【Vision结合Diffusion】模型的研究方向,探索了如何利用扩散模型在数据空间中模拟随机游走的特性,以生成高质量和逼真的图像。这一领域的研究,通过结合视觉感知和文本描述,推动了图像合成技术的发展,尤其是在个性化图像生成和修复方面。它的意义在于提供了一种新的视角和方法,使得机器能够更好地理解和生成与人类描述相匹配的视觉内容,极大地扩展了计算机视觉和人工智能的应用范围。此外,这一方向的研究还促进了对图像生成过程中信息流动和控制机制的深入理解,为实现更加精细和可控的图像编辑工具奠定了基础。通过这些技术,可以为艺术创作、娱乐、设计等多个领域带来创新,同时也引发了对人工智能生成内容伦理和使用的讨论,对技术发展和社会责任提出了新的要求。
为了帮助大家全面掌握【Vision+Diffusion】的方法并寻找创新点,本文总结了最近两年【Vision+Diffusion】相关的15篇顶会论文研究成果,这些论文、来源、论文的代码都整理好了,希望能给各位的学术研究提供新的思路。

三篇论文详细解析
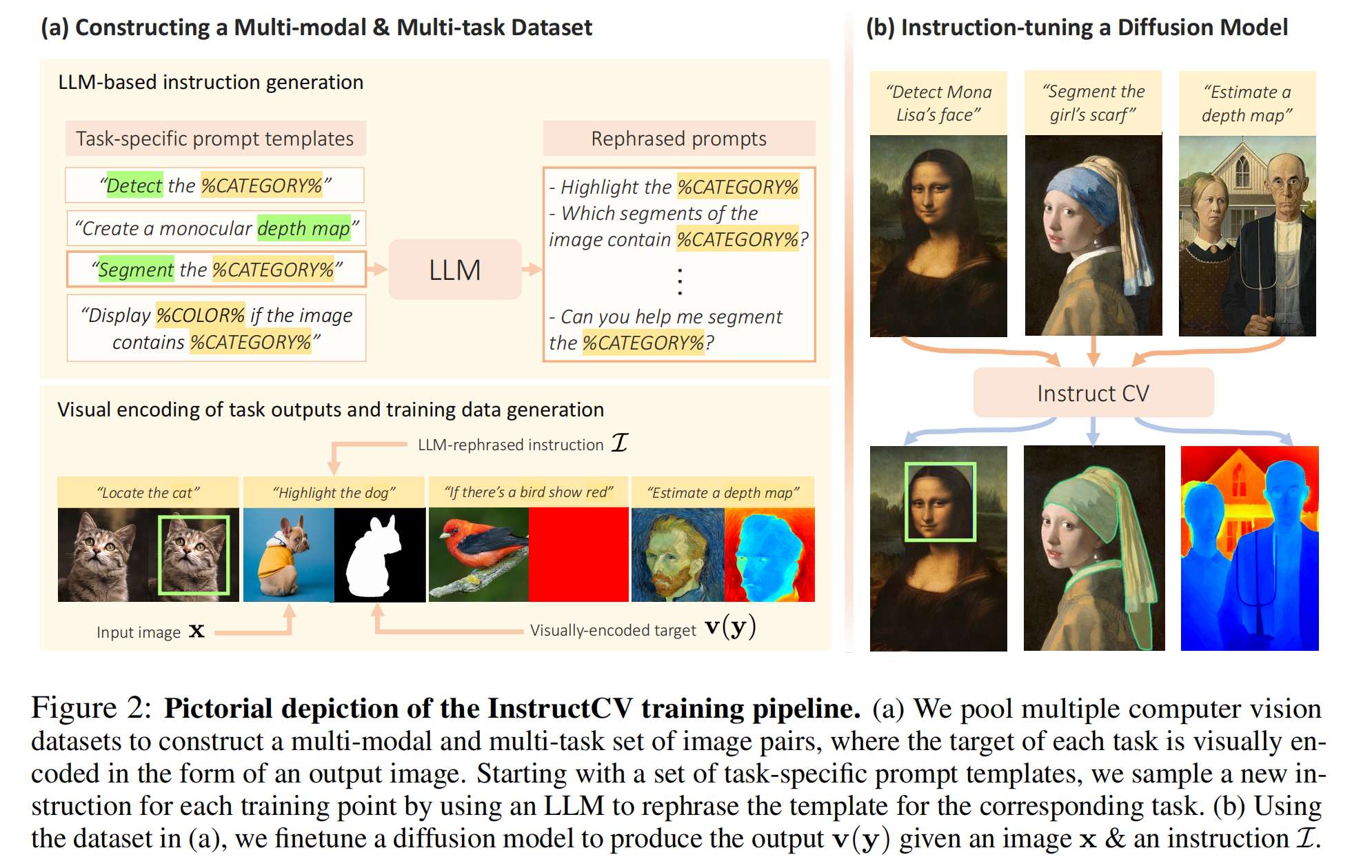
1、INSTRUCTCV: INSTRUCTION-TUNED TEXT-TO-IMAGE DIFFUSION MODELS AS VISION GENERALISTS
方法
-
统一语言接口:提出了一种用于计算机视觉任务的统一语言接口,通过自然语言指令来执行任务,而不是为每个任务设计特定的模型架构和损失函数。
-
文本到图像生成问题:将多种计算机视觉任务视为文本到图像生成问题,其中文本代表描述任务的指令,生成的图像是视觉编码的任务输出。
-
多模态多任务训练数据集:通过结合多个计算机视觉数据集,包括分割、目标检测、深度估计和分类任务,构建了一个包含文本指令、输入图像和视觉编码任务输出的多模态多任务训练数据集。
-
