北京时间 9 月 13 日午夜,OpenAI 正式发布了一系列全新的 AI 大模型,专门用于应对复杂问题。

这一新模型的出现代表了一个重要突破,其具备的复杂推理能力远远超过了以往用于科学、代码和数学等领域的通用模型,能够解决比之前更难的难题。
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
据 OpenAI 介绍,此次在 ChatGPT 和大模型 API 中发布的是该系列的首款模型——o1-preview,当前仅为预览版。

除 o1 外,OpenAI 还展示了下一次更新的开发情况及其评估结果。o1 模型一经问世便创造了多项历史记录。
首先,o1 是此前从山姆・奥特曼到 OpenAI 科学家们一直在「高调宣传」的草莓大模型,它展现了真正的通用推理能力。
在多个复杂基准测试中表现卓越,相比于 GPT-4o 显示出了显著的提升,使大模型的能力从“乏善可陈”跃升到卓越水平。

o1 无需专门训练即可在数学奥赛中获得金牌,甚至在博士级别的科学问答中超越了人类专家。
Cognition AI 是开发首个 AI 软件工程师 Devin 的公司,该公司表示过去几周一直与 OpenAI 紧密合作,利用 Devin 评估 o1 的推理能力。
结果显示,与 GPT-4o 相比,o1 系列模型在处理代码智能体系统方面取得了巨大进展。

在实际应用中,o1 上线后,ChatGPT 在回答问题时变得更为深思熟虑,而非立即作答。
这种变化类似于人类大脑中的系统 1 和系统 2,ChatGPT 已经从只使用系统 1(快速、自动、直观、容易出错)进化到能够使用系统 2 的思维方式(缓慢、深思熟虑、有意识、可靠)。
这种改进使其能够解决之前无法解决的问题。从今天的 ChatGPT 用户体验来看,这虽然只是一个小进步,但在复杂的数学和代码问题上,差异变得非常明显。更重要的是,未来的发展路径已经开始清晰展现。

为了强调 o1 相对于 GPT-4o 在推理性能上的改进,OpenAI 对其进行了多项人类考试和机器学习基准测试。
实验结果显示,在绝大多数推理任务中,o1 的表现明显优于 GPT-4o。在许多需要高强度推理的基准测试中,o1 的表现可与人类专家相媲美。
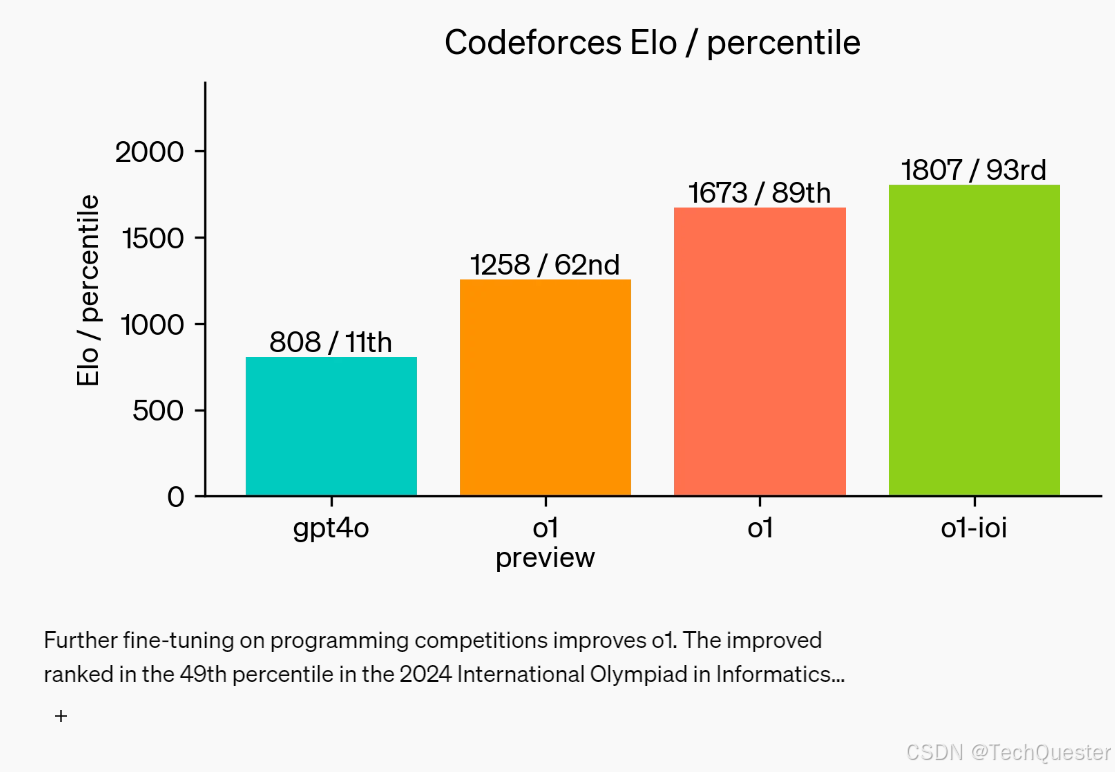
最近的一些前沿模型在 MATH 和 GSM8K 上的表现非常出色,导致这些基准测试在区分模型时不再有效。

因此,OpenAI 在 AIME 测试中对 o1 进行了评估,AIME 是一项测试美国最优秀高中数学学生的考试。
在 2024 年的 AIME 考试中,GPT-4o 平均仅解决了 12% (1.8/15) 的问题,而 o1 在每个问题只有一个样本的情况下平均解答正确率达 74% (11.1/15),在 64 个样本一致的情况下为 83% (12.5/15),使用学习评分函数对 1000 个样本进行重新排序时,达到了 93% (13.9/15)。
13.9 分的成绩足以进入全美前 500 名,并高于美国数学奥林匹克竞赛的分数线。
OpenAI 还在 GPQA Diamond 基准测试上评估了 o1,这是一个测试化学、物理和生物学专业知识的困难智力基准。
为了与人类进行对比,OpenAI 邀请了具有博士学位的专家来回答 GPQA Diamond 的问题。
实验结果显示,o1 在该基准测试中表现优于人类专家,成为第一个在此基准上实现这一成就的模型。
需要注意的是,这些结果并不意味着 o1 在所有方面都比博士更有能力——它只是更擅长解决某些博士也应该解决的问题。在其他几个机器学习基准测试中,o1 也实现了新的最先进水平(SOTA)。
启用视觉感知能力后,o1 在 MMMU 基准上得分 78.2%,成为第一个在表现上与人类专家相当的模型。此外,o1 在 57 个 MMLU 子类别中的 54 个上优于 GPT-4o。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard
推荐阅读:
OpenAI的《Her》为何迟迟未能面世?
GPT-4o无法取代程序员! IEEE研究显示,困难编码正确率仅为0.66%!_chatgpt4o正确率多少