
论文链接:https://arxiv.org/pdf/2409.02097
Git链接:https://lv-linfusion.github.io/
亮点直击
本文研究了Mamba的非因果和归一化感知版本,并提出了一种新颖的线性注意力机制,解决了扩散模型在高分辨率视觉生成中的挑战。
本文的理论分析表明,所提出的模型在技术上是现有流行的线性复杂度token混合器的广义且高效的低秩近似。
在Stable Diffusion (SD)上的大量实验表明,所提出的LinFusion可以实现比原始SD更好的结果,并且在零样本跨分辨率生成性能和与现有SD组件的兼容性方面表现令人满意。据本文所知,这是首次在SD系列模型上探索线性复杂度token混合器用于文本到图像生成。
总结速览
解决的问题
-
现有基于Transformer的UNet模型在生成高分辨率视觉内容时面临时间和内存复杂度的挑战,特别是在处理空间token数量时。
提出的方案
-
提出一种新颖的线性注意力机制作为替代方案,并引入广义的线性注意力范式。
应用的技术
-
线性注意力机制
-
线性复杂度模型(如Mamba、Mamba2和Gated Linear Attention)
-
预训练模型(如StableDiffusion)
达到的效果
-
LinFusion蒸馏模型在性能上与原始StableDiffusion相当或更优,同时显著减少了时间和内存复杂度。
-
在SD-v1.5、SD-v2.1和SD-XL上的实验表明,LinFusion在零样本跨分辨率生成性能方面表现出色,能够生成高达16K分辨率的图像。
-
与预训练的StableDiffusion组件(如ControlNet和IP-Adapter)高度兼容,无需适配工作。


方法
准备知识
扩散模型。 作为一种流行的文本到图像生成模型,Stable Diffusion (SD) 首先学习一个自动编码器 ,其中编码器 将图像 映射到低维潜在空间:,解码器 学习将 解码回图像空间:,使得 接近原始图像 。在推理时,潜在空间中的高斯噪声 被随机采样,并通过UNet 进行 步去噪。最终步骤后的去噪潜在代码 由 解码生成图像。在训练中,给定图像 及其对应的文本描述 , 被用来获得其对应的潜在代码,并添加随机高斯噪声 生成其噪声版本 ,对应第 步。UNet 通过噪声预测损失 进行训练:

UNet中的自注意力层作为token混合器来处理空间关系,而多个交叉注意力层则处理文本-图像关系。给定UNet骨干网络中的输入特征图 和权重参数 以及 ,其中 是空间tokens的数量, 是特征维度, 是注意力维度,自注意力可以形式化为:

本文可以从公式(2)中观察到,自注意力的复杂度相对于是二次的,因为注意力矩阵。在本文中,本文主要关注其替代方案,并致力于一种具有线性复杂度的新型token混合模块。
Mamba。 作为Transformer 的替代方案,Mamba 被提出用于处理相对于序列长度具有线性复杂度的序列任务。Mamba的核心是状态空间模型(SSM),其可以写成:

其中,是序列中当前token的索引,表示隐藏状态,和是表示输入和输出矩阵第行的行向量,、和是依赖于输入的变量,表示元素级乘法。
在最新版本,即Mamba2中,是一个标量,,,。根据状态空间对偶性(State-Space Duality, SSD),公式(3)中的计算可以重新表述为以下表达式,被称为1-半可分结构Masked注意力(1-Semiseparable Structured Masked Attention):
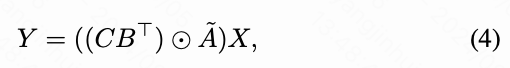
其中 是一个 的下三角矩阵,并且 对于 。这种矩阵 被称为 1-半可分矩阵,确保 Mamba2 可以以线性复杂度实现。
在本文中,本文旨在为通用的文本到图像问题设计一个线性复杂度的扩散骨干。为此,本文没有从头开始训练一个新模型,而是从预训练的 Stable Diffusion(SD)模型中初始化和蒸馏模型。具体来说,本文默认使用 SD-v1.5 模型,并用本文提出的 LinFusion 模块替换其自注意力——这是二次复杂度的主要来源。只有这些模块中的参数是可训练的,而模型的其余部分保持冻结状态。本文从原始 SD 模型中蒸馏知识到 LinFusion 模块,使得在给定相同输入的情况下,它们的输出尽可能接近。下图 3 提供了这一流程的概述。
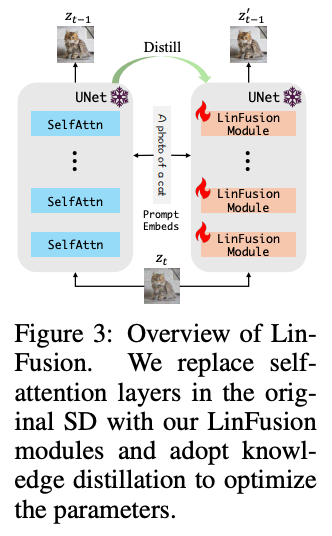
这种方法提供了两个关键好处:(1) 训练难度和计算开销显著降低,因为学生模型只需要学习空间关系,而不需要处理其他方面的复杂性,如文本-图像对齐;(2) 生成的模型与在原始 SD 模型及其微调变体上训练的现有组件高度兼容,因为本文只用 LinFusion 模块替换了自注意力层,这些模块被训练得与原始模块功能相似,同时保持整体架构。
技术上,为了推导出一个线性复杂度的扩散骨干,一个简单的解决方案是用 Mamba2 替换所有的自注意力块,如下图 4(a) 所示。本文应用双向 SSM 确保当前位置可以访问后续位置的信息。此外,Stable Diffusion 中的自注意力模块没有像 Mamba2 那样结合门控操作或 RMS-Norm。如下图 4(b) 所示,本文移除了这些结构以保持一致性,并在性能上略有提升。在本节的后续部分,本文深入探讨了将 SSM(Mamba2 的核心模块)应用于扩散模型的问题,并相应地介绍了 LinFusion 的关键特性:归一化和非因果性,最后,本文提供了优化 LinFusion 模块中参数的训练目标。
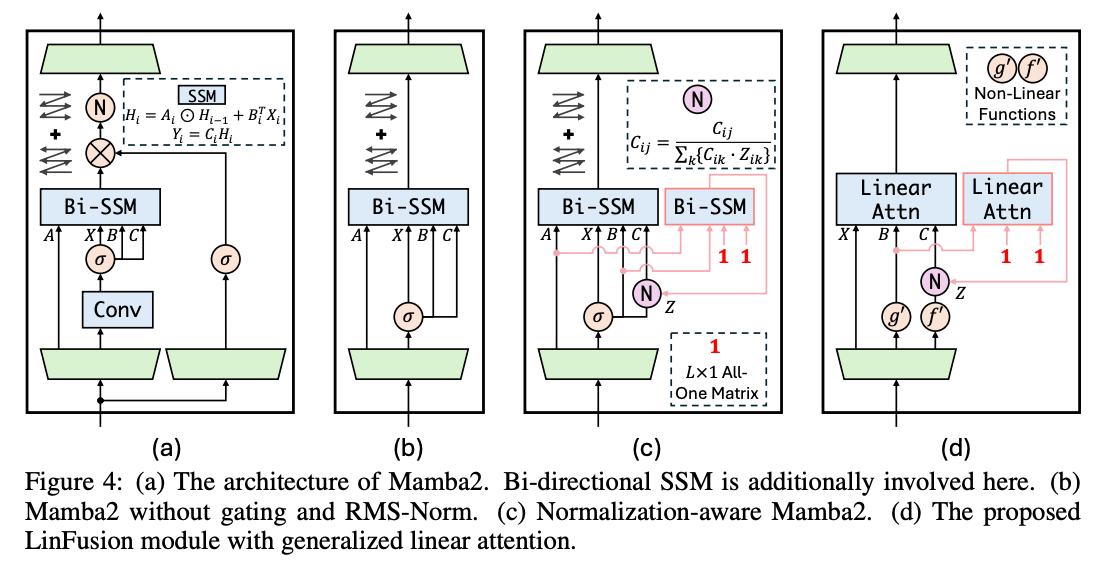
规范化感知 Mamba
在实践中,本文发现如果训练和推理阶段的图像分辨率一致,上图4(b)中展示的基于SSM的结构可以实现令人满意的性能。然而,当图像尺度不一致时,它会失败。为了确定这一失败的原因,本文检查了输入和输出特征图的通道均值,发现以下命题:
命题1:假设输入特征图 中第 个通道的均值是 ,并将 表示为 ,则输出特征图 中该通道的均值为 。
证明是直接的。通过上图4(b)本文观察到,对 、 和 应用了非负激活。鉴于在 Mamba2 中 也是非负的,根据命题1,如果训练和推理阶段的 不一致,通道分布将发生偏移,进而导致结果失真。
解决这个问题需要统一每个token对其他token的影响到相同的尺度,这一特性本质上由Softmax函数提供。鉴于此,本文在本文中提出了归一化感知的 Mamba,强制每个token的注意力权重之和等于1,即,这等价于再应用一次SSM模块以获得归一化因子 。

