, name_title=str(title), name_href=herf,created_at=str(datetime.now()), name_grammar=str(grammar), name_ok=str(0),name_type=fix_type)db.session.add(res)db.session.commit()print(f" added successfully.")google_num_ok = google_num_ok + 1sent_messange("触发时间:" + str(datetime.now()) + '\n' +"告警类型:谷歌搜索引擎监测告警" + '\n' +"告警标题:" + str(title) + '\n'"详情链接:" + str(web_url)+ '\n'"文件下载地址:" + str(herf))except IntegrityError: # 捕获唯一性约束违反的异常db.session.rollback() # 回滚事务print(f"User already exists, skipping.")google_num_no = google_num_no + 1#print("本次谷歌探测发现记录" + str(google_num_ok + google_num_no) + "其中待处理记录为" + str(google_num_ok) + ",重复条数为" + str(google_num_no))# 入库记录new_num_google = google_num_ok# 重复记录repeat_num_google = google_num_no# 返回入库记录和重复记录return new_num_google, repeat_num_google1.2.2 百度搜索引擎
根据百度搜索引擎的语法,得到搜索结果,提取结果标题和链接并进行告警推送。
def search_baidu(keyword):# 对关键字进行URL编码encoded_keyword = urlparse.quote(keyword)# 百度搜索URLurl = f'https://www.baidu.com/s?wd={encoded_keyword}'#print(url)title_list = []herf_list = []# 自定义请求头headers = {'Host': 'www.baidu.com','Cookie': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:114.0) Gecko/20100101 Firefox/114.0','Accept': '*/*','Accept-Language': '','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','Te': 'trailers','Connection': 'close',}# 发送GET请求response = requests.get(url, headers=headers)# 检查请求是否成功if response.status_code == 200:# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')#print(soup)#获取搜索结果的标题spans = soup.find_all('h3')#print(spans)#print(type(spans))for i in spans:#输出搜索结果的标题#print(i.get_text())title_list.append(i.get_text())list_h3_a = i.find_all('a')for a in list_h3_a:#输出搜索结果的标题的链接#print(a['href'])herf_list.append(a['href'])e_type ="baidu"baidu_num_ok = 0baidu_num_no = 0for title,herf in zip(title_list,herf_list):#输出标题、链接、语法、引擎类型#print(title,herf,keyword,e_type)with app.app_context():db.create_all() # 创建所有数据库表print(title)try:# 转换为hash值bytes_string = title.encode('utf-8')#print(title)hash_object = hashlib.sha256()hash_object.update(bytes_string)hash_value = hash_object.hexdigest()res = Result_Esearch(name_hash=hash_value, name_title=str(title), name_href=herf,created_at=str(datetime.now()),name_grammar=str(keyword), name_ok=str(0), name_type=e_type)db.session.add(res)db.session.commit()print(f" added successfully.")baidu_num_ok = baidu_num_ok + 1sent_messange("触发时间:" + str(datetime.now()) + '\n' +"告警类型:百度搜索引擎监测告警" + '\n' +"告警标题:" + str(title) + '\n'"详情链接:" + str(web_url)+ '\n'"文件下载地址:" + str(herf))except IntegrityError: # 捕获唯一性约束违反的异常db.session.rollback() # 回滚事务print(f"User already exists, skipping.")baidu_num_no = baidu_num_no + 1print("本次探测发现记录" + str(baidu_num_no + baidu_num_ok) + "其中待处理记录为" + str(baidu_num_ok) + ",重复条数为" + str(baidu_num_no))#入库记录new_num = baidu_num_ok#重复记录repeat_num =baidu_num_no#返回入库记录和重复记录return new_num,repeat_num
1.2.3 duckduckgo搜索引擎
同样的,根据duckduckgo引擎搜索语法,提取其结果。
####duckduckgo搜索引擎搜索结果,结果为一个列表。
def safe_duckduckdo_results(results: Union[str, list]) -> str:"""Return the results of a Google search in a safe format.Args:results (Union[str, list]): The search results.Returns:str: The results of the search."""if isinstance(results, list):safe_message = json.dumps([result.encode("utf-8", "ignore").decode("utf-8") for result in results])else:safe_message = results.encode("utf-8", "ignore").decode("utf-8")return safe_messagedef duckgo_web_search(query: str, num_results: int = 8) -> str:"""Return the results of a Google searchArgs:query (str): The search query.num_results (int): The number of results to return.Returns:str: The results of the search."""search_results = []attempts = 0while attempts < DUCKDUCKGO_MAX_ATTEMPTS:if not query:return json.dumps(search_results)results = DDGS().text(query)search_results = list(islice(results, num_results))if search_results:breaktime.sleep(1)attempts += 1results = json.dumps(search_results, ensure_ascii=False, indent=4)return safe_duckduckdo_results(results)
#duckduckgo语法关键字配置为一个列表:
duckgo_key_list = ['(inurl:"xxx.com") filetype:pdf', '(inurl:"xxx.com") filetype:xlsx']#遍历语法提取相关结果for duckgokey in duckgo_key_list:results = duckgo_web_search(duckgokey)results = json.loads(results)for s in results:# print(s)循环输出搜索结果的标题和文件下载链接、查询语法、搜索引擎类型#print(str(s['title']), str(s['href']),duckgokey,e_type_duckgo)with app.app_context():try:# 转换为hash值bytes_string = s['href'].encode('utf-8')hash_object = hashlib.sha256()hash_object.update(bytes_string)hash_value = hash_object.hexdigest()res = Result_Esearch(name_hash=hash_value, name_title=str(s['title']), name_href=s['href'],created_at=str(datetime.now()),name_grammar=str(duckgokey), name_ok=str(0), name_type=e_type_duckgo)db.session.add(res)db.session.commit()print(f" added successfully.")duckgo_num_ok = duckgo_num_ok + 