
今天的大型语言模型(LLMs)在许多用例中都取得了前所未有的成果。然而,由于基础模型的通用性,应用程序开发者通常需要定制和调整这些模型,以便专门针对其用例开展工作。
完全微调需要大量数据和计算基础设施,从而更新模型权重。此方法需要在GPU显存上托管和运行模型的多个实例,以便在单个设备上提供多个用例。
示例用例包括多语言翻译助手,用户需要同时获得多种语言的结果。这可能会给设备上的 AI 带来挑战,因为内存限制。
在设备显存上同时托管多个LLM几乎是不可能的,尤其是在考虑运行合适的延迟和吞吐量要求以与用户进行交互时另一方面,用户通常在任何给定时间运行多个应用和任务,在应用之间共享系统资源。
低秩适配(LoRA)等高效的参数微调技术可帮助开发者将自定义适配器连接到单个 LLM,以服务于多个用例。这需要尽可能减少额外的内存,同时仍可提供特定于任务的 AI 功能。该技术使开发者能够轻松扩展可在设备上服务的用例和应用程序的数量。
NVIDIA RTX AI 工具包的一部分 NVIDIA TensorRT-LLM 现已提供 Multi-LoRA 支持。这项新功能使 NVIDIA RTX AI PC 和工作站能够在推理期间处理各种用例。
LoRA 简介
LoRA 是一种热门的参数高效微调技术,可以调节少量参数。其他参数称为 LoRA 适配器,表示网络密集层中变化的低秩分解。
只有这些低级别的附加适配器是自定义的,而在此过程中,模型的剩余参数会被冻结。经过训练后,这些适配器将在推理期间通过合并到基础模型进行部署,从而在推理延迟和吞吐量方面尽可能减少,甚至不增加任何开销。
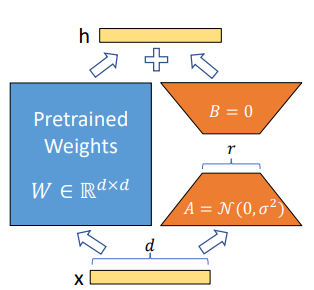
图 1. A 和 B 中的参数表示可训练的参数,以展示 LoRA 技术(来源:LoRA:大型语言模型的低阶适应)
图 1 展示了有关 LoRA 技术的更多详细信息。
- 在自定义期间,预训练模型的权重 (W) 将被冻结。
- 我们不会更新 W,而是注入两个较小的可训练矩阵(A 和 B)来学习特定于任务的信息。矩阵乘法 B*A 会形成一个与 W 具有相同维度的矩阵,因此可以将其添加到 W (= W + BA) 中。
A 和 B 矩阵的秩是 8、16 等较小的值。此秩 (r) 参数可在训练时自定义。更大的秩值使模型能够捕获与下游任务相关的更多细微差别,通过更新模型中的所有参数来接近完全监督式微调的能力。
缺点是,在内存和计算要求方面,更大的秩用于训练和推理的成本也更高。在实践中,使用小至 8 的秩值进行 LoRA 微调已经非常有效,并且是许多下游任务的良好起点。
如今,RTX AI 工具包支持量化和低排名自适应 (QLoRA) (LoRA 技术的变体),以在 RTX 系统上执行参数高效的微调。这项技术经过调整可减少内存占用。
在反向传播过程中,梯度通过冻结的 4 位量化预训练模型传递到低秩适配器。QLoRA 算法可有效节省内存,同时不会牺牲模型性能。有关 QLoRA 的更多信息,请参阅以下论文。
TensorRT-LLM 中的 Multi-LORA 支持
借助 TensorRT-LLM 中的最新更新,RTX AI 工具包现在能够在本地支持在推理时通过单个量化碱基检查点为多个 LoRA 适配器提供服务。这项新技术能够通过 INT4 量化碱基模型检查点为多个 FP16 LoRA 适配器提供服务。
混合精度部署在 Windows PC 环境中非常有用,因为它们的内存有限,必须在应用之间共享。混合精度部署可以减少模型存储和推理所需的内存,而不会影响模型质量或使用自定义模型为多个客户端提供服务的能力。
开发者可以通过多种方法在其应用中部署多个 LoRA 网卡,其中包括以下内容。
单 LoRA 网卡部署
在这个设置中,开发者选择针对每个请求激活哪个 LoRA 适配器,以便更好地提供专门内容。例如,语言学习应用程序可以在针对不同语言进行微调的适配器之间进行切换,从而根据用户当前的需求提供集中练习。
适用于单个请求的并发 LoRA 适配器(批量模式)
在此方法中,单个输入提示会生成多个不同的响应,每个响应均由不同的 LoRA 适配器在批量模式下生成。这对于多语种虚拟助理等复杂应用程序非常有用,其中一个查询可以同时生成英语、西班牙语和日语的响应,每个响应都由特定的适配器定制。
用于多个请求的并发 LoRA 适配器(批量模式)
此方法同时处理多个输入提示。每个提示都与不同的 LoRA 适配器配对,并生成多个输出提示。例如,多个 PC 应用程序向同一模型发送推理请求,并根据请求选择不同的适配器,以确保每个应用程序都收到特定于其需求的定制响应。
详细了解 TensorRT-LLM 对多个 LoRA 适配器检查点的支持。
在 RTX PC 上展示 Multi-LoRA 的强大功能
为了展示多 LoRA 支持的强大功能,我们开发了一个示例应用程序,该应用程序专为故事创建和插图而设计,只需一个提示即可完成,该过程分为两个关键步骤展开。
- 用户输入一个故事的基本思路,然后Llama 3模型完善了这个概念,扩展了最初的想法,提供了详细的基础。
