扩散磁共振成像和结构连接组学指南
- 引言
- 流程概述
- 扩散磁共振成像(dMRI)
- dMRI基础
- ADC( apparent diffusion coefficient, 表观扩散系数)
- MD(mean diffusivity, 平均扩散率)
- FA( fractional anisotropy, 分数各向异性)
- 不同的dMRI方法
- 非参数方法:DKI
- 参数方法:生物物理模型
- 结构连接组学
- 纤维束追踪的不同方法
- 纤维束追踪的高级技术
- 纤维束追踪标准
- 纤维图评估
- 纤维束追踪的错误和局限性
- 结构网络
- 网络构建
- 网络分析
- 网络可视化
- 结论
- 参考文献
扩散磁共振成像(dMRI)是一种多功能成像技术,因其能够敏感地测量活体组织中水分子在微米尺度上的位移而广受欢迎。尽管dMRI自20世纪90年代初就已存在,但其应用仍在不断发展,主要涉及从神经纤维轨迹推断结构连接组学。然而,这些应用需要图像处理和统计学方面的专业知识,对新手而言,选择适合其研究需求的处理流程可能会有困难,尤其是因为dMRI是一种非常灵活的方法,多年来已经开发出数十种采集和分析流程。本入门指南专为神经科学领域的研究生和研究人员设计,旨在帮助那些对整合这种新方法感兴趣的人,无论他们在神经影像学和计算工具方面的背景如何。指南简要概述了基本的dMRI方法,但重点关注其在神经可塑性和连接组学中的应用。指南首先介绍dMRI实验设计和结构连接组学的完整步骤流程。接下来的部分涵盖了dMRI的基础知识,包括参数和临床应用(表观扩散系数、平均扩散率、各向异性分数和微观各向异性分数),以及不同的方法和模型。最后一部分聚焦于结构连接组学,涵盖了从纤维追踪(技术、评估和局限性)到结构网络(构建、分析和可视化网络)的主题。
引言
连接组是形成人脑的网络连接和元素的综合结构连接图。连接组的重要性在于揭示大脑的结构连接模式,并理解由此产生的功能状态。过去十年里,已经启动了几个大型项目,旨在解开大脑的连接组,包括人类连接组计划(HCP)、蓝脑计划、人脑计划(欧盟)等。最大的人脑磁共振成像(MRI)数据库UK Biobank,甚至在其MRI流程中包含了各种结构和功能连接度量。HCP在绘制人脑宏观尺度布线图的努力中处于领先地位,包括皮质区域之间的长距离连接(20-200毫米),精度达到1立方毫米。
纤维追踪或称纤维束成像(tractography),是用来描述从局部神经纤维方向推断结构连接性的方法。这些方向可以通过扩散MRI(dMRI)实验计算得出(或使用更传统的方法,如顺行和逆行示踪)。在追踪术语中,"tract"指的是被建模的生物对象,可以是神经束、轴突或纤维,而"track"指的是模型中的虚拟对象,也称为流线。大脑纤维束的最终模型,也称为纤维束图,包括整个大脑中所有三维(3D)白质(WM)流线。纤维束图通常按方向着色。
连接性研究的主要挑战之一是准确表示纤维追踪结果,以便在受试者内部和跨受试者之间进行量化和比较。在过去的十年里,复杂网络分析的图论工具已成为脑连接分析的最先进方法。
流程概述
不同的弥散磁共振成像 (dMRI) 实验使用不同的成像参数集,具体取决于其实验设计的目的。所有实验设计的共同点是需要通过最小化回波时间来减少伪影和信号损失,并优化重复时间以实现合理的信噪比 (SNR)、实验时间和大脑覆盖范围。其他不同的参数包括脉冲序列、梯度和图像相关的参数。例如,设计一个测量平均扩散率 (MD) 的实验可能需要比设计用于纤维束成像的实验更少的梯度方向。表 1 总结了针对各种高级目的的不同 dMRI 实验设计。
表1 针对不同高级目的的dMRI实验设计
| 目的 | 实验设计重点 | 参考文献 |
|---|---|---|
| MD/FA临床研究 | 过去认为 6 个梯度方向足以进行 DT MRI,但研究表明,稳健估计 FA 需要 >20 个梯度方向,而 MD 和张量方向需要 >30 个梯度方向。 通常,b = 1,000 s/mm²,但 700-1,200 s/mm² 范围内的 b 值也是合适的。 | 107 |
| 神经可塑性 | 检查神经可塑性时,精确配准至关重要。MRI 数据集必须在空间上精确对齐,以避免结构特征的丢失。为了准确探索和解释神经可塑性的变化,必须将所选的大脑图谱转换到个体受试者大脑的空间,同时保持 MRI 数据集不变。 | 29,30 |
| 微观结构探索 | 研究表明,使用适用于高磁场的先进技术,可以在 7T 下生成高质量的 dMRI。所得图像具有高达 800 μm 的各向同性分辨率,适用于探索纤维结构的微观结构特性。类似的研究也可以在 3T 下进行,但需要更长的采集时间。 | 64 |
| 轴突直径 | 为了在整个大脑中获得可靠的轴突直径信息,需要高梯度强度。不同的技术,包括 AxCaliber、COMMIT 和 ActiveAx,都需要应用高梯度和超高梯度,Gmax = 1,200 mT/m 或更高。 | 50,53,62,63 |
| 灰质 (GM) | 虽然 MD 和 FA 在皮质层之间几乎没有变化,但 fODF 能够描绘皮质层。图像分辨率是根据对齐的纤维束方向进行层描绘的关键。 | 66 |
| 功能性弥散 | 快速采集是弥散加权功能性 MRI 的关键,它使用高度敏感的弥散成像来探索先于使用功能性 MRI 探索的血流动力学反应函数的弥散反应函数。 | 108-111 |
| 纤维追踪 | 研究建议使用 b = 3,000 s/mm² 的 HARDI(取决于信噪比)以提供最高的角分辨率。但是,1,000-3,000 s/mm² 范围内的更实际的 b 值也是合适的。研究还建议采集 >45 个梯度方向,以帮助避免梯度均匀性缺陷并满足信噪比要求。 | 27,65 |
| 连接组学 | 为了准确绘制皮质区域之间的连接,纤维束成像中的解剖学停止标准必须允许流线进入皮质灰质。此外,皮质分区的选择决定了所得大脑网络的细节水平。 | 7 |