1sent_messange("触发时间:" + str(datetime.now()) + '\n' +"告警类型:duckgo搜索引擎监测告警" + '\n' +"告警标题:" + str(s['title']) + '\n'"详情链接:" + str(web_url) + '\n'"文件下载地址:" + str(s['href']))except IntegrityError: # 捕获唯一性约束违反的异常db.session.rollback() # 回滚事务print(f"User already exists, skipping.")duckgo_num_no = duckgo_num_no + 1print("本次duckduckgo搜索引擎泄露监控探测共发现漏洞记录:" + str(duckgo_num_ok + duckgo_num_no) + ",其中待处理记录为" + str(duckgo_num_ok) + ",重复条数为:" + str(duckgo_num_no))#发送duckgo钉钉告警1.3 文档平台泄露信息
1.3.1 语雀文档平台
配置cookie后根据关键字检索平台公开文档,进行告警。
#配置语雀cookie,并根据关键字返回要查询的内容
#此处代码从github上找了一个语雀文档项目修改后完成
def YQsearch(pages, query):yqcookie = "填自己语雀cookie"query_yq = db.session.query(Yuque_cookie)for i in query_yq:yqcookie = i.yuque_cookieheaders = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/109.0.0.0 Safari/537.36 ",'cookie': yqcookie}URL = f'https://www.yuque.com/api/zsearch?p={pages}&q={query}&scope=%2F&sence=searchPage&tab=public&type=content'response = requests.get(url=URL, headers=headers)print('[+]当前检索关键词:', query, '[+]当前正在检索第:', pages, '页')return response.json()#格式化语雀搜索到的结果
def clears(data):title_list = []url_list = []book_name_list = []group_name_list = []id_list = []abstract_list = []for i in range(len(data['data']['hits'])):# time.sleep(1)response_yuque_data = data['data']['hits'][i]book_name = response_yuque_data['book_name']group_name = response_yuque_data['group_name']id = response_yuque_data['id']title = response_yuque_data['title'].replace('<em>', '').replace('</em>', '')url = 'https://www.yuque.com' + response_yuque_data['url']abstract = response_yuque_data['abstract'].replace('<em>', '').replace('</em>', '')title_list.append(title)url_list.append(url)abstract_list.append(abstract)book_name_list.append(book_name)group_name_list.append(group_name)id_list.append(id)return title_list, url_list, abstract_list, book_name_list, group_name_list, id_list运行语雀检索并进行告警,其中print输出的为告警内容,替换为钉钉告警推送即可。
def run(query, pages):title_list = []url_list = []book_name_list = []group_name_list = []id_list = []abstract_list = []# 验证搜索是否为空data = YQsearch(query=query, pages=1)if len(data['data']['hits']) == 0:print('[-]当前关键词检索失败请替换其他关键词搜素尝试!')passelse:# 搜索页数这里用了循环,这里循环次数就是搜索的页数for i in range(pages):data = YQsearch(query=query, pages=i + 1)time.sleep(3)data = clears(data=data)# 写入列表title_list += data[0]url_list += (data[1])abstract_list += (data[2])book_name_list += (data[3])group_name_list += (data[4])id_list += (data[5])#print(title_list,url_list,book_name_list,group_name_list)#输出标题、链接、知识库名称、知识库归属、查询关键字、搜索平台keyword_yuque = querytype_yuque = "yuque"yq_num_ok = 0yq_num_no = 0for i,j,k,l in zip(title_list,url_list,book_name_list,group_name_list):# 输出标题、链接、知识库名称、知识库归属、查询关键字、搜索平台#print(i,j,k,l,keyword_yuque,type_yuque)yq_title = iyq_herf = jyq_dbaname = kyq_userid = l#db.create_all() # 创建所有数据库表with app.app_context():try:# 转换为hash值bytes_string = yq_herf.encode('utf-8')hash_object = hashlib.sha256()hash_object.update(bytes_string)hash_value = hash_object.hexdigest()res = Result_Document(name_hash=hash_value, name_title=str(yq_title), name_href=yq_herf,created_at=str(datetime.now()), name_dabname=yq_dbaname,name_userid=yq_userid, name_ok=str(0),name_type=type_yuque,name_grammar=keyword_yuque)db.session.add(res)db.session.commit()print(f" added