- 该应用程序使用相同的 Llama 3 模型(现已通过两个不同的 LoRA 适配器进行增强),以进一步优化故事并生成相应的图像。一个 LoRA 适配器生成 Stable Diffusion 提示,用于通过本地部署的 Stable Diffusion XL 模型以直观方式说明故事。另一个经过微调,可用于编写故事,并制作结构化良好且引人入胜的叙事。
此方法可确保流程所需的空间不会显著增加,因为两个通道都使用相同的模型。第二个通道涉及文本和图像生成,使用批量推理执行,从而使流程快速高效。用户可以快速迭代不同版本的故事,轻松优化叙事和插图。
通过在此简化的两步流程中使用 multi-LoRA 支持,我们展示了如何通过单个提示最大限度地提高创意和计算效率。以下是一组输入-输出对示例。
User Prompt:Generated Story:
*The Whispering Woods*In the heart of the Whispering Woods, a legend whispered among the ancient trees spoke of a green giant, said to possess the secrets of the forest. The giant, named Eira, was rumored to be able to communicate with the trees themselves, and its presence was said to bring balance and harmony to the forest. One day, a young adventurer named Lyra stumbled upon the clearing where Eira was said to reside. As she approached the giant, she felt an eerie silence fall over the clearing, as if the trees themselves were holding their breath in anticipation. Eira's massive form loomed before her, its skin a deep, mossy green that seemed to blend seamlessly into the surrounding foliage. The giant's eyes, like ancient pools of wisdom, gazed down at Lyra with a gentle intensity.As she drew closer, Lyra noticed that the trees around her were indeed communicating with Eira, their leaves rustling softly to convey ancient secrets and whispers of the forest. The air was thick with the scent of damp earth and decaying leaves, and Lyra felt the weight of the forest's history bearing down upon her.Eira's voice, like a gentle breeze, whispered secrets to the trees, and they responded with soft murmurs and creaks. Lyra felt a sense of wonder wash over her as she realized that the giant was indeed the keeper of the forest's secrets. She reached out a trembling hand, and to her surprise, Eira's massive fingers wrapped around hers, like a gentle giant's grasp.In that moment, Lyra felt the forest's balance and harmony flow through her, and she knew that she had stumbled upon something much greater than a mere legend. As she stood there, surrounded by the ancient trees and the whispers of the forest, Lyra felt a sense of belonging wash over her, as if she had finally found her true home.