指令调整(Instruction-Tuning):使用大型语言模型对提示模板进行释义,生成多样化的文本指令,并通过这一过程创建了包含输入和输出图像以及注释指令的多模态多任务训练数据集。
-
InstructPix2Pix架构:采用InstructPix2Pix架构,对文本到图像扩散模型进行指令调整,将其功能从生成模型转变为受指令引导的多任务视觉学习器。
-
条件扩散模型:使用预训练的条件扩散模型(Stable Diffusion),通过指令调整数据集进行微调,将模型功能转变为受语言引导的多任务视觉学习器。
创新点
-
指令引导的多任务学习:InstructCV模型能够根据自然语言指令执行多种计算机视觉任务,这在以往的研究中并不常见,它通过将任务转化为文本到图像的生成问题来实现。
-
多模态数据集的构建:创新地结合了多个视觉任务的数据集,并通过大型语言模型生成多样化的指令,这增加了数据集的丰富性和语义多样性。
-
指令调整技术:通过指令调整技术,使得预训练的扩散模型能够适应新的多任务视觉学习框架,这是一种新颖的模型微调方法。
-
泛化能力:InstructCV展现出对未见数据、类别和用户指令的出色泛化能力,这在以往的通用视觉模型中是一个挑战。
-
计算成本降低:相比于从头开始训练的通用模型,InstructCV通过指令调整在相对较少的训练步骤后就能实现与专门设计模型相媲美的性能,大幅减少了计算成本。
-
实时推理潜力:尽管模型的推理速度可能不如特定任务的模型快,但它在实时推理方面的潜力是一个值得关注的创新点。
IMG_256
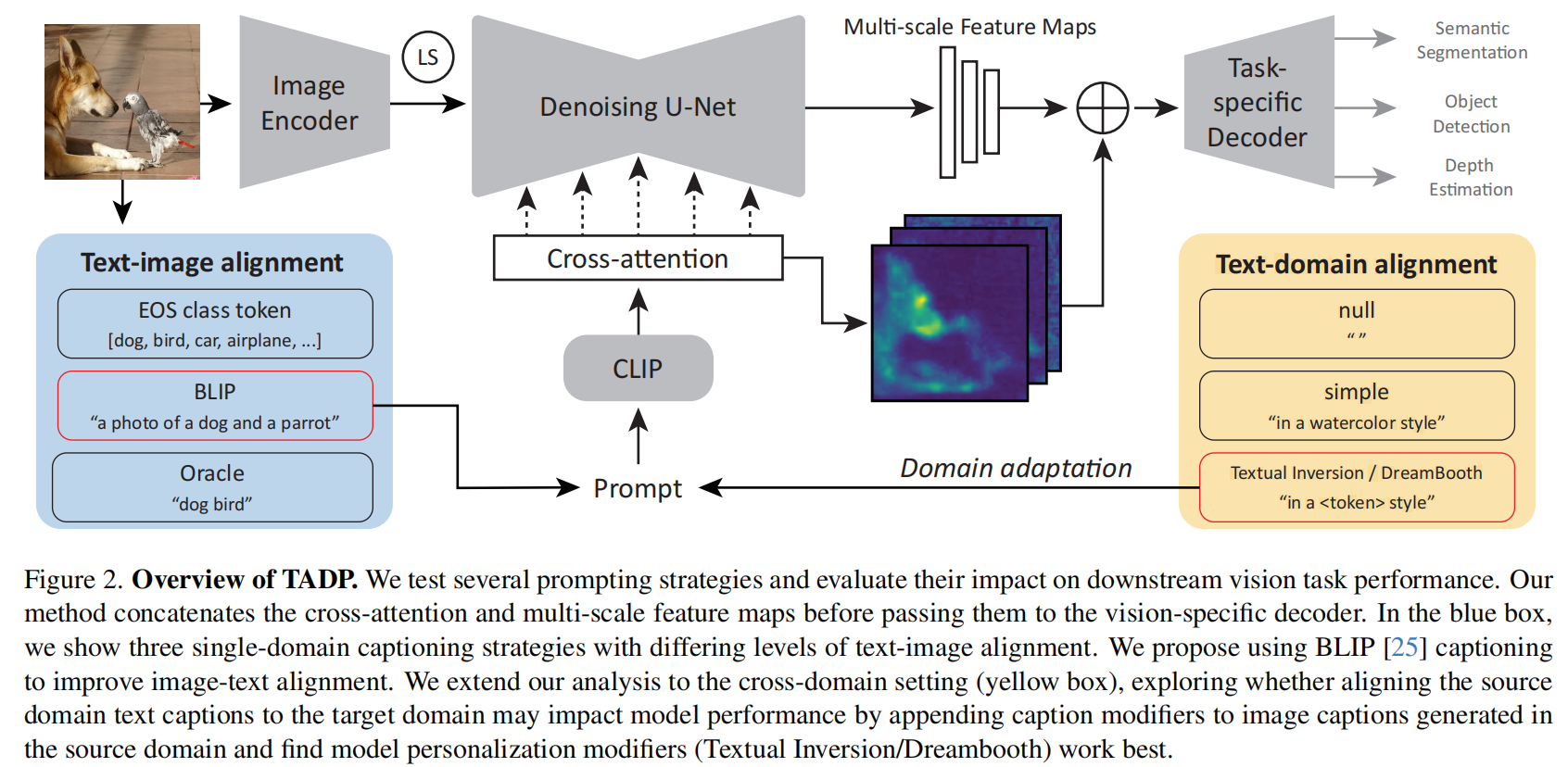
2、Text-image Alignment for Diffusion-based Perception
方法
-
文本图像对齐(Text-image Alignment):提出了一种新方法,利用自动生成的图像标题来改进文本和图像的对齐,从而显著提高模型的感知性能。
-