successfully.")yq_num_ok = yq_num_ok + 1sent_messange("触发时间:" + str(datetime.now()) + '\n' +"告警类型:语雀文档平台监测告警" + '\n' +"告警标题:" + str(yq_title) + '\n'"详情链接:" + str(web_url) + '\n'"文件访问地址:" + str(yq_herf))except IntegrityError: # 捕获唯一性约束违反的异常db.session.rollback() # 回滚事务print(f"User already exists, skipping.")yq_num_no = yq_num_no + 1print("本次语雀搜索引擎泄露监控探测共发现漏洞记录:" + str(yq_num_ok + yq_num_no) + ",其中待处理记录为" + str(yq_num_ok) + ",重复条数为:" + str(yq_num_no))# 发送语雀钉钉告警1.4 暗网情报泄露信息
1.4.1 长安不夜城(中文)
暗网情报目前只集成了一个中文情报网站,由于登录态会过期,所以需要定时手工更换一下,但是并不影响思路分享。登录网站后,根据关键字进行搜索,将所有结果入库保存,如果匹配到配置的关键字则进行告警。
分析其商品展示请求和响应,包含商品名称、价格、发布时间。
获取其响应结果入库,若商品名包含配置关键字则进行推送告警,重复商品不入库。
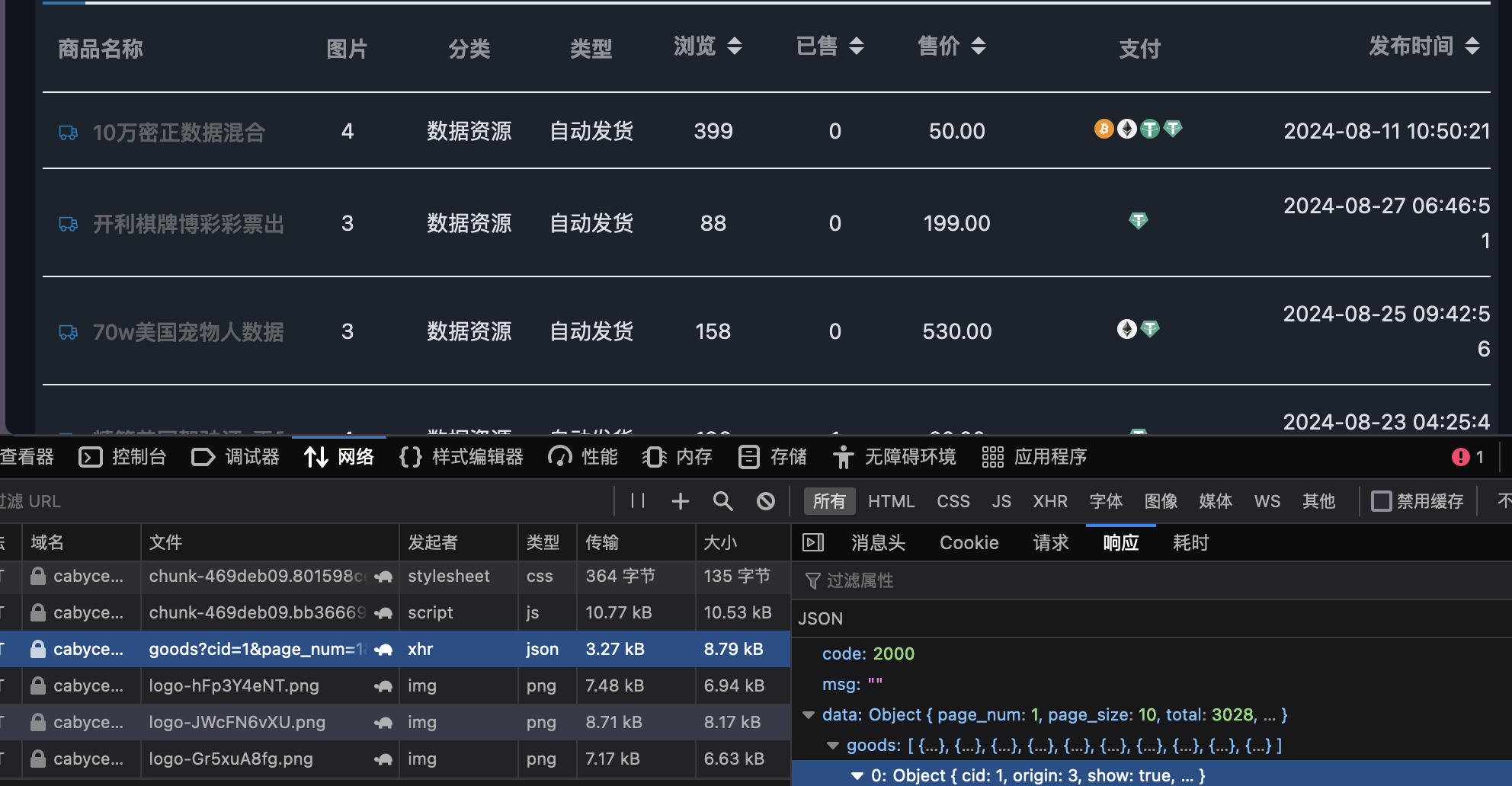
def darknet_run():# 请求头部信息,请求cookie会过期,需要定期更换cookie_pw = '你的账号cookie'query = Anwang_cookie.query.filter_by(id=1)for i in query:cookie_pw = i.darknet_cookiecookie = 'Bearer '+ cookie_pwheaders = {'Host': 'cabyceogpsji73sske5nvo45mdrkbz4m3qd3iommf3zaaa6izg3j2cqd.onion','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; rv:109.0) Gecko/20100101 Firefox/115.0','Accept': 'application/json, text/plain, */*','Accept-Language': 'en-US,en;q=0.5','Accept-Encoding': 'gzip, deflate, br','Referer': 'http://cabyceogpsji73sske5nvo45mdrkbz4m3qd3iommf3zaaa6izg3j2cqd.onion/','Authorization': cookie,'Connection': 'keep-alive','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin'}# 暗网网站的完整URL,包括查询参数,长安不夜城darkweb_url = 'http://cabyceogpsji73sske5nvo45mdrkbz4m3qd3iommf3zaaa6izg3j2cqd.onion/api/category/goods?cid=1&page_num=1&page_size=100&order=ctime&order_by=descending'# 发起请求获取json响应data = fetch_data_from_darkweb(darkweb_url, headers)#增加异常处理try:goods = data.get("data", {}).get("goods", "未找到数据")except:print("tor连接问题或 cookie 过期。")