HCP的扫描协议适用于大多数dMRI应用。尽管对于平均扩散率(MD)等应用来说,HCP的扫描可能被认为是过度的,但它们特别适用于结构连接组学。研究用MRI扫描仪通常比临床扫描仪有更强的梯度系统,这导致更好的扩散加权,因此更适合连接组学的目的。3T和7T MRI扫描仪的扫描协议可在https://www.humanconnectome.org/hcp-protocols 获取。
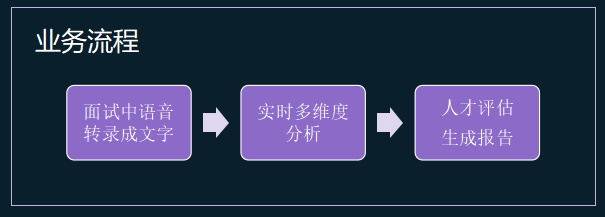
一般来说,用于研究的结构连接组学流程包括以下主要步骤:
-
选择dMRI方法(根据研究问题)
-
进行dMRI实验(MRI扫描协议)
-
计算纤维方向(使用扩散张量成像(DTI)或非DTI方法)
-
计算纤维束图(包括整个大脑的纤维束)
-
将纤维束图映射到脑图谱上(皮质分区)
-
构建结构连接网络(连接组)
BOX1包含了遵循处理流程的步骤程序(图1)。
值得注意的是,HCP提供了详细的扫描协议,这对于保证不同研究之间的数据可比性非常重要。研究人员可以根据自己的具体需求和设备情况,选择合适的扫描参数。同时,这个流程概述也为研究者提供了一个清晰的框架,从数据采集到最终的连接组构建,每一步都是结构连接组学研究中的关键环节。

图1:执行结构连接组学的处理流程。步骤1-13在方框1中有详细描述。
这些步骤中的许多都是需要使用适当软件执行的计算过程。我们使用ExploreDTI(https://www.exploredti.com/)在MATLAB中从原始dMRI数据中提取结构连接组。虽然ExploreDTI是一个成熟的工具箱,但还有许多其他管道可以使用各种软件程序提取结构连接组,包括例如MRtrix、Tractoflow、QSIPrep和Micapipe。所有管道都从为连接组学设计的dMRI扫描中提取的原始数据开始,最终得到代表结构连接组的连接矩阵。
下一节描述了dMRI的基础知识,然后聚焦于用于结构连接组学的dMRI。它涵盖了重要概念,如表观扩散系数、平均扩散率、功能各向异性和微观功能各向异性,以及不同的dMRI方法(非参数方法和基于模型的参数方法)。
关于结构连接组学的部分首先介绍了纤维追踪(方法、高级技术、标准、评估以及错误和局限性),然后描述了结构网络(构建、分析和可视化结构网络)。
BOX1 执行结构连接组学的处理流程结构连接组学的处理流程如图1所示,详细步骤如下:
- 进行为结构连接组学设计的扩散MRI扫描。 HCP风格的扫描方案适用于扩散MRI的结构连接组学应用。3T和7T MRI扫描仪的详细扫描方案可在https://www.humanconnectome.org/hcp-protocols获取。 另一个详细的示例方案可以在最近的一项结构连接组学研究中找到,使用标准DWI序列,参数如下:Δ/δ = 60/15.5 ms, bmax = 5,000 (0, 250, 1,000, 3,000 和 5,000) s/mm2,87个梯度方向,FOV 204 mm, maxG = 7.2, TR = 5,200 ms, TE = 118 ms, 1.5 × 1.5 × 1.5 mm3, 128 × 128 × 94 体素。每个受试者在3T Magnetom Siemens Prisma (Siemens)扫描仪上进行扫描,配备64通道RF线圈,梯度强度最高可达80 mT/m,200 m/T/s。 开始分析之前,请注意DWI图像和皮质图谱必须在空间上对齐,最好是在标准化的大脑空间中,如MNI空间(以蒙特利尔神经学研究所命名)。这一步可以使用SPM12 (https://www.fil.ion.ucl.ac.uk/spm/software/spm12/)或任何其他图像配准软件高效完成。
- 扩散MRI扫描的原始数据以DICOM(医学数字成像和通信)图像形式出现。使用dcm2nii (https://www.nitrc.org/projects/dcm2nii/)将DICOM转换为3D图像。
- DICOM转换会产生一个3D NIfTI(神经影像信息学技术计划)图像以及表示b值和b向量的两个文件。 使用转换插件将b-val和b-vec文件转换为b矩阵文本文件。如有需要,使用排序或随机插件重新排列b矩阵,使零值移到开头。 接下来的步骤使用ExploreDTI完成。
- 使用随机化的NIfTI和b矩阵文件,通过原始数据转换插件计算DTI MATLAB文件。根据数据选择参数:图像大小、体素大小等。
- 加载转换后的DTI文件。图像视图根据方向性进行颜色编码。
- 检查已知元素的梯度方向是否准确。为此,加载轴和绘图工具,并在选定的感兴趣区域(如胼胝体)绘制张量。如果准确,由于左右纤维方向,胼胝体应呈现红色。
- 为了提高信噪比,使用适当的插件通过校正受试者运动和其他失真来对图像进行去噪。图像应该看起来明显更清晰,特别是在大脑外部区域。
- 使用正确的DTI文件和适当的插件,计算全脑纤维束追踪。计算需要根据图像数据和用户需求选择拟合参数,例如使用DTI默认值或CSD。此过程可能需要几分钟才能完成。
- 通过加载包含纤维束的结果MATLAB文件来查看生成的纤维束。
- 以通过在3D中旋转坐标轴来查看和进一步评估全脑纤维束图。
- 选择适当的图谱(分区)用于从纤维束图构建网络。
- 使用网络分析工具插件在所选图谱中构建纤维束连接矩阵。
- 生成的连接矩阵代表结构连接组,可以使用Brain Connectivity工具箱或任何其他网络分析和可视化软件对其进行各种网络特征分析。
扩散磁共振成像(dMRI)
扩散磁共振成像(dMRI)是一种在获取程序和分析流程方面都非常灵活的MRI技术,在过去二十年里不仅在放射学领域,而且在神经科学领域也获得了广泛应用。dMRI为活体组织动力学研究打开了一扇窗户,成为了一种可以测量包括组织密度和有序性在内的多种性质变化的微观结构成像探针。