改进的跨注意力映射(Cross-attention Maps):通过自动生成的标题改善了模型的跨注意力映射,这有助于模型更好地理解和处理视觉任务。
-
领域适应(Domain Adaptation):研究了在跨领域视觉任务中,如何通过文本目标领域对齐来提高模型在目标领域的表现。
-
模型个性化(Model Personalization):使用文本反演(Textual Inversion)和DreamBooth等技术对模型进行个性化,以更好地适应目标领域。
-
BLIP-2(Bootstrapping Language-Image Pre-training):使用BLIP-2模型来生成与图像对齐的文本标题,作为扩散模型的条件输入。
-
不同提示方法(Prompting Methods):系统地探索了不同的提示方法,包括简单字符串、类名字符串、以及使用BLIP-2生成的标题,来评估它们对下游视觉任务性能的影响。
创新点
-
文本图像对齐的系统研究:首次系统性地研究了文本图像对齐在扩散模型感知任务中的作用,包括语义分割、深度估计和目标检测。
-
跨领域任务中的文本目标领域对齐:提出了一种新的方法,通过在训练时将文本提示与目标领域对齐,来提高模型在目标领域的性能。
-
使用BLIP-2生成对齐的文本提示:利用BLIP-2生成与图像内容直接相关的文本提示,而不是使用传统的平均EOS标记或类名字符串。
-
模型个性化技术的应用:通过文本反演和DreamBooth技术对模型进行个性化,以适应目标领域,这在跨领域任务中显示出了性能提升。
-
在多个数据集上达到新的最佳状态(SOTA):在ADE20K数据集上的语义分割任务以及NYUv2数据集上的深度估计任务中取得了新的最佳性能。
-
跨领域任务的广泛评估:在多个跨领域数据集上评估了提出的方法,包括Pascal VOC到Watercolor2K、Comic2k以及Cityscapes到Dark Zurich和Nighttime Driving,并在这些任务上取得了显著的性能提升。
IMG_257