returntype_darknet ="长安不夜城"darknet_num_ok = 0darknet_num_no = 0dark_net_key_list = ['关键字1','关键字2']dd_list = []query = db.session.query(Anwang_key).filter_by(awtype="长安不夜城")for i in query:dd_list.append(i.darknet_key)if dd_list:dark_net_key_list = dd_listwow = 0for i in goods:# 输出 商品名、商品发布时间、商品价格(美元)、商品已售数量、商品浏览量、商品介绍、商品id# 商品详情地址为 http://cabyceogpsji73sske5nvo45mdrkbz4m3qd3iommf3zaaa6izg3j2cqd.onion/#/detail?gid=85c45f70f82e4d48877fb2749950fe88# gid=xxxx gid后的值为id值print(i["name"], i["ctime"], i["price"], i['sales'], i['read_count'], i['intro'], i['id'])# 将时间戳转换为datetime对象dt_object = datetime.fromtimestamp(i["ctime"])# 将datetime对象格式化为字符串dt_string = dt_object.strftime('%Y-%m-%d %H:%M:%S')shop_uptime = dt_stringshop_herf = "http://cabyceogpsji73sske5nvo45mdrkbz4m3qd3iommf3zaaa6izg3j2cqd.onion/#/detail?gid="+str(i['id'])shop_title = i["name"]shop_price = str(i["price"])shop_info = i['intro']for key in dark_net_key_list:if key in shop_info:wow = 1sent_messange("紧急告警!本次暗网搜索引擎泄露监测到包含关键字的漏洞记录:" + str(key) + "商品地址链接为:" + str(shop_herf) + "请及时处理!")with app.app_context():try:# 转换为hash值bytes_string = shop_herf.encode('utf-8')hash_object = hashlib.sha256()hash_object.update(bytes_string)hash_value = hash_object.hexdigest()res = Result_Darknet(name_hash=hash_value, name_title=str(shop_title), name_href=shop_herf,created_at=str(datetime.now()), name_price=shop_price, name_shopuptime=shop_uptime,name_ok=str(0), name_type=type_darknet, name_text=shop_info)db.session.add(res)db.session.commit()print(f" added