01
背景
近年来,人工智能(AI)技术,特别是自然语言处理(NLP)的飞速发展深刻影响着各个行业。从智能客服到内容生成,从语音识别到翻译工具,NLP的应用已经无处不在。在这一领域中,预训练模型(Pre-trained Models)逐渐成为核心技术,它们通过在大规模语料库上进行训练,学习到丰富的语言知识和语义表达,为后续的下游任务提供了强大的支持。
预训练模型的效果在很大程度上依赖于其所使用的数据集,高质量的数据集能够让模型学习到更加准确和全面的语言特征,从而在各种应用场景中表现出色。然而,目前市面上大多数高质量的预训练数据集主要集中在英文领域,针对中文的高质量数据集则相对匮乏。虽然国内外一些公司和研究机构已经开始着手构建中文数据集,但数量有限,且数据质量参差不齐,难以满足快速发展的中文NLP应用需求。
在此背景下,OpenCSG算法团队决定发起一个重要项目:中文版Fineweb Edu数据集。Huggingface Fineweb Edu数据集在国际上已经有一定的知名度,其英文版本被广泛应用于教育领域的自然语言处理任务。然而,针对中文语言环境,仍然缺乏一个能够与之媲美的高质量数据集。为了弥补这一空白,OpenCSG的团队将Fineweb Edu数据集的构建经验引入中文领域,并根据中文的语言特点和教育需求进行了本地化的调整与优化。
此次发布的中文版Fineweb Edu数据集不仅填补了中文预训练数据集的空白,还标志着OpenCSG开源社区在推动中文NLP技术发展方面迈出了重要的一步。这一数据集的发布,将为国内外研究人员提供一个强大的工具,帮助他们在教育领域的NLP任务中取得更好的成果。OpenCSG作为国内大模型开源社区的代表,致力于将更多高质量的数据和模型资源带给全球的AI研究人员与开发者,以此促进AI技术的持续进步和广泛应用。

02
Huggingface Fineweb数据集介绍
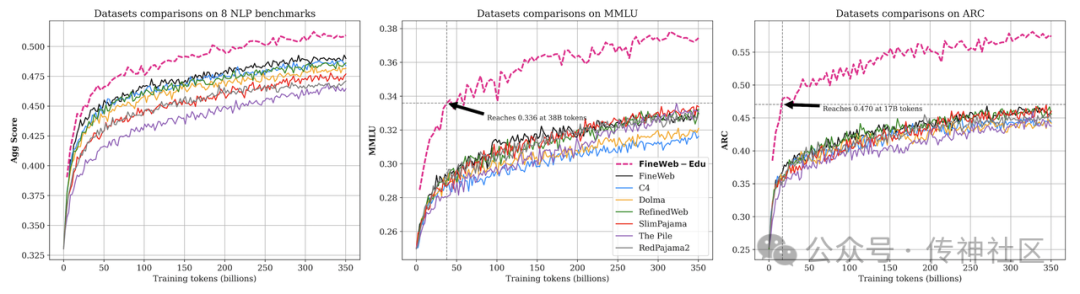
Huggingface的FineWeb数据集在2024年5月31日首次发布,是一个面向大型语言模型(LLMs)预训练的大开源数据集,旨在推动自然语言处理领域的研究与应用。该数据集集合了来自CommonCrawl的96个快照数据,总共包含超过15万亿个token,占据44TB的磁盘空间。这些数据涵盖了从2013年至2024年的网页内容,通过精心设计的处理流程,FineWeb提供了丰富且多样的高质量语料资源,为训练更强大、更精确的语言模型提供了高质量数据。

FineWeb数据集的构建不仅依赖于庞大的数据量,更在于其精细的处理过程。首先,在数据提取和清洗环节,Huggingface团队采用了先进的过滤策略来保证数据的质量。例如,他们使用了语言分类、URL过滤等方法去除非英语文本和不合适的内容,并应用了启发式过滤器来删除过度重复的内容或那些未能正确结束的文档。这些措施确保了数据集在保持规模的同时,拥有高质量的内容。