**dMRI已被用于探索白质(WM)和灰质(GM)的结构和微观特性。**通过各种实验和方法,研究人员在大脑结构-功能关系方面取得了诸多发现。这些发现包括多个认知领域的快速变化、使用先进dMRI技术研究灰质亚结构,以及多项关于结构连接组学机遇和挑战的研究。由于其增强的对比度,dMRI在放射学和神经病学临床应用中包含了宝贵的信息。
dMRI脉冲序列称为脉冲梯度自旋回波(PGSEE),它由普通自旋回波序列加上两个磁梯度脉冲组成。第一个梯度脉冲出现在90°射频(RF)脉冲之后。对于第二个梯度脉冲,磁化方向被反转;它出现在180°RF脉冲之后(见框2)。dMRI实验由多个参数定义,包括与脉冲序列相关的参数,特别是与所应用的梯度相关的参数,以及与图像采集相关的参数。表2总结了dMRI实验的主要参数。
表2 dMRI实验参数

dMRI测量的最基本和最可靠的参数之一是表观扩散系数或平均扩散率(关于使用dMRI测量扩散系数的更多信息,请参见框2)。
dMRI已成为一种流行的体内成像技术,这要归功于它能够高度敏感地测量水分子的位移,这些水分子在实验过程中通常移动几微米。dMRI不仅对水分子位移的大小敏感,而且对这种位移的方向性也敏感(更多相关内容,请参见框3)。在最简单的情况下,这种图像显示了每个体素中水分子位移的程度。**dMRI的输出图像被称为扩散加权图像(DWI),它代表了测量到的水分子位移。**水分子的测量扩散率与获得的DWI信号之间存在反比关系。水分子的短位移范围和低扩散率会产生强DWI信号,而长位移范围和高扩散率会产生弱DWI信号。例如,由于水分子在脑脊液(CSF)中的扩散率高于大脑白质(WM),在结果图像中,CSF的DWI信号强度会比WM低(图2a)。由于其增强的对比度,dMRI在放射学和神经病学的多个临床应用中包含了宝贵的信息。

图2: DWI和MD. b值为995 s/mm2的DWI图像(a)和MD(平均扩散率)图像(b)包括大脑中各种纤维群的MD值分布©。这两种类型的图像都从不同的视角展示:冠状面(左列)、矢状面(中列)和轴状面(右列)。
Box 2 测量扩散系数 水分子在不同脑组织中的移动性各不相同,这取决于组织微环境允许的自由运动程度。神经元微环境包括细胞内(胞内)和细胞外(胞外)空间,或者更具体地说,与轴突相关的轴突内和轴突外空间。水在这些空间中的自由运动极大地受到组织生物微结构的影响,包括组织密度和纤维组织的水平。 为了简化PGSE(脉冲梯度自旋回波)实验中表示信号衰减的方程,假设测量区域内的水扩散呈正态高斯分布。 信号衰减与PGSE参数之和的关系可以用一个称为b值的通用指数来表示,这就是Stejskal–Tanner方程:
E ( q ) = e − b D E(q)=e^{-b D} E(q)=e−bD
其中, b = q 2 D ( Δ − δ 3 ) b=q^2 D\left(\Delta-\frac{\delta}{3}\right) b=q2D(Δ−3δ) and q = y δ G ( 2 ) q=y \delta G(2) q=yδG(2), (3) Y Y Y 是水分子磁矩与角动量的旋磁比。Δ是扩散时间,即两个梯度施加之间的时间;δ是扩散梯度持续时间;G (或 g) 是扩散梯度幅度和方向;D是扩散系数,可以是标量或张量形式。 下图显示了PGSE序列,包括由180°脉冲分隔的两个90°梯度脉冲(a),每个脉冲后施加的额外梯度(b)和获得的信号©,包括90°脉冲后的短暂响应,称为自由感应衰减(FID),以及信号回波。在图中,δ、G和Δ如上定义;FID是自由感应衰减,TE是回波时间,TR是重复时间(改编自参考文献13)。

dMRI图像获取 "b值"这个术语源自Le Bihan,是根据选择的梯度及其时间(G和δ)计算的因子。b值决定了信号对分子运动的敏感性和由此产生的信号衰减强度。使用更大的梯度幅度(G)、更长的梯度持续时间(δ)或更长的脉冲间隔(d或Δ)可以达到更高的b值,从而产生更强的衰减。b值的典型范围是0-5,000 s/mm2,更常用的值是高达1,000 s/mm2。 没有单一的最佳b值;可以通过实验优化这个参数,以在最小化信号衰减的同时平衡敏感性和特异性。一个有用的经验法则是b值与表观扩散系数(见"参数和临床应用")的乘积应该大约等于1。 下面可以看到各种结果图像,包括比较同一轴向切片上三个不同梯度方向的图像,以及比较单一梯度方向(下-上)下几个不同b值的图像(右侧)(a),包括5 s/mm2 (b)、1,000 s/mm2 ©、2,000 s/mm2 (d)和4,000 s/mm2 (e)。从不同视角看到的图像:冠状面(左列)、矢状面(中列)和轴状面(右列)。

BOX3 DTI(扩散张量成像) **dMRI 信号不仅取决于所施加梯度的幅度,还取决于施加梯度的方向。**产生的梯度可以应用于任何方向,从而导致对沿特定方向发生的扩散过程的敏感性。具有高表观扩散各向异性或高运动方向性的区域(如神经纤维)会根据施加梯度的方向显示出不同的信号衰减。DTI 是一种在 20 世纪 90 年代初开发的模型,它概括了 dMRI 并量化和可视化了这种现象 。它的发展源于这样一个发现:在不同方向上施加的梯度会导致不同的图像对比度,这表明水分子的位移不一定是方向均匀或各向同性的。 DTI 以旋转不变的方式将单个扩散值扩展到 DT(扩散张量) 的完全量化。
下图显示了张量颜色,其中 (a) 是根据扩散方向进行的张量颜色编码。DTI 中扩散的完整方向性由称为 DT (扩散张量) 的矩阵表示。DT (扩散张量) 的特征向量表示扩散率的方向,其特征值表示相应方向上的扩散值。DT 通常用椭球体直观地表示,**它由三个垂直向量组成,包括扩散主方向上的主轴和两个次轴。沿椭球体主方向的扩散率称为轴向扩散率,垂直于主方向的扩散率称为径向扩散率。**下图显示了张量形状,其中 (b) 扩散方向性程度,范围从高方向性(也称为各向异性,张量形状更椭圆)到低方向性(也称为各向同性,张量形状更圆),以及 (c,d) 轴向 (D||) 和径向 (D⊥) 扩散率的主要张量方向。

DT (扩散张量) 椭球形状和颜色 一张图像显示了彩色张量场 (a) 的冠状视图,显示在胼胝体 (b) 上。