图 2. 提示中生成的角色 Eira 图像。
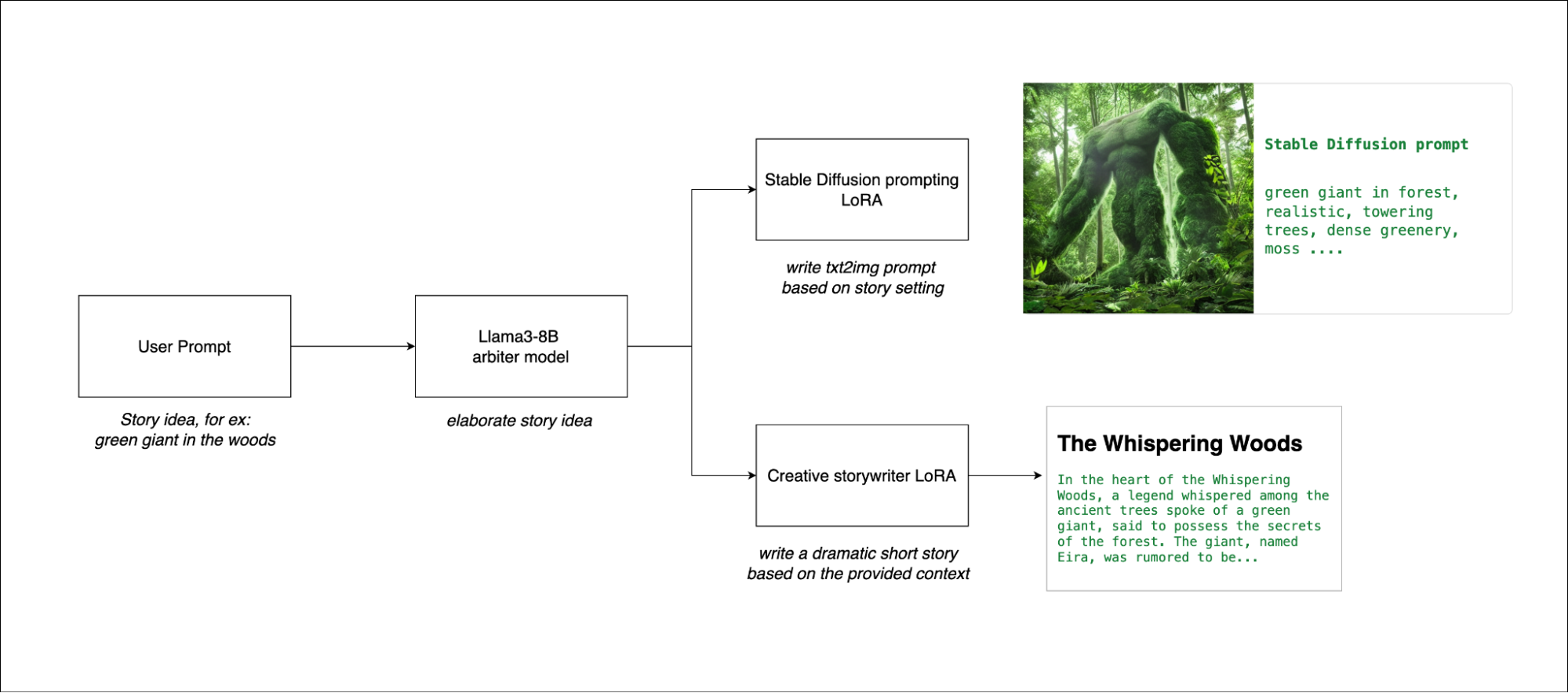
图 3. 使用 Llama3-8B 和 LoRA 的稳定扩散图像。
使用 TensorRT-LLM 在 Windows PC 上加速多 LoRA 用例
下图显示了 NVIDIA 内部测量结果,其中展示了使用 Llama-3-8B 模型的 NVIDIA GeForce RTX 4090 的吞吐量性能,以及使用 TensorRT-LLM 的基础模型和不同批量大小的多个 LoRA 适配器。
结果显示,在输入序列长度为 43、输出序列长度为 100 个令牌时的吞吐量。当批量大小大于 1 时,每个样本都使用唯一的 LoRA 适配器,最大引擎排名为 64。
吞吐量越高,我们发现当运行多个 LoRA 网卡时,性能会降低 3%。
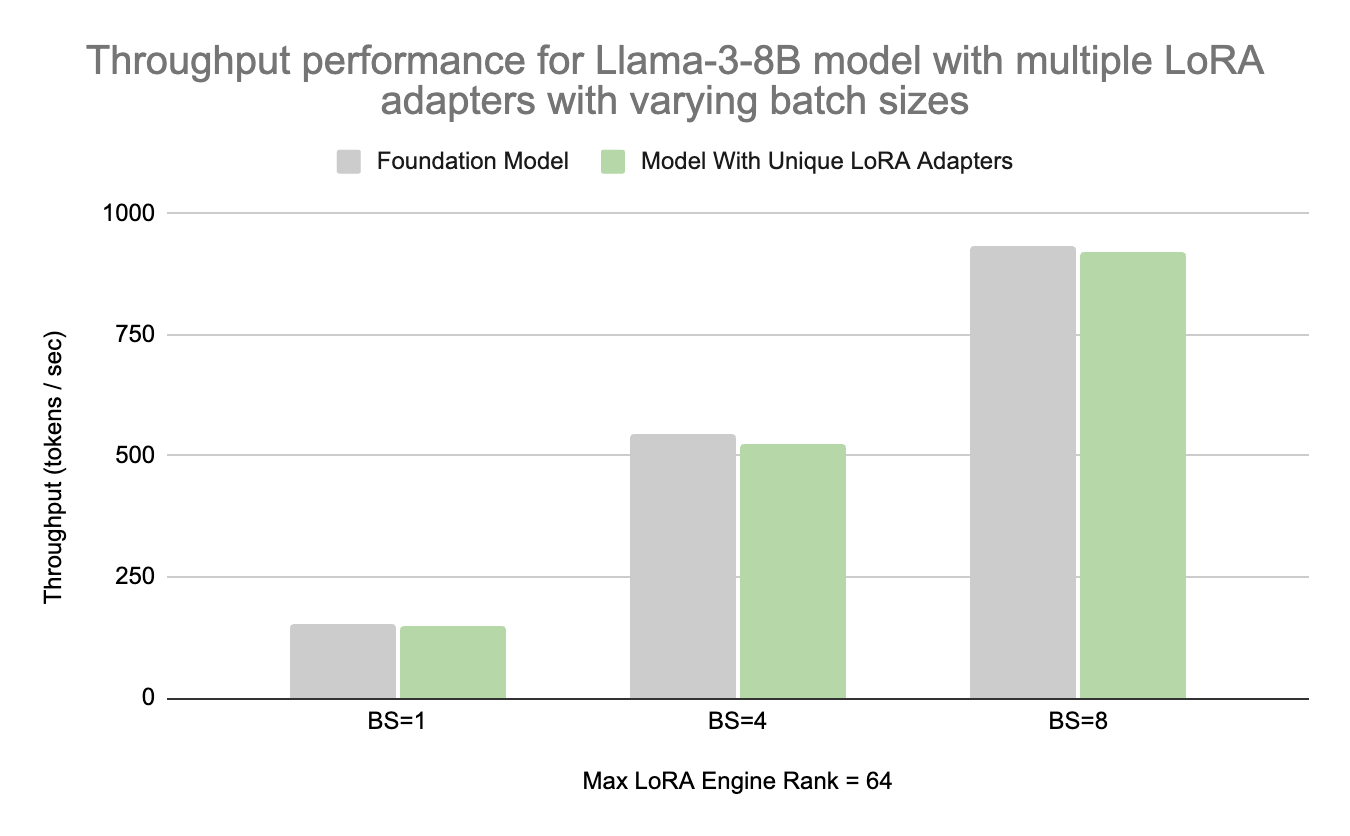
图 4. NVIDIA 内部吞吐量性能测量结果在 RTX 4090 PC 上