为了进一步提升模型的训练效果,FineWeb在去重处理上采用了MinHash模糊哈希技术。通过这项技术,团队能够高效地移除数据中的重复部分,从而降低了模型对重复内容的记忆,这对于提高模型在多样化文本理解上的表现至关重要。具体而言,FineWeb的数据去重过程包括逐个快照的去重和全局去重,这种多层次的去重策略确保了数据集的独特性和质量。
此外,FineWeb还推出了一个专门针对教育内容的子集——FineWeb-Edu。这个子集通过Llama-3-70B-Instruct模型生成的合成注释进行分类和过滤,最终形成了一个1.3万亿token的教育类数据集,特别适合用于教育领域的基准测试,如MMLU、ARC和OpenBookQA等。
数据集链接:https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu
03
国内主流开源预训练数据集介绍
在构建高质量的中文预训练模型时,数据集的选择至关重要。以下是一些与我们数据来源相关的国内主流开源预训练数据集的介绍,这些数据集虽然提供了大量的中文数据,但其质量和处理方法各有不同,质量参差不齐。
1. CCI2-Data
为了解决中文高质量安全数据集的稀缺问题,BAAI于2023年11月29日开源了CCI(Chinese Corpora Internet)数据集,并在此基础上进一步扩展数据来源,采用更严格的数据清洗方法,完成了CCI 2.0数据集的构建。CCI 2.0由来自可靠互联网来源的高质量数据组成,经过严格的清洗、去重和质量过滤处理。数据处理包括基于规则的关键词和垃圾信息过滤、基于模型的低质量内容筛选,以及数据集内部和之间的去重处理。最终发布的CCI 2.0语料库总容量为501GB,是一个高质量且可靠的中文安全数据集。
2. SkyPile-150B
SkyPile-150B是一个专为大规模语言模型预训练设计的综合性中文数据集,涵盖了来自广泛的公开中文互联网网页的数据。为了确保数据质量,SkyPile-150B经过了严格的过滤、广泛的去重以及全面的敏感数据过滤处理。还使用了先进的工具,如fastText和BERT,来过滤低质量数据。该数据集的公开部分包含约2.33亿个独特的网页,每个网页平均包含超过1000个汉字。整个数据集共计约1500亿个tokens,纯文本数据的总容量达620GB,全部为中文数据。
3. IndustryCorpus
IndustryCorpus 是一个由BAAI发布的多行业中文预训练数据集,旨在提升行业模型的性能。该数据集总量约为3.4TB,涵盖了包括医疗、教育、法律、金融等在内的18个行业的数据。IndustryCorpus的数据来自Wudao等多个大型数据集,并经过22个行业特定数据处理操作的精细清洗和过滤,最终生成了1TB的高质量中文数据和2.4TB的英文数据。由于其丰富的行业覆盖和严格的数据处理流程,该数据集特别适用于行业特定的语言模型训练,已经在医学领域的模型训练中展示了显著的性能提升。