dMRI基础
几个可提取的dMRI参数已经显示出对组织微结构动态的敏感性,提供了各种神经影像学应用。主要的可提取参数描述如下。
ADC( apparent diffusion coefficient, 表观扩散系数)
表观扩散系数(ADC)代表了水分子在施加梯度方向上计算得出的扩散系数。在最基本的形式中,ADC是从三个垂直DWI采集的对数平均中提取的。
水分子的测量扩散率与计算出的ADC值之间存在直接关系。在ADC图像中,强信号代表长位移范围和高扩散系数,而低信号代表短位移和低扩散系数。ADC值在不同组织之间差异很大,**这取决于它们的组织微环境:**CSF(脑脊液)的ADC值高于大脑灰质(GM),因为CSF是一种具有较少限制性细胞外结构的流体。**灰质的ADC值又高于白质(WM),因为白质由于其髓鞘化轴突纤维含量和高组织密度,相比灰质中的神经元细胞体和树突,具有更具限制性的细胞外结构。**典型值范围如下:白质,0.6–1.05(10^-3 mm2/s);灰质,1.05–2.4(10-3 mm2/s);和CSF,2.4–4.4(10-3 mm^2/s)(图3a)。

图3:ADC和FA
单一方向的ADC图像(a),和FA图像(b),包括大脑中各种纤维群的FA值分布(c)。这两种类型的图像都从不同的视角展示:冠状面(左列)、矢状面(中列)和轴状面(右列)。
dMRI的首批临床应用之一是使用ADC图像早期检测脑缺血和中风。受影响组织的ADC值往往会降低,这是由于涉及细胞肿胀的一系列事件造成的。尽管ADC是一个难以量化和解释的参数,但dMRI的这一临床应用为疑似中风患者的诊断成像打开了大门,并验证了其作为微结构探针的使用。
由于ADC是一个难以量化和解释的参数,而且可以从DTI中提取更有用和适用的参数,所以现在很少使用它。一些更适用的参数包括MD(平均扩散率)和FA(分数各向异性)(下面将讨论)。
MD(mean diffusivity, 平均扩散率)
MD代表水分子在三个垂直运动方向上的平均表观扩散系数。MD在概念上与ADC相似,但它是从扩散张量(DT)计算得出的,而不是从DW图像计算的(框3)。因此,MD表现出旋转不变性,并为估计扩散系数提供了更准确的测量,特别是在高各向异性区域。换句话说,**DTI为评估平均扩散值提供了更稳健的基础。**MD在白质中表现出约0.7-0.8(10^-3 mm2/s)的特征值,在灰质中的值>0.8(10-3 mm^2/s)。
MD被认为是探索神经组织长期结构重塑(也称为神经可塑性)的优秀参数。神经可塑性涉及一系列认知和生理过程,其特征是特定任务相关区域神经元之间突触活动的加强和减弱。相关区域重塑后,MD值会发生变化。例如,**空间学习会导致海马体部分区域的突触活动增加。**研究表明,这种突触活动与胶质细胞形态重塑和肿胀共定位,这是伴随突触可塑性的常见过程。这种肿胀导致MD轻微减少1-5%,**这被归因于细胞密度的增加,从而导致水的运动受到限制。**这种现象不仅高度敏感和特异,而且在广泛的时间尺度上持续存在,从任务后的几分钟到几天和几周。
关于MD变化的时间过程、这些变化背后的机制以及短期和长期神经可塑性机制之间的差异,仍有许多问题有待解答。尽管存在这些未解决的问题,**多项研究已经揭示了在执行不同认知领域的认知任务后几分钟内MD值的区域性变化。**这些变化涉及在执行诸如物体识别、空间导航、运动序列学习和新词汇学习等任务后,多个脑区的MD值降低。不同的神经系统疾病也表现出MD的变化,包括中风、阿尔茨海默病和癫痫等病理状况(有关MD的更多信息,请参见补充说明)。这些研究突出了MD探索结构性神经可塑性的前所未有的能力,以及其作为微结构探针检查学习和认知效应的潜力。虽然MD是旋转不变的,但其他dMRI参数直接与其方向性相关(下面将讨论)。
FA( fractional anisotropy, 分数各向异性)
FA表示水分子向单一方向扩散的方向性程度或倾向。高各向异性由于轴向扩散率高于径向扩散率,表现为更椭圆和定向的扩散张量(DT)(如框1所示)。**FA值是无量纲的,范围在0到1之间,其中0代表完全各向同性或方向均匀性,1代表完全各向异性或方向性。**例如,脑脊液(CSF)表现出低FA值,因为其微环境中的水分子可以自由地向所有方向均等移动。相比之下,**白质(WM)表现出较高的FA值,因为其微环境中的水分子沿轴突纤维方向移动更自由,而垂直方向的移动则更受限制。**FA在灰质(GM)中的特征值约为0.1-0.2,在白质中的值>0.3。这些值,也称为特征值,但并不提供主要方向的任何信息。方向信息存在于特征向量中。在DTI建模后,FA图通常根据DTI颜色编码进行可视化,以一种为每个方向分配颜色的方式:左-右:红色;前-后:绿色;下-上:蓝色(图3b,c)。
FA提供了一种定量测量,推进了对健康白质神经解剖学、其发展以及由于老化和各种退行性临床状况导致的退化的探索。**FA在DTI早期特别流行,但由于在异质纤维方向和组织区域(如交叉纤维)中存在固有的伪影,以及解释困难,其使用已经变得有限。**FA对细胞结构各向异性的敏感性受到其对方向离散度敏感性的限制,这是由于在单个体素内多个纤维方向的平均。近年来,其他模型已经克服了这些问题,成为提取类似FA信息的一线分析方法(下面将讨论)。
为了克服FA计算中的固有缺陷,开发了一种替代的采集和分析流程,**引入了微观FA(microFA)。**MicroFA克服了限制FA对复杂组织组织(如白质纤维离散)敏感性的部分体积效应(PVE)(下面将讨论)。MicroFA的计算涉及对微观结构特征的额外考虑,如体素内结构的形状和方向,这是通过试图捕捉更细微细节的高级建模技术实现的。
MicroFA使用PGSE的修改版本,通过粉末平均(powder averaging)来独立于方向离散度量化扩散各向异性,这涉及计算球体中均匀分布方向的平均dMRI信号。**在交叉纤维区域和大纤维束之间的交叉处,FA和microFA之间的显著差异很明显,**这里FA较低而microFA较高。MicroFA还展示了区分脑肿瘤类型(例如,脑膜瘤和胶质母细胞瘤)的临床应用。脑膜瘤中FA和microFA的差异表明,这种肿瘤包含无序的各向异性结构,进一步确立了microFA作为FA补充工具的作用。