图 5 显示了在 RTX 4090 PC 上使用 Llama-3-8B 模型以及使用 TensorRT-LLM 0.11 的预训练基础模型和不同批量大小的多个 LoRA 适配器测量的 NVIDIA 延迟性能。
结果展示了输入序列长度为 43、输出序列长度为 100 个令牌时的延迟。在批量大小大于 1 时,每个样本使用唯一的 LoRA 适配器,最大引擎 rank 为 64。更低的延迟更好,我们看到运行多个 LoRA 适配器时性能降低了约 3%。

图 5. NVIDIA 延迟性能测量结果在 RTX 4090 PC 上
图 4 和图 5 显示,在推理时使用多个 LoRA 适配器时,TensorRT-LLM 0.11 可提供出色的性能,同时尽可能减少不同批量大小的吞吐量和延迟降低。与运行基础模型相比,在使用多个独特的 LoRA 适配器和 TensorRT-LLM 0.11 时,我们发现不同批量大小的吞吐量和延迟性能平均降低了 3%。
后续步骤
借助最新更新,开发者可以在设备上使用 LoRA 技术自定义模型,并在 NVIDIA RTX AI PC 和工作站上使用多 LoRA 支持部署模型,以服务于多个用例。
开始在 TensorRT-LLM 上用 multi-LoRA。



