4. Tele-AI
TeleChat-PTD是一个从电信星辰大模型TeleChat预训练语料中抽取出的综合性大规模中文数据集,数据集的原始大小约为1TB,经过压缩后为480GB,共分为189个文件。该数据集的数据主要来源于网页、书籍和官方媒体等多种渠道。采用了规则和模型结合的方式对数据进行了相关的过滤,并进行了相似性去重,但要训练好的模型还需要更高质量的处理。
5. MAP-CC
MAP-CC(Massive Appropriate Pretraining Chinese Corpus)是一个规模庞大的中文预训练数据集,专为训练中文大模型而设计。该数据集包含800亿个Token,由多个子集组成,每个子集都来自不同的数据源,如:博客、新闻文章、中文百科全书、中文学术论文、中文图书等。尽管MAP-CC进行了一系列的去重处理和低质量数据筛除,但以客观的眼光来看数据质量还是偏低,往往需要进一步筛选才能用于训练。
04
Chinese Fineweb Edu 数据集构建方法
数据集简介
Chinese Fineweb Edu 数据集是一个精心构建的高质量中文预训练语料数据集,专为教育领域的自然语言处理任务设计。该数据集通过严格的筛选和去重流程,利用少量数据训练打分模型进行评估,从海量的原始数据中提取出高价值的教育相关内容,确保数据的质量和多样性。最终,数据集包含约90M条高质量的中文文本数据,总大小约为300GB。

下载地址:
OpenCSG社区:https://opencsg.com/datasets/OpenCSG/chinese-fineweb-edu
huggingface社区:https://huggingface.co/datasets/opencsg/chinese-fineweb-edu
筛选方法
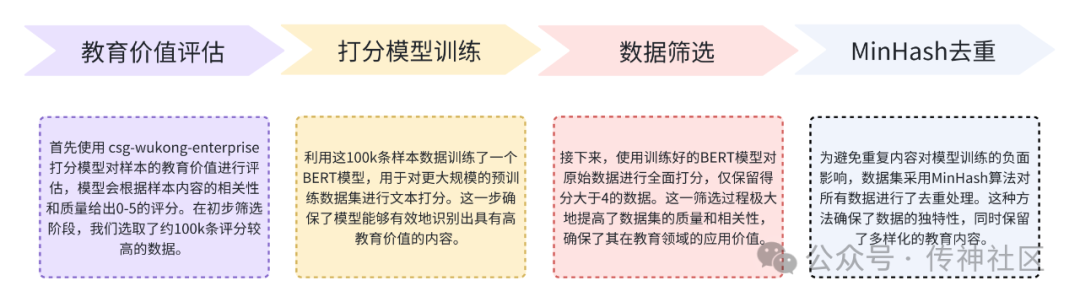
在数据筛选过程中,Chinese Fineweb Edu 数据集采用了与 Fineweb-Edu 类似的筛选策略,重点关注数据的教育价值和内容质量。具体筛选步骤如下:
-
教育价值评估:首先使用csg-wukong-enterprise打分模型对样本的教育价值进行评估,模型会根据样本内容的相关性和质量给出0-5的评分。在初步筛选阶段,我们选取了约100k条评分较高的数据。
-
打分模型训练:利用这100k条样本数据训练了一个BERT模型,用于对更大规模的预训练数据集进行文本打分。这一步确保了模型能够有效地识别出具有高教育价值的内容。
-
数据筛选:接下来,使用训练好的BERT模型对原始数据进行全面打分,仅保留得分大于4的数据。这一筛选过程极大地提高了数据集的质量和相关性,确保了其在教育领域的应用价值。
-