不同的dMRI方法
尽管dMRI很受欢迎,但显然需要重新审视分析的某些方面,因为它们以非最优方式模拟组织。最基本的概念性陷阱涉及该方法的名称。dMRI并不直接测量水分子的扩散,而是测量它们的位移。只有在特殊的物理条件下,位移才能与扩散联系起来。
dMRI由Stejskal和Tanner开发,**假设水分子的位移是布朗运动,且值呈高斯分布。**然而,生物组织中水分子的位移常常受到膜和其他细胞结构的限制,因此并不总是遵循这一假设。**这种现象已经通过实验得到证实:**通过ADC测量的大脑中水的运动被发现依赖于扩散梯度的探测时间。如果水的运动呈高斯分布,就不应该有这种依赖性。换句话说,ADC值在较高的b值下趋于平稳,遵循较低b值下信号的线性部分,这对应于高斯行为。**偏离高斯扩散表明dMRI的建模基础并未完全捕捉大脑中水运动的复杂性,因此需要进一步发展。**此外,dMRI中的值在每个体素内平均,产生了一种称为部分体积效应(PVE)的脑组织体积平均效应。因此,图像分辨率仍然限制了微结构探针在DTI等技术中研究脑组织的能力(表2)。
为克服dMRI的概念和方法限制,已开发了多种方法和解决方案。**一种优雅的无模型方法使用q空间,**通过对扩散信号衰减进行快速傅里叶变换,表示倒易空间域而不是空间频率域(也称为k空间)。虽然q空间的使用优雅且理论上直接,但它需要复杂的实验条件,如强梯度系统,这在临床MRI扫描仪中通常无法满足,只能在研究用途的扫描仪中实现。
多年来,科学界一直在努力开发合适的非DTI方法。**这些方法基于非参数(无模型)方法或参数方法,包括用于估计轴突密度和直径的生物物理模型。**每种方法都需要一套不同的假设和方法,以及不同的扫描参数组合,如b值和梯度方向。
非参数方法:DKI
一种主要的非参数方法是扩散峰度成像(DKI),它的开发是为了克服高斯位移假设,**更好地描述体内细胞内和细胞外环境的复杂实际情况。**这种非高斯扩散的异质性行为在更高的b值或更强的梯度和更长的回波时间下变得更加明显。为了处理这些偏差,**DKI使用一种称为峰度(K)的统计量来测量偏离高斯分布的程度,**或分布的"尾部"。当K=0时,不存在偏差,分布被认为是高斯的。负峰度(K<0)表示分布比高斯分布更"胖"且不太"尖锐",正峰度(K>0)表示分布更"瘦"且更"尖锐"。峰度通常在多个方向上测量,得到一个具有多个分量的四阶张量,这些分量被平均成一个旋转不变的替代值,称为平均K。**大多数生物组织的特征更好地由(K>0)描述,因为其中的水分子由于位移能力的限制而经历有限的运动。**使用DKI的研究表明,它作为一种独立和互补的dMRI技术的贡献,揭示了改进的白质特征描述,以及在评估病理学、疾病进展和治疗反应方面的敏感性和特异性提高。
参数方法:生物物理模型
生物物理模型利用扩散率偏离高斯行为的特点,**使用多个b值来模拟各种组织成分。**这些模型需要一系列关于组织几何结构、扫描参数和扫描期间水分子预期位移的假设和近似。这些假设和近似允许对信号衰减进行数学简化。在这种方法中,组织被假定由几个不同的生物物理成分组成,它们之间可能有或没有相互作用(交换)。例如,灰质组织可以被建模为一组球体(代表细胞)和无组织的圆柱体(代表神经突起)。此外,细胞外空间可以在第一近似下用高斯扩散建模。在白质中,可以添加其他因素,因为神经突起(轴突)是密集排列的,引入了其他参数,如堆积密度和直径分布。
关于轴突密度估计,神经组织可以根据水分子扩散水平的不同,被建模为不同成分的组合:
**第一个成分表现为受限扩散,****它模拟了白质中髓鞘化神经细胞的有限渗透性。**受限扩散是水分子扩散高斯性质受扰的主要原因,因此表现出非高斯扩散特性。
**第二个成分表现为受阻扩散,****它模拟了灰质更接近高斯的扩散特性,**这是由于未髓鞘化神经细胞体的扩散特性受限较少。受阻扩散可以用经典的DTI公式数学表达,因为它具有类高斯扩散特性。
**第三个成分表现为各向同性扩散,**它模拟了纤维群体外脑脊液中的自由水分子。
第四个成分,或者说是建模考虑因素,是分支、重叠和交叉纤维群体的存在。
各种多参数生物物理模型使用这些成分,试图以不同的细节和简化水平捕捉轴突密度。从数学角度来看,在建模或拟合过程中引入许多参数可能导致过拟合,因为测量的数据样本数量是有限的。因此,不建议试图同时全面捕捉和模拟所有组织隔室。相反,任何建议的模型都需要专注于它希望模拟的特定组织隔室。
-
复合受阻和受限扩散模型(CHARMED)将dMRI信号建模为受阻和受限扩散成分的信号衰减的线性组合,乘以它们相应的体积分数。
-
神经突方向离散度和密度成像(NODDI)**使用三个成分(包括细胞内、细胞外和脑脊液)来模拟轴突和树突的结构和方向,**并利用数学简化,如方向离散圆柱假设。
-
扩散隔室成像中的各向异性微结构环境分布(DIAMOND)使用三个成分(包括受限、受阻和各向同性扩散)在一个既生物物理又统计的混合模型中模拟dMRI信号。
关于轴突直径估计,在某些实验条件下,dMRI也显示出对轴突直径的敏感性。虽然精确和绝对的轴突直径估计可能无法实现,但一些模型提供了使用dMRI的直径信息的稳健代理。**AxCaliber是第一个开发用于估计轴突直径分布的生物物理模型,**随后是ActiveAx、AxCaliber3D、ActiveAxADD、用于微结构信息化纤维追踪的凸优化建模(COMMIT)、AMICO、轴突谱成像(AxSI)等。