操作如上图4(c)所示。实验表明,这种归一化显著提高了零样本跨分辨率泛化的性能。
非因果 MAMBA
双向扫描使得一个token能够从后续的tokens中接收信息——这是扩散骨干网络的一个关键特性——但是将特征图视为一维序列会损害二维图像和更高维视觉内容的内在空间结构。为了解决这个问题,本文在本文中着重开发了非因果版本的Mamba。非因果性意味着一个token可以访问所有的tokens进行信息混合,这可以通过简单地去除应用在上的下三角因果mask 来实现。因此,公式(3)中的递归公式将变为:
本文观察到,在这个公式中,相对于保持不变。这意味着所有tokens的隐藏状态是均匀的,这从根本上破坏了遗忘门的预期目的。为了解决这个问题,本文将不同的组与各种输入tokens关联。在这种情况下,是一个的矩阵,并且 公式(4)中的变为。与公式(4)中的相比,这里的不一定是1-半可分的。为了保持线性复杂度,本文假设是低秩可分的,即存在输入相关的矩阵和使得。通过这种方式,以下命题确保了在这种情况下,公式(4)可以通过线性注意力实现:
命题2:给定,,以及,表示,,,和,存在相应的函数和使得公式(4)可以等效地通过线性注意力实现,表示为:
证明。根据已知条件,本文有:
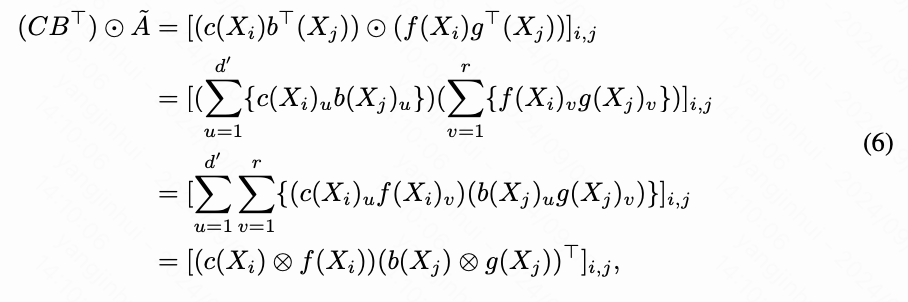
在这里, 表示克罗内克积。本文定义 和 ,由此得到 。
在实际应用中,本文采用两个多层感知机(MLP)来模拟 和 的功能。结合前文中提到的归一化操作,本文得到了上图 4(d) 所示的优雅结构。
不仅如此,本文进一步证明了命题 2 中描述的线性注意形式可以扩展到更一般的情况,其中 是一个维度为 的向量,而不是一个标量:
命题 3:假设 ,如果对于每个 , 是低秩可分离的:,其中 ,,,则存在相应的函数 和 ,使得计算 可以等效地实现为线性注意,表示为 ,其中 是一个列向量,可以广播到一个 的矩阵。
证明。根据已知条件,本文有:

其中 和 是 矩阵, 表示带广播的逐元素乘法, 表示将矩阵展平为行向量。本文定义 和 ,由此得到 。
从这个角度来看,所提出的结构可以视为一种广义线性注意机制,以及最近线性复杂度序列模型的非因果形式,包括 Mamba2、RWKV6、GLA等。在下表 1 中,本文提供了最近工作的参数化总结,用于 。