MinHash去重:为避免重复内容对模型训练的负面影响,数据集采用MinHash算法对所有数据进行了去重处理。这种方法确保了数据的独特性,同时保留了多样化的教育内容。
原始数据来源
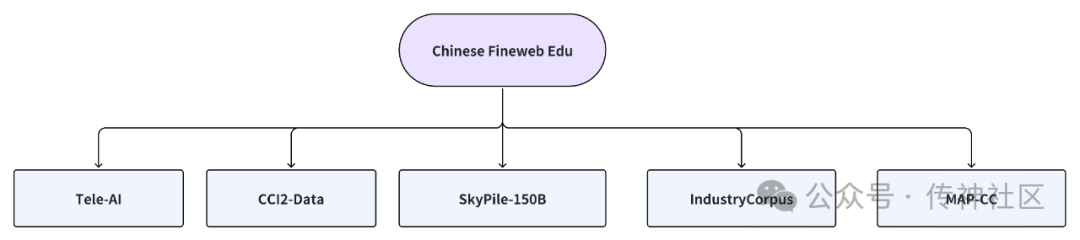
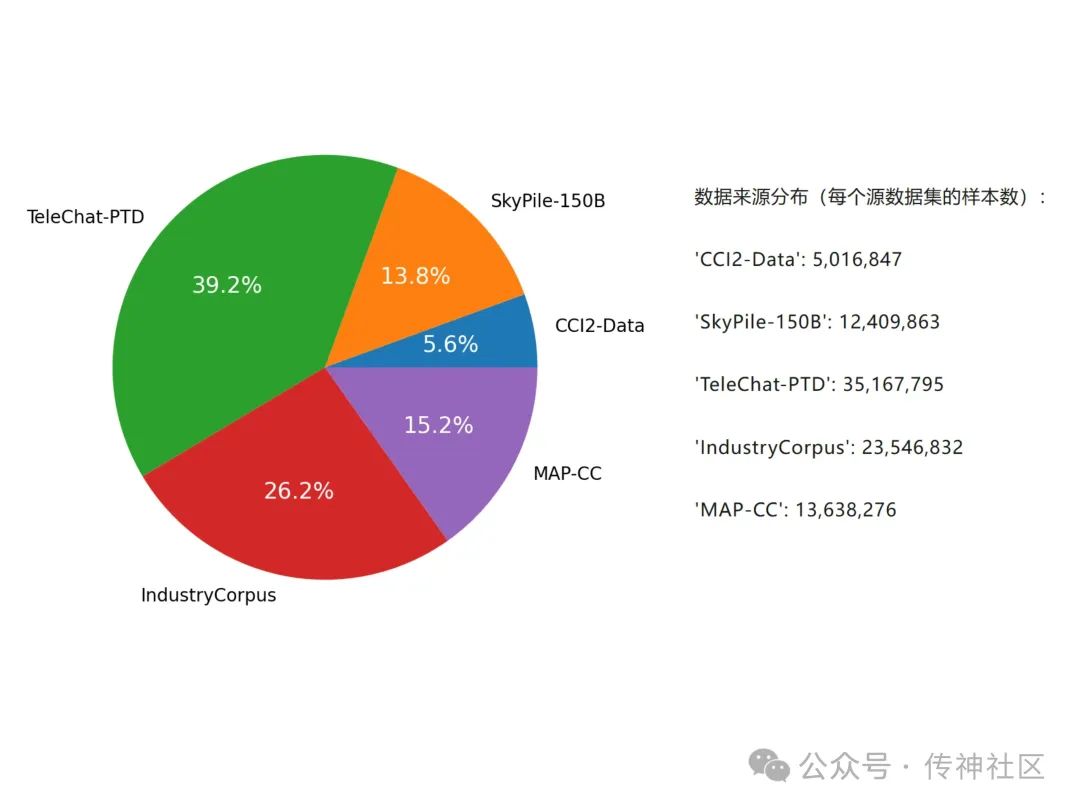
Chinese Fineweb Edu 数据集的原始数据来源广泛,涵盖了多个国内主流的中文预训练数据集。这些数据集虽然在规模和覆盖领域上各有不同,但通过精细筛选和处理,最终为Chinese Fineweb Edu 数据集提供了坚实的基础。主要数据来源包括:
-
CCI2-Data:经过严格的清洗、去重和质量过滤处理,一个高质量且可靠的中文安全数据集。
-
SkyPile-150B:一个来自中国互联网上的1500亿token大规模数据集,经过复杂的过滤和去重处理
-
IndustryCorpus:一个涵盖多个行业的中文预训练数据集,包含1TB的中文数据,特别适合行业特定的模型训练
-
Tele-AI:一个从电信星辰大模型TeleChat预训练语料中提取出的高质量大规模中文数据集,包含约2.7亿条经过严格过滤和去重处理的纯中文文本。
-
MAP-CC:一个规模庞大的中文预训练语料库,结合了多种来源的高质量数据,特别针对中文语言模型的训练进行了优化
这些多样化的数据来源不仅为Chinese Fineweb Edu 数据集提供了丰富的内容基础,还通过不同领域和来源的数据融合,提升了数据集的广泛适用性和全面性。这种数据整合方式确保了模型在面对多样化的教育场景时,能够保持卓越的表现和高质量的输出。
打分模型
我们使用OpenCSG的csg-wukong-enterprise企业版大模型作为打分模型,通过设计prompt,让其对每一条预训练样本进行打分,分数分为0-5分共6个等级:
0分:如果网页没有提供任何教育价值,完全由无关信息(如广告、宣传材料)组成。
1分:如果网页提供了一些与教育主题相关的基本信息,即使包含一些无关或非学术内容(如广告和宣传材料)。
2分:如果网页涉及某些与教育相关的元素,但与教育标准不太吻合。它可能将教育内容与非教育材料混杂,对潜在有用的主题进行浅显概述,或以不连贯的写作风格呈现信息。
3分:如果网页适合教育使用,并介绍了与学校课程相关的关键概念。内容连贯但可能不全面,或包含一些无关信息。它可能类似于教科书的介绍部分或基础教程,适合学习但有明显局限,如涉及对中学生来说过于复杂的概念。
4分:如果网页对不高于中学水平的教育目的高度相关和有益,表现出清晰一致的写作风格。它可能类似于教科书的一个章节或教程,提供大量教育内容,包括练习和解答,极少包含无关信息,且概念对中学生来说不会过于深奥。内容连贯、重点突出,对结构化学习有价值。
5分:如果摘录在教育价值上表现出色,完全适合小学或中学教学。它遵循详细的推理过程,写作风格易于理解,对主题提供深刻而全面的见解,不包含任何非教育性或复杂内容。