**AxCaliber是CHARMED的扩展,**将组织学中的轴突直径作为模型中的额外因素。AxCaliber使用伽马分布函数来拟合轴突直径分布,而不是预定义的分布。使用伽马函数增加了模型复杂性,引入了需要额外优化方法的附加评估参数。最初,AxCaliber以简化的方式实现,要求采集测量垂直于纤维方向的扩散。这种简化导致对小轴突的敏感性降低,以及分离受阻和受限成分的能力有限。该方法后来扩展到3D,称为AxSI,增加了其在连接组学中的适用性。AxSI可以估计所有纤维系统的轴突直径,并能够在体内探索大脑中的信息传递机制(图4a)。其他方法,包括COMMIT和ActiveAx,引入了离散度以提高估计轴突直径分布的准确性。

图4:轴突直径和纤维束追踪
**a, 轴突直径(AxCaliber)图像,**展示了白质中相对测量的轴突直径值,从不同视角呈现:冠状面(左列)、矢状面(中列)和轴状面(右列)。
**b–e, 纤维束追踪:**FA图(b),以及在选定的感兴趣区域(ROI)中的DT场,包括DTI张量场(c)和HARDI张量场(d),以及两条重建的流线(e):一条位于皮质脊髓束的流线(左)和另一条位于胼胝体的流线(右)。
本质上,dMRI采集技术可以分为单壳层或多壳层。单壳层采集涉及单个非零b值,而多壳层采集涉及多个非零b值。**单壳层采集通常用于基本的DTI分析或高角分辨率扩散成像(HARDI),**例如在b = 1,000 s/mm2的实验中;多壳层用于HARDI(例如,用于解决交叉纤维问题,参考文献64,65),DKI,以及生物物理模型,如CHARMED和AxCaliber。
结构连接组学
纤维束追踪推动了基于影像的结构连接组学领域的发展,**该领域涉及对整个大脑神经连接的全脑研究。**自其起源以来,已经提出了各种技术和方法来从dMRI中建模神经束。
纤维束追踪的不同方法
所有纤维束追踪技术都涉及根据dMRI估计的局部主要方向重建纤维束流线(图5)。从历史上看,DTI被用于纤维束追踪,使用诸如**连续追踪纤维评估(FACT)**等方法。FACT是一种经典的纤维束追踪方法,它使用DT(扩散张量)场,然后将其简化为代表"最强"和最可能的矢量到矢量方向连接的向量。像FACT这样的技术使用DTI建模以确定性方式估计纤维束。

图5:纤维束追踪
a, 代表整个大脑纤维束的纤维图,根据扩散方向进行颜色编码,从不同视角呈现:冠状面(左列)、矢状面(中列)和轴状面(右列)。b,c, 纤维束追踪估计,从感兴趣区域(ROI)的张量场开始(b),最终得到该区域的流线估计(c)。
更现代的应用使用非DTI方法进行纤维束追踪(见下文HARDI)。**目前更常用的是多纤维模型,包括基于方向分布函数(orientation distribution function, ODF)的追踪,也称为纤维ODF(fODF)或纤维方向分布(fiber orientation distribution, FOD)。**这三个术语都是使用概率密度函数来描述复杂纤维结构的方向性,该函数在体素基础上量化与设定方向相对应的分布。所有纤维束追踪算法都使用dMRI来揭示大脑中白质纤维的轨迹,基于主要扩散方向使用重建技术进行流线估计。然而,纤维追踪算法采用不同的方法来推断白质结构:
**确定性纤维束追踪:**使用线传播算法描绘白质通路。线传播过程从识别合适的起始种子点开始,然后沿估计的纤维方向传播,直到满足纤维终止标准。确定性纤维追踪的主要限制是它从每个种子点提供单一的白质纤维估计,而没有任何关于路径估计可能性或置信度的指示。
**概率性纤维束追踪:****旨在通过使用概率分布为路径分配可能性来处理确定性纤维追踪的限制。**这些算法考虑到dMRI中的噪声可能导致线传播错误,进而对重建的纤维束产生显著的累积效应。然而,概率性纤维追踪并不被认为比确定性纤维追踪更精确,因为它使用相同的基本方法,因此受到类似的挫折。一些概率性纤维追踪算法在局部尺度上使用贪婪优化技术,导致处理时间延长,而其他算法则从ODF中随机选择方向,提高了效率。
**全局纤维束追踪:**这类纤维束追踪算法在概念和方法上与流线纤维束追踪不同。**全局纤维束追踪涉及找到最能解释测量的DWI数据的完整纤维配置,****使用贪婪算法同时重建所有纤维。**每个纤维段被视为一个模型参数,作为单个各向同性高斯模型贡献。然后优化这些参数以形成更长的段链或纤维束,整体曲率较低。**这种方法的主要限制在于这组算法的贪婪、耗时性质。**尽管如此,全局纤维束追踪已被证明能更好地处理噪声数据集并更准确地重建复杂的纤维解剖结构,产生的纤维图的密度值与测量数据更直接相关。
上述方法涉及全脑纤维束追踪,用于推断结构性大脑连接。其他方法包括基于感兴趣区(ROI)的纤维束追踪,它不是为连接性设计的,而是针对特定的纤维结构。**基于ROI的纤维束追踪仅关注追踪选定的纤维群,如视辐射或皮质脊髓束。**其种子点选择和评估方法相应地有所不同,取决于成像需求以及所检查的纤维结构的位置和解剖。
纤维束追踪的高级技术
尽管纤维追踪存在概念和方法上的限制(如上所述),但在纤维追踪的采集、处理、建模、分析和可视化方面仍在不断取得重要进展。**最近的一项纤维追踪研究发现了大脑前部区域的一条此前未知的双侧纤维束,命名为上前束,形状类似于扣带束的前部但位置更靠前。**该研究在不同受试者、不同的dMRI数据集和各种处理流程中都展示了这条先前未记录的上前束通路的一致性。
HARDI经常被用作高级dMRI扫描协议,通过使用高分辨率的q空间来更好地捕捉交叉纤维(图4b-e)。使用高角分辨率和多个b值壳层创建了更高定义的图像,需要非DTI重建技术,如球棒模型(ball-and-stick, BAS)和约束球面反卷积(constrained spherical deconvolution, CSD):
**BAS(**球棒模型)**模型:**一种流行的概率性纤维束追踪方法,使用HARDI信号的几何特征来将轴突建模为具有单一半径和不透膜的圆柱体,同时假设轴突外部为各向同性扩散。BAS将信号分解为完全各向同性的部分(球)和完全各向异性的部分(棒)。此后,类似的模型被提出作为BAS模型的扩展,如球拍模型。
**CSD(约束球面反卷积):**另一种流行的纤维束追踪方法,基于称为球面反卷积的数学运算,从两个现有函数生成第三个函数。**CSD将HARDI信号表示为两个函数在球面坐标上的卷积运算:单个定向纤维集的信号(即响应函数)和FOD。**结果是对每个体素中纤维方向分布的估计。
在最近的应用中,**通过从白质和灰质表面的交界处播种纤维束,大大减少了纤维束追踪错误。**其他现代应用尝试使用白质图谱和人工智能来找到逻辑的、基于知识的纤维束。然而,这些方法仍处于起步阶段。