successfully.")darknet_num_ok = darknet_num_ok + 1except IntegrityError: # 捕获唯一性约束违反的异常db.session.rollback() # 回滚事务print(f"User already exists, skipping.")darknet_num_no = darknet_num_no + 1print("本次暗网搜索引擎探测共发现暗网数据交易商品:" + str(darknet_num_ok + darknet_num_no) + "条,入库记录条数为:" + str(darknet_num_ok) + "条,重复条数为:" + str(darknet_num_no)+"未发现涉及企业数据漏洞!")# 发送暗网钉钉告警
至此各个模块的后台功能基本完成,接下来只需要找一套前端模版进行修改展示即可。
1.5 前端展示开发
这里使用了项目pearadmin进行展示,可以根据官方文档进行套用即可。
pearadmin项目地址:https://github.com/pearadmin/pear-admin-layui
项目结构
Pear Admin Layui
│
├─admin 资源
│ │
│ ├─css 样式
│ │
│ ├─data 数据
│ │
│ └─images 图片
│
├─component 组件
│ │
│ ├─code 设计器
│ │
│ ├─layui 框架
│ │
│ └─pear 封装
│
├─config 配置
│ │
│ ├─pear.config.yml 配置文件
│ │
│ └─pear.config.json 配置文件
│
├─view 视图
│ │
│ ├─console 首页
│ │
│ ├─document 文档
│ │
│ ├─echarts 图表
│ │
│ ├─error 错误页
│ │
│ ├─result 结果页
│ │
│ └─system 系统管理
│
├─index 入口
│
└─login 登录
依照上述功能分别设置六个模块
1.5.1 配置中心
用于各监测模块配置,其中钉钉告警推送配置,用于更新推送的钉钉cookie
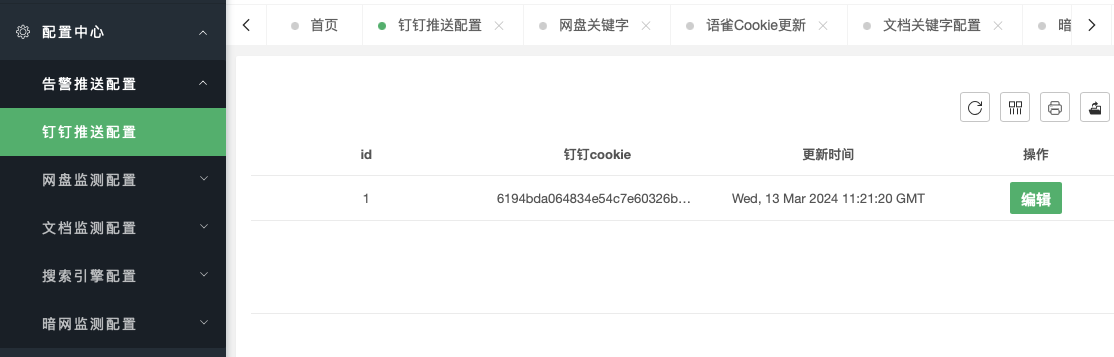
告警效果示例

网盘监测配置用于配置网盘关键字
文档监测配置分为语雀Cookie更新和文档关键字配置
搜索引擎配置用于配置不同引擎的搜索语法
暗网监测配置用于暗网cookie更新和关键字配置
结果统计便于统计记录量
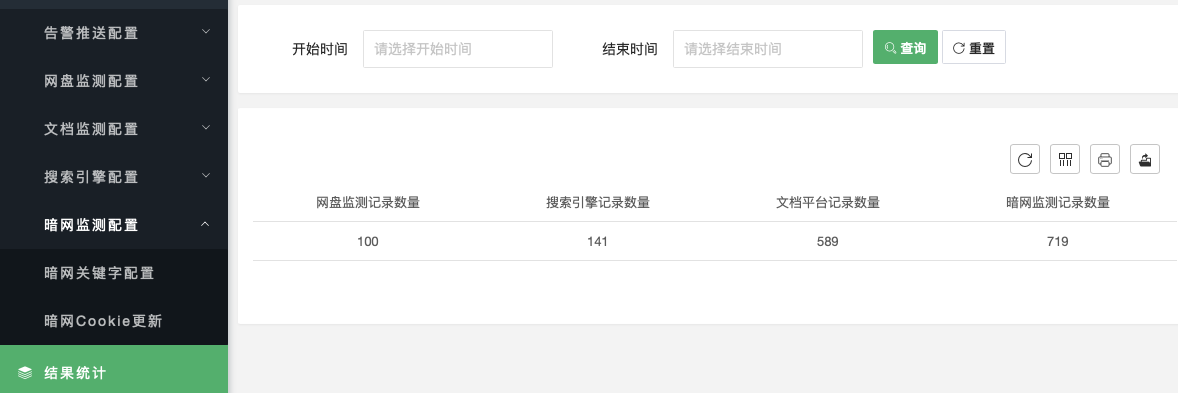
搜索引擎监测结果用于展示引擎搜索的结果
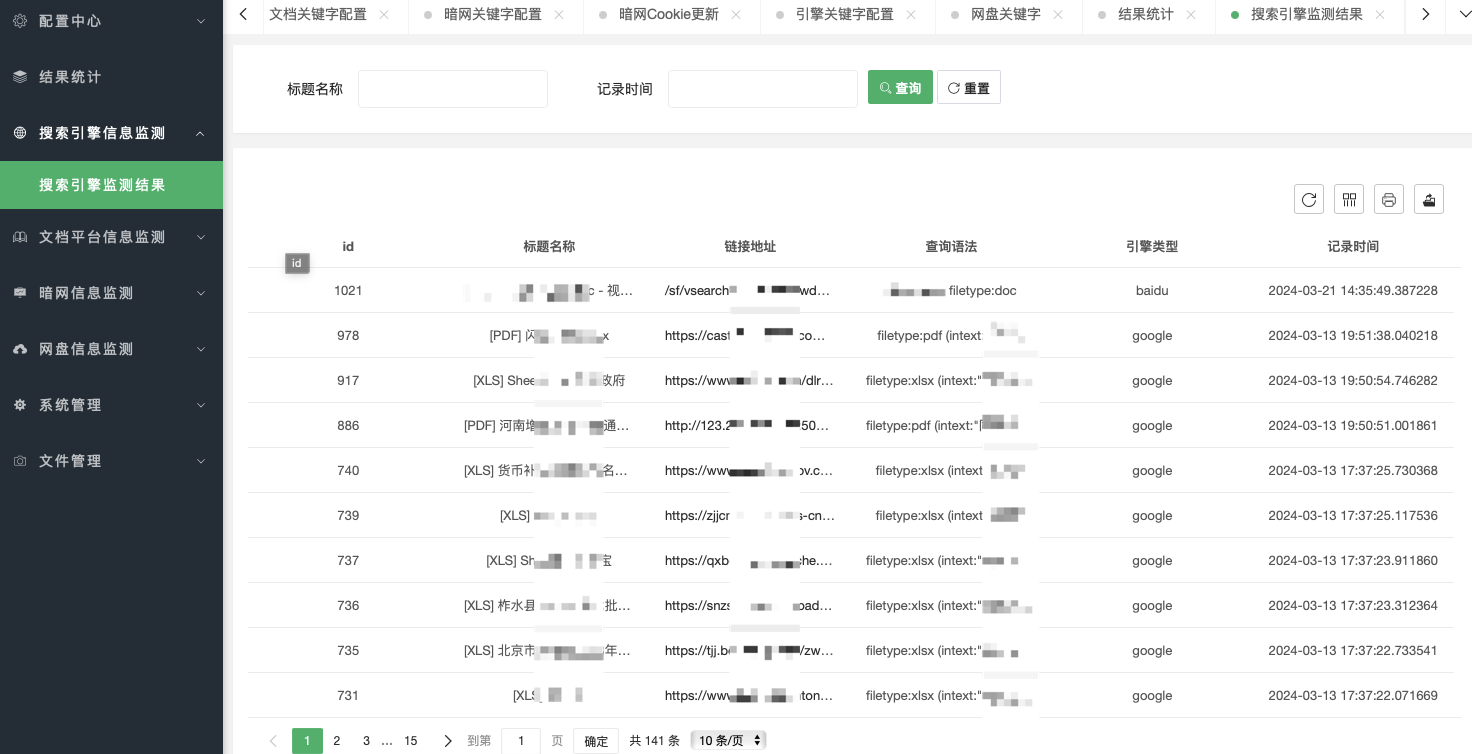
文档平台信息监测用于展示语雀的监测结果
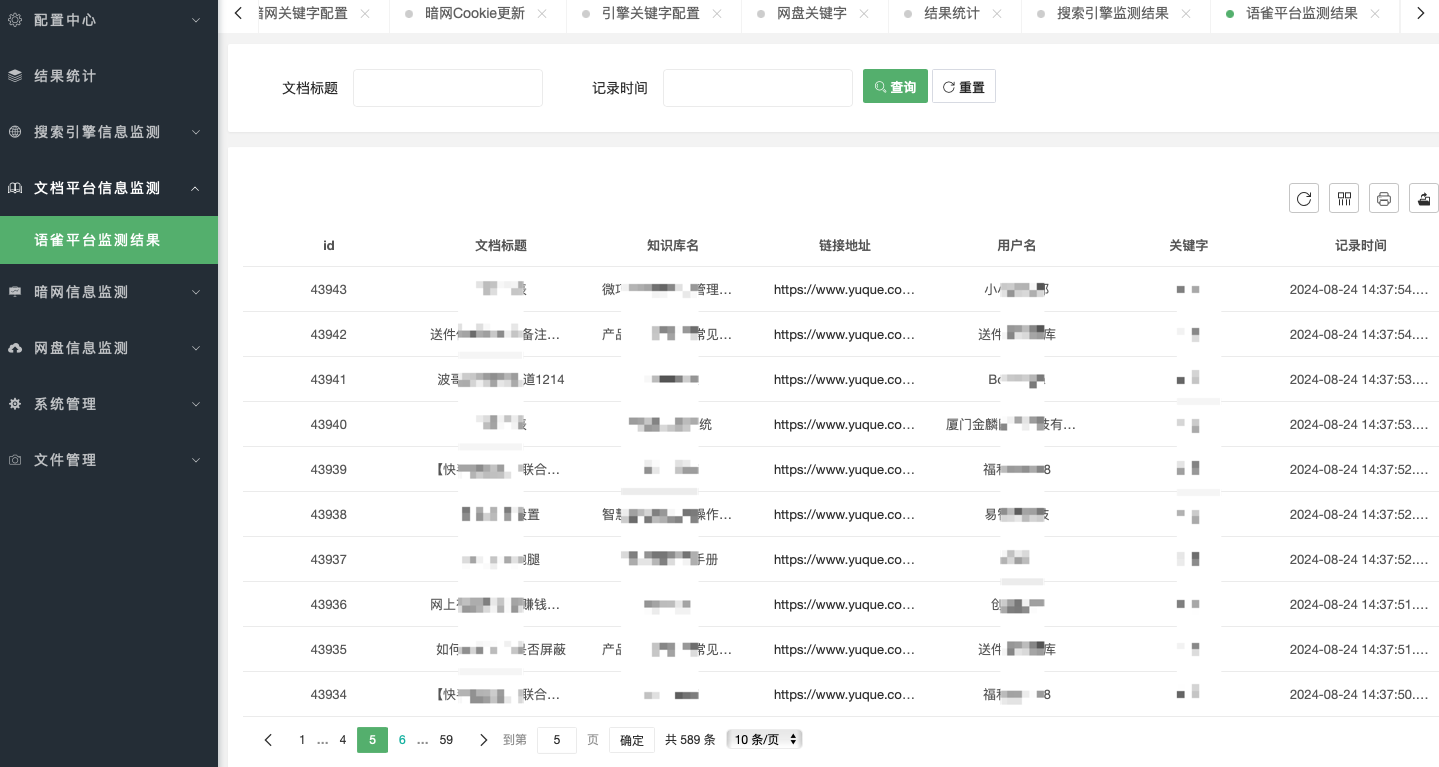
暗网信息监测用于展示暗网的监测结果
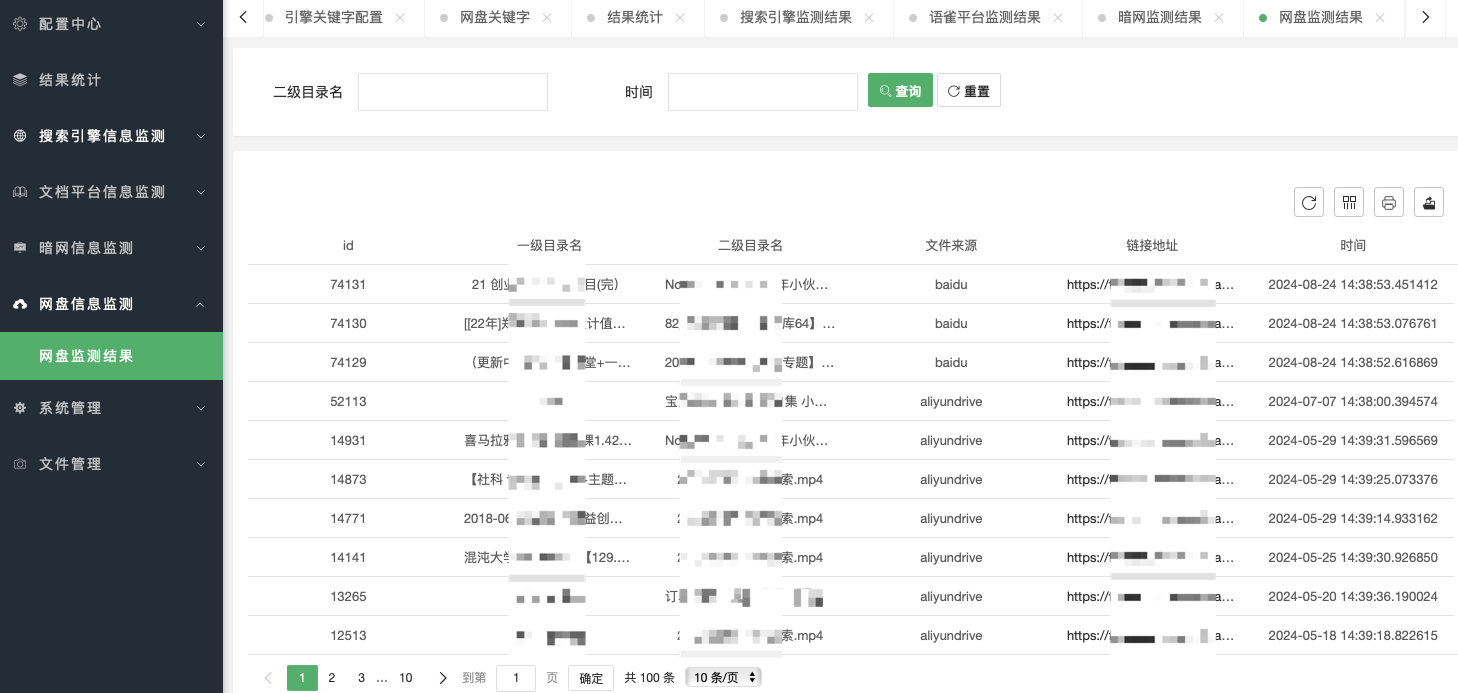
网盘信息监测用于展示网盘的监测结果
四、总结
至此,一个公网信息泄露监测平台基本开发完成,同时支持4种维度8种渠道的监测及告警推送,包含网盘(百度、阿里、夸克)分享泄露信息、搜索引擎(谷歌、百度、duckduckgo)泄露信息、文档平台(语雀)泄露信息、暗网(长安不夜城)情报泄露信息。