实现了String类的大部分封装,采用分文件编译
//mystring.h
#ifndef MYSTRING_H
#define MYSTRING_H#include <iostream>
#include <cstring>
using namespace std;class myString
{
private:char *str; //定义一个字符串int size; //记录字符串长度public://成员函数://1.构造函数myString(const char* s);//2.析构函数~myString();//3.为字符串赋值函数 "="myString & operator=(const myString &other);//4.访问指定字符,有边界检查 "at"char &s_at(int index);//5.访问指定字符 "operator[]"char &s_operator(int index);//6.返回指向字符串首字符的指针 "data"char *s_data();//7.返回字符串的不可修改的C字符数组版本 "c_str"const char* s_c_str()const;//8.检查字符串是否为空 "empty"bool empty();//9.返回字符串长度 "size"int s_size();//10.返回字符串长度 "length"int s_lenth();//11.返回当前对象分配的存储空间能保存的字符数量 "capacity"int s_capacity();//12.清除内容 "clear"void s_clear();//13.后附字符到结尾 "push_back"void s_push_back(char c);//14.移除末尾字符 "pop_back"void s_pop_back();//15.后附字符到结尾 "append"void s_append(const char *s);//16.后附字符到结尾myString &operator+=(const myString &other);//17.连接两个字符串或者一个字符串和一个字符const myString operator+(const myString &other)const;//18.比较字符串bool operator==(const myString &other) const;bool operator!=(const myString &other) const;bool operator<(const myString &other) const;bool operator>(const myString &other) const;bool operator<=(const myString &other) const;bool operator>=(const myString &other) const;//19.输入输出friend ostream &operator<<(ostream &os, const myString &s);friend istream &operator>>(istream &is, myString &s);
};#endif // MYSTRING_H
//mystring.cpp
#include "mystring.h"
myString::myString(const char* s)
{size = strlen(s); //求传入的字符串长度str = new char[size+1]; //申请空间存储字符串strcpy(str,s); //将字符串拷贝到str中
}myString::~myString()
{delete[] str;
}myString &myString::operator=(const myString &other)
{if(this != &other){delete[] str;size = other.size;str = new char[size + 1];strcpy(str, other.str);}return *this;
}char &myString::s_at(int index)
{if(index < 0 || index >= size){cout<<"输入错误"<<endl;}return str[index];
}char &myString::s_operator(int index)
{return str[index];
}char *myString::s_data()
{return str;
}const char *myString::s_c_str() const
{return str;
}bool myString::empty()
{return size == 0;
}int myString::s_size()
{return size;
}int myString::s_lenth()
{return size;
}int myString::s_capacity()
{return size+1; //有一个'\0'
}void myString::s_clear()
{delete[] str;str = NULL;size = 0;
}void myString::s_push_back(char c)
{delete[] str;str = new char[size+1];str[size-1] = c;str[size] = '\0';
}void myString::s_pop_back()
{if(size > 0){size--;str[size] = '\0';}
}void myString::s_append(const char *s)
{int new_size = size + strlen(s);char* temp = str;str = new char[new_size + 1]; // 分配新内存strcpy(str, temp); // 复制旧字符串strcat(str, s); // 追加新字符串delete[] temp; // 释放旧内存size = new_size;
}myString &myString::operator+=(const myString &other)
{s_append(other.str);return *this;
}const myString myString::operator+(const myString &other) const
{myString temp(*this);temp.s_append(other.str);return temp;
}bool myString::operator==(const myString &other) const {return strcmp(str, other.str) == 0;
}bool myString::operator!=(const myString &other) const {return strcmp(str, other.str) != 0;
}bool myString::operator<(const myString &other) const {return strcmp(str, other.str) < 0;
}bool myString::operator>(const myString &other) const {return strcmp(str, other.str) > 0;
}bool myString::operator<=(const myString &other) const {return strcmp(str, other.str) <= 0;
}bool myString::operator>=(const myString &other) const {return strcmp(str, other.str) >= 0;
}istream &operator>>(istream &is, myString &s)
{char buffer[1024]; // 假设输入的字符串不超过1024个字符is >> buffer; // 从输入流中读取字符串s = buffer; // 将读取的字符串赋值给 myString 对象return is; // 返回输入流的引用
}ostream &operator<<(ostream &os, const myString &s)
{os<<s.s_c_str();return os;
}
//main.cpp
#include "mystring.h"
int main()
{myString s1("hello");cout<<s1<<endl;cout<<"*************************"<<endl;myString s2("world");cout<<s1+s2<<endl;if(s1>s2 == 1){cout<<"s1 > s2"<<endl;}else{cout<<"s1 < s2"<<endl;}return 0;
}
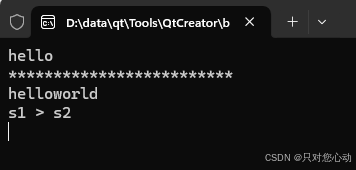
输出结果如下:
![[知识分享]华为铁三角工作法](https://img-blog.csdnimg.cn/img_convert/dc1000105906abf8f24e79a8ced414ec.png)