纤维束追踪标准
无论采用何种方法,所有纤维束追踪技术都使用dMRI来重建纤维束流线。为避免错误传播,流线的流动和停止遵循几个标准:
**平滑度标准:**限制流线估计中最大可能弯曲的曲率阈值,用于避免估计过度弯曲和不准确的流线,并克服交叉纤维的问题。
**各向异性标准:**限制流线向各向同性区域传播的阈值,用于避免在没有主导方向的区域内估计流线,这些区域中矢量场是不相关的。
**解剖标准:**基于对预期纤维束解剖的先验知识的一系列标准,例如,预期含有灰质的区域。
对于连接组学中的纤维束追踪应用,**种子点选择和终止标准尤为重要。**终止标准涉及确定流线终点的各种规范和阈值,包括上述平滑度、各向异性和解剖标准。另一方面,种子点选择标准涉及流线流动开始传播的种子点或起始点的数量、密度和位置。
纤维图评估
评估纤维图的准确性涉及将皮质连接模式与预期值的基准事实进行比较。这种对区域对之间连接(或缺乏连接)的比较,涉及使用混淆矩阵,**该矩阵使用四个参数总结分类模型的性能:****真阳性(有效连接)、真阴性(预期没有连接的地方确实没有连接)、假阳性(预期没有连接的地方出现连接)和假阴性(预期有连接的地方没有连接)。**可以从这些值中提取其他参数,如敏感性和特异性。一种用于评估不同纤维束追踪变体准确性的工具是Tractometer,这是一个在线工具,可测量不同成像和处理选择对结果纤维图的影响。然而,大多数评估通常是主观进行的,由神经解剖学家来判断一个纤维束是否合乎逻辑。例如,**当寻找特定连接(如胼胝体)时,会进行一个迭代的、手动的过程,移除虚假流线,直到达到预期的神经解剖学表现。虽然这样的评估不能在大型数据集和所有重建的纤维上进行,但对于任何希望使用纤维束追踪的人来说,经历这种与已知解剖结构相关的体验都很重要,以了解陷阱和假连接的程度。
纤维束追踪的错误和局限性
尽管纤维束追踪有许多优点,但这个过程也存在几个方法论上的错误和局限性。一个基本的局限性涉及方法选择的强烈影响。方法和纤维束追踪算法的选择对结果纤维图的准确性有很大影响,揭示了敏感性和特异性之间的权衡。以下是当今纤维束追踪面临的一些主要挑战:
**重建复杂几何结构的困难:**纤维束追踪中最具挑战性的问题之一是估计复杂的纤维结构,如重叠、分支和交叉通路。当通路涉及更复杂的几何结构时,由于单个体素内值的平均(部分体积效应),从局部方向场推断连接性变得越来越容易出错。**交叉纤维的错误计算通常在联络纤维中表现明显,如在小钳状纤维与放射冠的交叉处,以及皮质脊髓束扇形与上纵束的交叉处。**虽然在局部尺度上已经提出了一些解决交叉纤维的方法,但在全局尺度上这个问题仍然存在。**瓶颈问题可能是一个更大的重建挑战,**涉及在体素(或一组体素)内分离在分支到不同方向之前汇聚的纤维。瓶颈在某些区域很常见,如枕叶深部的白质,在前后方向上,包括多个具有相似方向的单独白质束。
**难以准确描绘纤维束边界:**由于轴突可以在纤维束的任何点分裂和合并,纤维束追踪在准确确定流线边界方面面临挑战。**终止点计算错误的主要原因是与体素级方法相关的部分体积效应。**在这种情况下,部分体积效应不仅涉及具有不同方向的白质纤维出现在同一体素中的情况,还涉及白质和灰质同时出现在单个体素中的情况。这些挑战在灰质中横向(沿皮质折叠,即沟回偏差)和径向(关于流线的层状起始和终止)都会遇到。这种困难还导致了对大脑皮质的有偏表示,将其视为一个忽视其微观结构组成的单一均质单元。此外,它还引发了关于缺乏直接纤维束定义的问题,这进一步加剧了在没有明确基准事实的情况下验证体内成像的固有困难。
重建非常"强"和非常小的纤维束的困难:即使使用高分辨率图像,纤维束追踪通常会导致高假阳性率,**产生的纤维图包含的无效(不合逻辑和/或断开的)纤维束多于有效纤维束。这个问题的主要原因之一是纤维追踪算法倾向于对强纤维束赋予越来越高的确定性。同时,**由于难以重建直径为2毫米或更小的非常小的纤维束(如前联合),纤维束追踪也会出现高假阴性率。
结构网络
连接性研究的主要挑战是充分表示纤维束追踪结果,使其可以在受试者内部和受试者之间进行量化和比较。在过去十年中,图论工具的使用已成为大脑连接性分析的最新技术。大脑连接性图通常被建模为网络图,这是一种数学结构,使用图边来模拟不同组件之间的相互作用,这些组件表示为图节点。**在大脑网络中,节点表示皮质(或皮质下)区域,边表示区域对之间的连接。**网络图被总结为节点列表和相应的边列表。节点是具有3D坐标的标记顶点或空间点。边是连接两个节点的线,具有绝对或相对强度的加权值,或无权二进制值。边可以是无向的或有向的。
**目前,连接组学领域包括三种类型的大脑连接性:****结构连接性、功能连接性和有效连接性,**每种连接性使用不同的MRI模态进行探索,并被建模为不同类型的网络图。结构连接性表示连接不同皮质区域的解剖链接或纤维束。结构连接组使用dMRI纤维束追踪测量,**因此被建模为无向加权网络图,其中权重表示解剖链接的"强度"。
网络构建