我们记录了100k条数据及其得分,形成fineweb_edu_classifier_chinese_ data。将数据集中的得分作为文本打分的标签,我们训练了一个中文Bert模型 fineweb_edu_classifier_chinese,此模型能够为每条输入文本给出0-5分的得分。我们会进一步优化这个打分模型,未来,OpenCSG算法团队将开源fineweb_edu_classifier_chinese_data数据集以及fineweb_edu_classifier _chinese打分模型,以进一步推动社区的发展和交流。该数据集包含了经过精细标注打分的教育领域文本数据,能够为研究人员和开发者提供高质量的训练数据。
消融实验
经过精心设计的消融实验,我们旨在对比 Chinese-fineweb-edu 数据集与传统中文预训练语料的效果差异。为此,我们从 CCI2-Data、SkyPile-150B、TeleChat-PTD、IndustryCorpus 和 MAP-CC 这五个数据集中,随机抽取了与 Chinese-fineweb-edu 数据比例相同的样本,构建了一个对比数据集chinese-random-select。
实验中,我们使用了一个 2.1B 参数规模的模型,预训练了 65k 步。在训练过程中,我们定期保存模型的 checkpoint,并在中文评测基准 CEval 和 CMMLU 数据集上进行了验证。下图展示了这两个数据集在评测任务中的表现变化趋势。
从结果可以清晰看出,使用 Chinese-fineweb-edu 训练的数据集在两个评测任务中均显著优于 chinese-random-select 数据集,特别是在训练到后期时表现出极大的优势,证明了 Chinese-fineweb-edu 在中文语言任务中的有效性和适配性。这一实验结果也进一步表明,数据集的选择和构建对模型的最终性能有着关键性的影响。
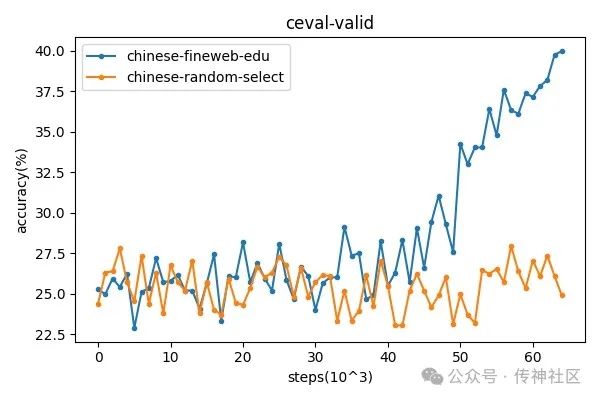
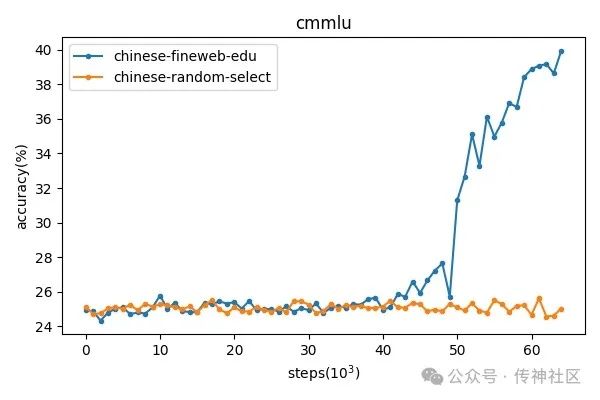
通过实验结果可以发现,在训练的靠后阶段,可能是由于进入了第2个epoch,且学习率进入快速下降阶段,训练的效果开始逐渐涌现,此时,使用chinese-fineweb-edu训练的模型,准确率有了明显的上升,而使用随机抽取的数据训练,则一直处于较低水平。这证明了chinese-fineweb-edu有更高的数据质量,适合作为模型预训练数据,在同样训练时间下,能够更快的提升模型能力。这一结果与英文版的fineweb-edu一致。
我们诚邀对这一领域感兴趣的开发者和研究者关注和联系社区,共同推动技术的进步。敬请期待数据集的开源发布!
消融模型链接
csg-wukong-ablation-chinese-random:
OpenCSG:https://opencsg.com/models/OpenCSG/csg-wukong-ablation-chinese-random
Hugging Face:https://huggingface.co/opencsg/csg-wukong-ablation-chinese-random
csg-wukong-ablation-chinese-fineweb-edu:
OpenCSG:https://opencsg.com/models/OpenCSG/csg-wukong-ablation-chinese-fineweb-edu
Hugging Face:https://huggingface.co/opencsg/csg-wukong-ablation-chinese-fineweb-edu
参考链接
-
CCI2-DATA:
https://huggingface.co/datasets/BAAI/CCI2-Data
-
IndustryCorpus:
https://huggingface.co/datasets/BAAI/IndustryCorpus
-
MAP-CC:https:
https://huggingface.co/datasets/m-a-p/MAP-CC
-
SkyPile-150B:
https://huggingface.co/datasets/Skywork/SkyPile-150B
-
TeleChat-PTD:
https://huggingface.co/datasets/Tele-AI/TeleChat-PTD
作者及单位
原文作者:俞一炅、戴紫赟、Tom Pei
单位:OpenCSG LLM Research Team

欢迎加入OpenCSG开源社区
OpenCSG作为一家大模型开源社区,基于线上线下一体的CSGHub平台上开源了丰富的训练数据资产、模型资产可以供广大的爱好者免费获取。其中OpenCSG的 Open是开源开放;C 代表 Converged resources,整合和充分利用的混合异构资源优势,算力降本增效;S 代表 Software Refinement,重新定义软件的交付方式,通过大模型驱动软件开发,人力降本增效;G 代表 Generative LM,大众化、普惠化和民主化的可商用的开源生成式大模型。OpenCSG的愿景是让每个行业、每个公司、每个人都拥有自己的模型。我们坚持开源开放的原则,将OpenCSG的大模型软件栈开源到社区。欢迎使用、反馈和参与共建,欢迎关注和Star⭐️
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https:// github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验


