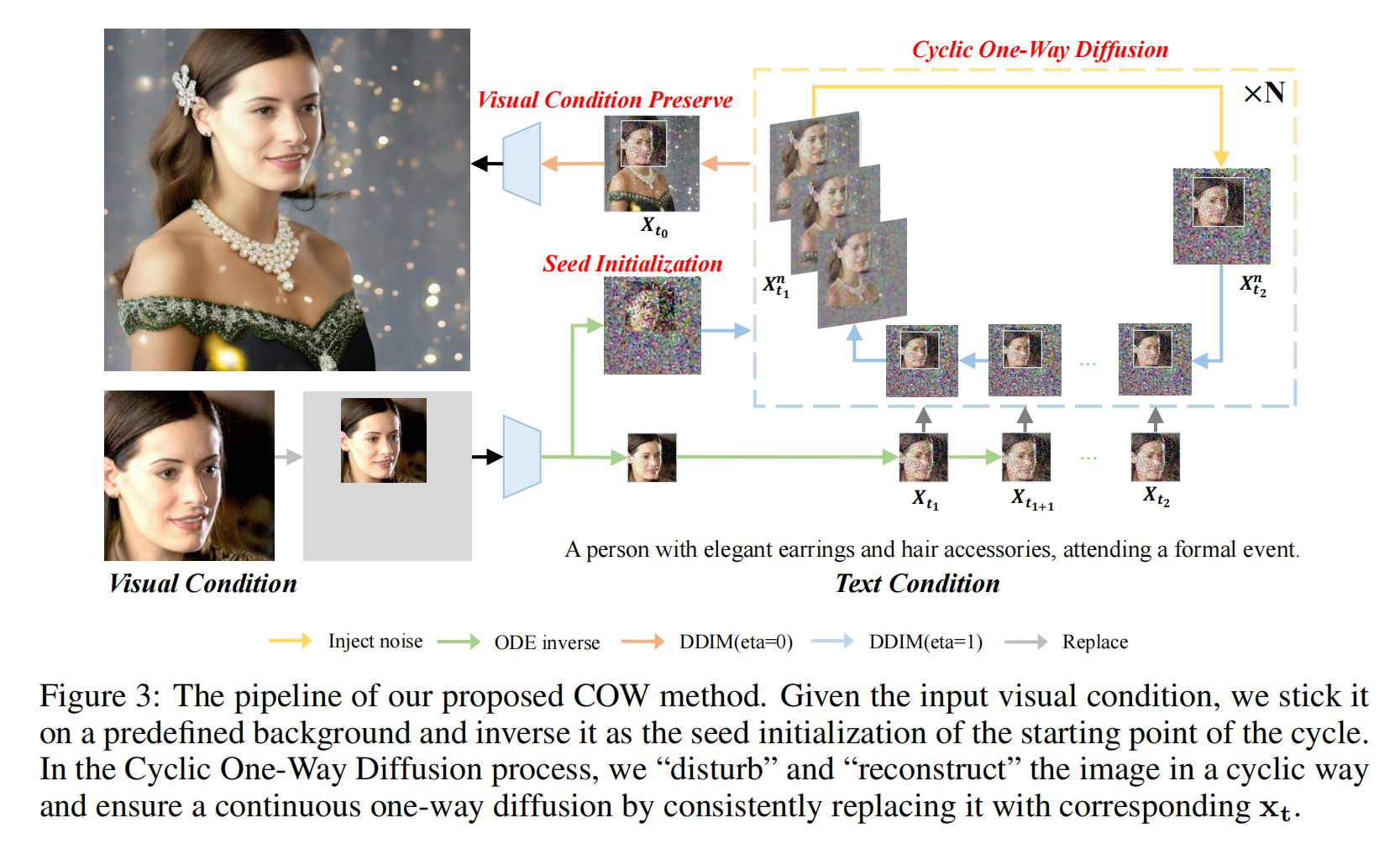
3、Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation
方法
-
Cyclic One-Way Diffusion (COW): 提出了一种新的方法,通过控制扩散模型中的扩散方向,以适应多样化的定制应用场景,同时保留来自条件的低级像素信息。
-
Seed Initialization: 通过将用户指定的视觉条件放置在预定义的背景上,并将其作为循环起始点的种子初始化,以减少与视觉条件的布局冲突。
-
Cyclic One-Way Diffusion Process: 在生成过程中,通过周期性地“扰动”和“重建”图像,将语义信息重新注入,以最大化从视觉条件到整个图像的信息流。
-
Visual Condition Preservation: 在生成过程的后期阶段,通过替换相应区域来明确控制视觉条件的保留程度,以有效平衡视觉和文本条件的冲突。
创新点
-
控制信息扩散方向: 与大多数现有方法不同,COW方法不通过微调基础文本到图像扩散模型或学习辅助网络来整合额外条件,而是提供了一种新的视角来理解任务需求,并以无需学习的方式适用于更广泛的定制场景。
-
无需训练的框架: COW是一个无需训练的框架,它利用预训练的扩散模型的内在特性,通过周期性地扰动和重建图像,实现了对生成过程的精细控制。
-
高效的图像生成: COW方法在保持对文本和视觉条件高保真度的同时,能够在短短6秒内生成图像,远快于其他定制方法,如DreamBooth。
-
广泛的应用场景: COW方法不仅适用于传统的视觉条件修复,还能够处理视觉文本条件的风格转换等多样化的定制应用场景。
-
平衡视觉与文本条件: COW方法能够有效地理解和平衡不同模态的信息,并适应性地调整以在广泛的条件下产生高质量的图像,展示了其在处理多样化定制场景中的通用性和有效性。
IMG_258