**节点选择:**大脑网络节点应在空间上受到限制,并表现出一些内在一致性,如节点内细胞结构或功能的相似性。同时,节点应表现出一些外部差异或节点间连接的变异性。除了这些一般准则外,**对这些大脑网络单元的最佳定义尚无共识。**节点的定义方式取决于我们希望探索的拓扑结构,侧重于长程或细粒度连接。一方面,选择包括单个MRI体素的小节点将产生一个非常详细的网络,具有许多节点和边,但也可能包含与分辨率相关的不准确性,可能掩盖更显著的连接模式。另一方面,选择大单元将产生看似不太详细的网络,节点和边较少,但可能更好地展示主要的连接模式。例如,**前者更适合探索异质性联合系统的细粒度变化,而后者更适合进行受试者间比较。**节点选择有两个基本经验法则:
**完整的拓扑覆盖:**要获得全脑结构连接组,节点必须覆盖所有皮质区域,最好还包括皮质下区域。
**无拓扑重叠:**为了真实表示每个网络节点的连接,必须避免皮质区域之间的重叠。
图谱或皮质分区是检查皮质连接模式的透镜。存在各种各样的图谱,包括以下一些:细胞构筑、髓鞘构筑、解剖、概率、随机、功能、数据驱动、基于体素和多模态图谱。另一种分区选择涉及基于节点空间独立性的盲源分离。这种数据驱动的分区需要根据网络的同质性、准确性、可重复性或稳定性预先指定区域(或节点)的数量。为了更好地进行受试者间比较,最好使用来自结构和功能连接的数据跨模态和个体来划分大脑区域。
**边选择:**关于边的定义,**结构连接组中连接两个节点的边的权重通常由纤维图中连接两个相应区域的流线数量表示。**使用流线数量作为权重是有偏差的,因为在估计复杂流线和流线端点时,这种方法容易出错(参见"纤维束追踪的错误和局限性"一节)。此外,使用流线数量作为边也受到固有限制,因为缺乏除存在或不存在之外的额外流线特征。理想情况下,**结构连接组中的边应准确表示影响动作电位传播的轴突连接的所有特征,包括轴突髓鞘化、长度、大小和密度。**在使用流线数量作为边时,这些微观结构特征是缺失的,而与FA等测量更相关。然而,尽管FA对轴突微观结构敏感,但它也容易受到部分体积效应和轴突离散度估计错误的影响。
这个问题,也称为轨迹计数偏差,**通过各种技术以更具生物学意义的方式重新加权网络中的边来解决。**一些技术基于归一化的轴突直径重新加权边,使用诸如COMMIT和AxSI等方法(参见"参数方法:生物物理模型"一节)。其他技术旨在通过过滤边的方法来增加边的生物学相关性,如球面去卷积信息过滤纤维图。线性纤维束评估是另一种纤维束过滤方法,根据每个纤维束对预测扩散数据的贡献分配权重。
为了分析得到的结构网络,加权边可以被归一化、二值化或保持现有的流线范围不变。**阈值选择在密集连接的网络中尤为重要,**但也可能是任意的(如百分位数、平均值等)。虽然加权边被假定包含有关弱连接的更多信息,但二值边相对更容易表征和在受试者间进行比较。
网络分析
将大脑连接性建模为网络图的好处在于可以应用图论技术来分析网络图的结构模式。要更好地理解大脑网络的结构和功能,需要审视其拓扑结构。大脑拓扑可以使用网络分析工具提取。复杂网络分析处理的是既大又复杂的现实生活网络,不同于均匀随机或有序网络。复杂网络展现了简单网络中不会出现的非平凡拓扑特征,如随机图。大脑网络在其节点度量中表现出这些非平凡特征。例如,度分布的重尾、高聚类系数以及社区和层次结构(定义见补充表1)。此外,图论提供了一套工具,可以简单高效地进行不同度量的受试者间比较。网络度量包括在局部尺度(子网络)上评估的每个节点的度量,以及在全局尺度上评估整个网络的度量。**大脑连接性度量通常可以分为三类:****中心性度量,**表示单个节点的重要性;**分离度量,**表示在节点簇中进行专门处理的能力;**以及整合度量,**表示跨节点簇组合信息的能力。
小世界性是网络的一个特征,它调和了对处理簇分离的需求与对跨网络信息整合的需求。**小世界网络在专门处理簇的分离和跨这些簇的信息整合之间保持平衡。这些网络表现出高效率,由平均最短路径的低值引起,大约遵循对数定律。****大脑网络不仅表现出"小世界性",还表现出"富人俱乐部组织",**这是一种高度节点也倾向于高度互连的现象。属于"富人俱乐部"的节点被认为是网络枢纽。有关具有神经生物学意义的网络度量列表,包括中心性、分离、整合和枢纽的全局和局部度量,请参见补充表1(参考文献7)。有关大脑网络中各种度量的可视化,请参见图6d-f。探索结构连接性的其他方法包括数据驱动的聚类和模块性,**以及使用皮质梯度来映射连接性趋势。**预计模块性将在未来神经影像研究中定义网络拓扑方面发挥关键作用。

图6:网络可视化和度量
**a-c,网络可视化(上):**全脑纤维束追踪图(a)、Brainnetome图谱区域间的连接矩阵(b)和Von Economo-Koskinas图谱区域间的环形图©。
**d-f,网络度量(下):**三种不同的局部网络度量,包括度(d)、聚类系数(e)和核心/外围(f)。**这三种网络度量分别代表中心性、分离性和枢纽的示例度量。**所有网络和图像均从上方视角观看。
网络可视化
将大脑连接性建模为网络图的另一个好处在于能够使用各种现有工具进行高级网络可视化。将大脑网络建模为网络图会产生两个列表:带有空间位置(x, y, z)的网络节点(N)列表,以及连接节点对(节点A, 节点B)的网络边(M)列表。这些网络可以通过几种不同的方式进行可视化(图6a-c):
**连接矩阵:**一个N × N矩阵C,其中行和列代表网络节点,单个值C(i, j)代表节点i和j之间的连接强度。无向网络被可视化为对称连接矩阵,有向网络被可视化为非对称矩阵。
**网络图:**网络的经典表示,其中节点在空间上表示为具有位置(x, y, z)的球体,边表示为连接节点对的线。无向网络中的边被可视化为线,有向网络中则被可视化为箭头。
**环形图:**网络的环形可视化,其中一个圆被分为多个扇区,代表网络节点,这些扇区通过弯曲的线连接,代表网络边。
在上述所有方式中,边的权重通常通过连接的宽度和颜色来可视化。有关用于大脑网络分析和可视化的几个有用工具箱的列表,请参见表3。
表3 大脑网络分析和可视化工具

结论
扩散磁共振成像(dMRI)通过测量神经可塑性后的微观结构变化,以及无创地可视化和量化大脑中的信息传递,为研究大脑生理学提供了机会。我们预计,在转化性大脑研究中,dMRI将越来越多地被用来补充功能磁共振成像(fMRI)研究。
参考文献
Shamir, I., & Assaf, Y. (2024). Tutorial: a guide to diffusion MRI and structural connectomics. Nature Protocols, 1-19.