训练目标
在本文中,本文将原始SD中的所有自注意力层替换为LinFusion模块。只有这些模块中的参数会被训练,而其他所有参数保持不变。为了确保LinFusion能够紧密模仿自注意力的原始功能,本文在公式1中的标准噪声预测损失上增加了额外的损失。具体而言,本文引入了一种知识蒸馏损失,用于对齐学生模型和教师模型的最终输出,以及一种特征匹配损失,用于匹配每个LinFusion模块的输出与相应自注意力层的输出。训练目标可以写成:
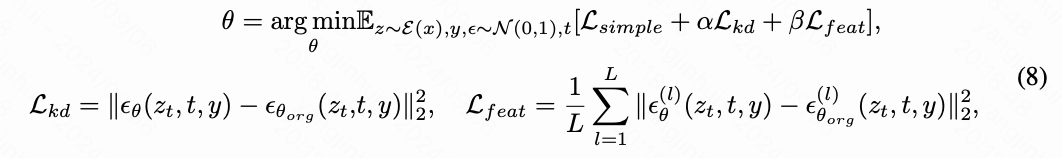
其中,和是控制各自损失项权重的超参数,表示原始SD的参数,是LinFusion/self-attention模块的数量,标记(l)表示扩散主干中第个模块的输出。
实验
实验细节
本文在下图5中展示了SD-v1.5、SD-v2.1和SD-XL的定性结果,并主要在本节中对SD-v1.5进行实验。SD-v1.5中有16个自注意力层,本文将它们替换为本文提出的LinFusion模块。命题2中提到的函数和实现为多层感知机(MLP),该MLP由一个线性分支和一个包含一个Linear-LayerNorm-LeakyReLU块的非线性分支组成。它们的结果被相加以形成和的输出。线性分支中和的参数分别初始化为和,而非线性分支的输出初始化为0。本文仅使用LAION Schuhmann等(2022)中美学评分大于6.5的169k张图像进行训练,并采用BLIP2 Li等(2023)图像描述模型重新生成文本描述。两个超参数和均设置为0.5,遵循Kim等(2023a)的方法,该方法同样关注SD的架构蒸馏。模型使用AdamW Loshchilov & Hutter(2017)进行优化,学习率为。训练在8个RTX6000Ada GPU上进行,总批量大小为96,分辨率为512 × 512,训练100k次迭代,预计需要约1天完成。效率评估在单个NVIDIA A100-SXM4-80GB GPU上进行。

主要结果
消融研究 为了验证所提出的 LinFusion 的有效性,本文报告了与替代方案的比较结果,如上图 4(a)、(b) 和 (c) 所示。本文遵循之前在文本到图像生成领域的研究惯例,并在包含 30,000 个文本提示的 COCO 基准数据集上进行定量评估。评估指标包括 FID,该指标针对 COCO2014 测试数据集,以及在 CLIP-ViT-G 特征空间中的余弦相似度。本文还报告了每张图像在 50 次去噪步骤下的运行时间以及推理过程中的 GPU 内存消耗,以进行效率比较。512 × 512 分辨率下的结果见表 2。
缓解结构差异 本文从原始的 Mamba2 结构开始探索,该结构采用双向扫描,即上图 4(a),并尝试去除门控和 RMS-Norm,即上图 4(b),以保持与原始 SD 中自注意力层的一致整体结构。这样,唯一与原始 SD 的区别在于 SSM 或用于token混合的自注意力。本文观察到这种结构对齐对性能是有益的。
归一化和非因果性 随后,本文依次应用所提出的归一化操作和非因果处理,分别对应上图 4(c) 和 (d)。尽管下表 2 中的结果表明,归一化可能会稍微影响性能,但本文将在接下来的下表 3 中展示,这对于生成在训练过程中未见过的分辨率图像是至关重要的。进一步添加所提出的非因果处理后,本文获得的结果优于上图 4(b)。
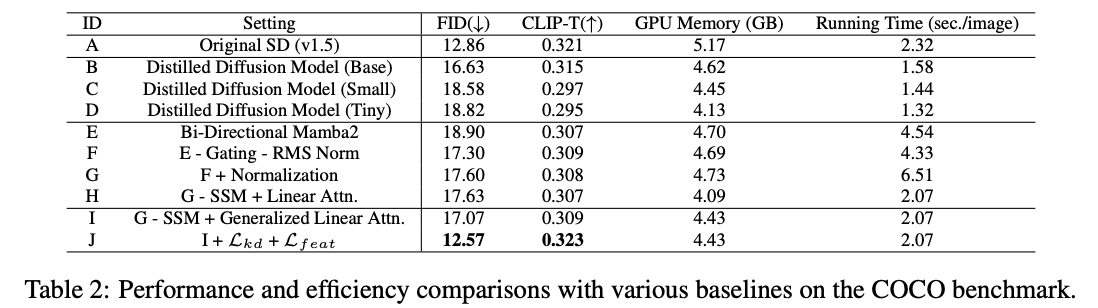

本文还比较了所提出的非因果操作与前文中提到的简化情况,该简化情况是通过直接去除施加在 上的下三角因果mask 实现的,这导致生成一个 1 阶矩阵,即不同的token共享同一组遗忘门。结果显示,性能较差证明了所提出的广义线性注意力的有效性。
注意力可视化 在下图 6 中,本文可视化了由各种方法产生的自注意力图,包括原始 SD、双向 SSM、共享遗忘门的线性注意力以及 LinFusion 中的广义线性注意力。结果表明,本文的方法在捕获更广泛的空间依赖性方面表现更佳,并且与原始 SD 的预测最为匹配。

