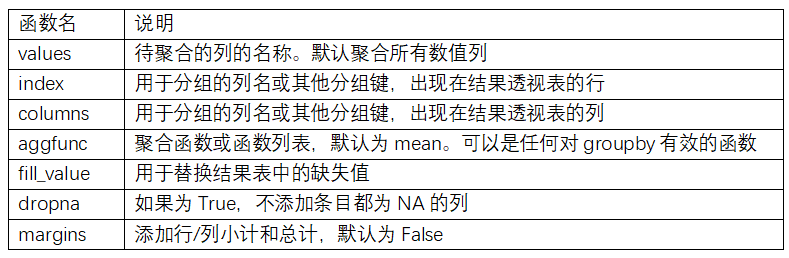
前言
OpenAI(LLM + Embedding)是使用LiteLLM + ollama模拟,具体做法如下,
Llamaindex OpenAI LLM 模型默认使用的是gpt-3.5-turbo, embedding 模型默认使用的是text-embedding-ada-002, 所以这里使用litellm 配合config来模拟,
一句话介绍LiteLLM
使用OpenAI格式调用所有LLM API。使用Bedrock,Azure,OpenAI,Cohere,Anthropic,Ollama,Sagemaker,HuggingFace,Replicate(100+ LLM)。
安装LiteLLM
pip install 'litellm[proxy]'
模型映射
创建litellm.yaml

运行litellm
litellm --config litellm.yaml
💡,这样模拟的OpenAI不支持function call,所以index.as_chat_engine(chat_mode="condense_question") 不能使用默认的chat_mode。
如果想部署并使用开源模型,不需要这么麻烦,我们可以根据需要选择合适的方案,这里我介绍下ollama的实现。

llama.cpp
Ollama
Ollama 提供了多种LLM模型和embedding模型(如all-minilm,mxbai-embed-large,nomic-embed-text,snowflake-arctic-embed 等), 如果没有你想用的,也可以自己导入gguf格式模型。
关于ollama,这里就不展开了,有兴趣的可以看看我的另外一篇文章:[ollama 使用技巧集锦](https://mp.weixin.qq.com/s?__biz=MzU1NTg2ODQ5Nw==&mid=2247489345&idx=1&sn=342eea6917c3 ba45e3da9146dcb4ec45&chksm=fbcc9f7fccbb16691c5a43ca5b454af2a59d4387d206024ae61f046a12431469bfe16e2d7c05&token=964566570&lang=zh_CN&scene=21#wechat_redirect)
安装包
pip install llama-index-embeddings-ollama
pip install llama-index-llms-ollama
代码
from llama_index.core import VectorStoreIndex, Document, SimpleDirectoryReader,Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
# 指定LLM
Settings.llm = Ollama(model="wizardlm2:7b-q5_K_M", request_timeout=60.0)
# 指定 embedding model
Settings.embed_model = OllamaEmbedding(model_name="snowflake-arctic-embed:latest")
## 剩下代码一样
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
print(chat_engine.chat("DuckDB的VSS扩展主要功能, reply in Chinese"))
结论
至此,一个基于ollama的rag就有雏形了。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。