今天测试了一下在华鲲振宇公司的天工TG225 B1国产服务器上进行openEuler22.03 -SP4操作系统的试装,本文记录整个测试过程。
一、服务器信息
1、服务器型号
Huakun TG225 B1 (D)
2、登录IPMI帐户信息
初始用户名Tech.ON 密码TianGong8000@

二、磁盘RAID配置
测试机自带480GB SSD系统盘两块,1.92TB SSD数据盘两块,分别配置为RAID1
1、配置系统盘
在BMC界面“系统管理-存储管理”中选中RAID卡右侧的添加
自定义逻辑盘名称,RAID级别并选中相应物理盘

如果不是新机,建议勾选初始化选项为快速初始化

刷新界面,可以看到系统逻辑盘已建好

2、配置数据盘
同样新建数据盘的逻辑盘

配置完成后刷新,结果如下

三、安装系统
1、下载镜像
天工TG225 B1国产服务器使用的是华为的鲲鹏Kunpeng-920 CPU,需使用aarch64架构的操作系统,测试使用openEuler22.03 -SP4系统。下载链接如下
openEuler-22.03-LTS-SP4-everything-aarch64-dvd.iso
2、打开虚拟控制台

3、挂载镜像

4、挂载并连接镜像

5、修改启动引导为光驱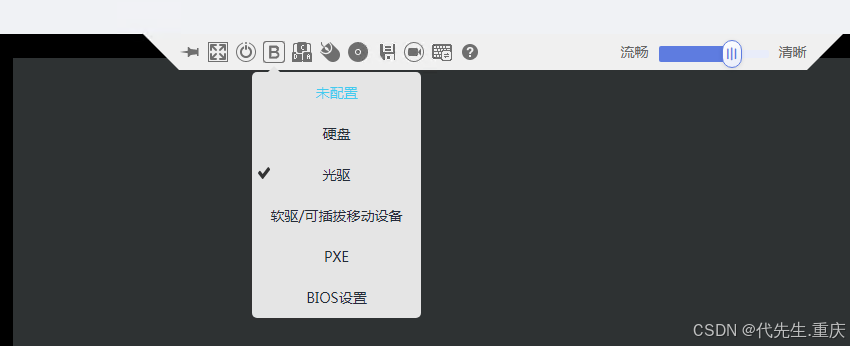
6、重启服务器

7、选择直接安装

8、修改安装界面语言

9、选择安装位置
安装到480GB的系统盘,测试使用自动分区即可

10、启用root帐户和普通帐户
11、开始并完成安装

四、检查结果
1、查看系统信息
可以看到系统为aarch64架构的openEuler22.03 -SP4

2、查看CPU信息
可以看到是海思的Kunpeng-920 CPU,CPU核数为96。

试装完成。



