知识蒸馏与特征匹配 最后,本文在公式 8 中应用了损失项 和 ,进一步增强了性能,甚至超过了 SD 教师模型。
跨分辨率推理 扩散模型能够生成在训练过程中未见过的分辨率图像是理想的——这是原始 SD 的一项特性。由于本文工作的 LinFusion 以外的模块是预训练并固定的,归一化是实现这一特性的关键组成部分,以保持训练和推理的一致特征分布。本文在上表 3 中报告了 1024 × 1024 分辨率的结果,表明这一结论适用于所有基本结构,如 Mamba2、去除门控和 RMS-Norm 的 Mamba2,以及所提出的广义线性注意力。下图 7 显示了一个定性示例,其中没有归一化的结果毫无意义。

超高分辨率生成 正如 Huang et al. (2024) 和 He et al. (2024) 所讨论的,直接将训练于低分辨率的扩散模型应用于高分辨率生成可能导致内容失真和重复。在本文中,本文通过先处理低分辨率来解决这一挑战,基于此生成高分辨率图像,使用 SDEdit。请注意,在本工作中,本文旨在实现一种线性复杂度的模型,从计算上支持这种超高分辨率生成,如上图 1 所示。专门的设计将留作未来的研究方向。
经验扩展
所提出的LinFusion与SD的各种组件/插件高度兼容,例如ControlNet、IP-Adapter和LoRA,无需进一步的训练或适配。本文在上图5中展示了定性结果,并建议读者参考附录以获取更多结果。以下的定量评估表明LinFusion与原始SD的性能相当。
ControlNet:ControlNet为SD引入了即插即用的组件,以增加额外的条件,如边缘、深度和语义图。本文用所提出的LinFusion替代SD,并比较FID、CLIP得分以及输入条件与从扩散模型生成的图像中提取的条件之间的相似性,结果如下表4所示。

IP-Adapter:个性化文本到图像生成是SD的一个热门应用,专注于根据输入身份和文本描述同时生成图像。IP-Adapter提供了一种零样本解决方案,训练一个从图像空间到SD条件空间的映射器,使其能够处理图像和文本条件。本文证明了在SD上训练的IP-Adapter可以直接用于LinFusion。对包含30个身份和25个文本提示以形成750个测试案例的DreamBooth数据集的性能如下表5所示。本文为每个案例使用5个随机种子,并报告平均CLIP图像相似性、DINO图像相似性和CLIP文本相似性。

LoRA:低秩适配器(LoRA)旨在对基本模型的权重应用低秩矩阵,以便能够适应不同的任务或目的。例如,Luo等(2023b)引入了LCM-LoRA,使得预训练的SD可以仅通过少量去噪步骤进行LCM推理。在这里,本文将LoRA直接应用于LCM-LoRA模型中的LinFusion。COCO基准上的性能如下表6所示。

结论
本文介绍了一种称为LinFusion的扩散骨干网络,用于文本到图像生成,其在像素数量上具有线性复杂度。LinFusion的核心是一个广义线性注意机制,其特点是具有归一化感知和非因果操作——这些是最近线性复杂度ftoken混合器(如Mamba、Mamba2和GLA)所忽视的关键方面。本文从理论上揭示了所提出的范式作为最近模型的非因果变体的一种通用低秩近似。
基于Stable Diffusion(SD),LinFusion模块在知识蒸馏后可以无缝替代原始模型中的自注意力层,确保LinFusion与现有的Stable Diffusion组件(如ControlNet、IP-Adapter和LoRA)高度兼容,无需进一步的训练工作。对SD-v1.5、SDv2.1和SD-XL的广泛实验表明,所提出的模型在性能上优于现有基线,并在计算开销显著降低的情况下,达到了与原始SD相当或更好的性能。在单个GPU上,它可以支持高达16K分辨率的图像生成。
参考文献
[1] LinFusion: 1 GPU, 1 Minute, 16K Image











![[数据集][目标检测]电动车头盔佩戴检测数据集VOC+YOLO格式4235张5类别](https://i-blog.csdnimg.cn/direct/afcfb8ac908a4fb196ce0191978570d3.png)
![[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别](https://i-blog.csdnimg.cn/direct/4a9ca83db964467783f221a1fd15ab5b.png)



