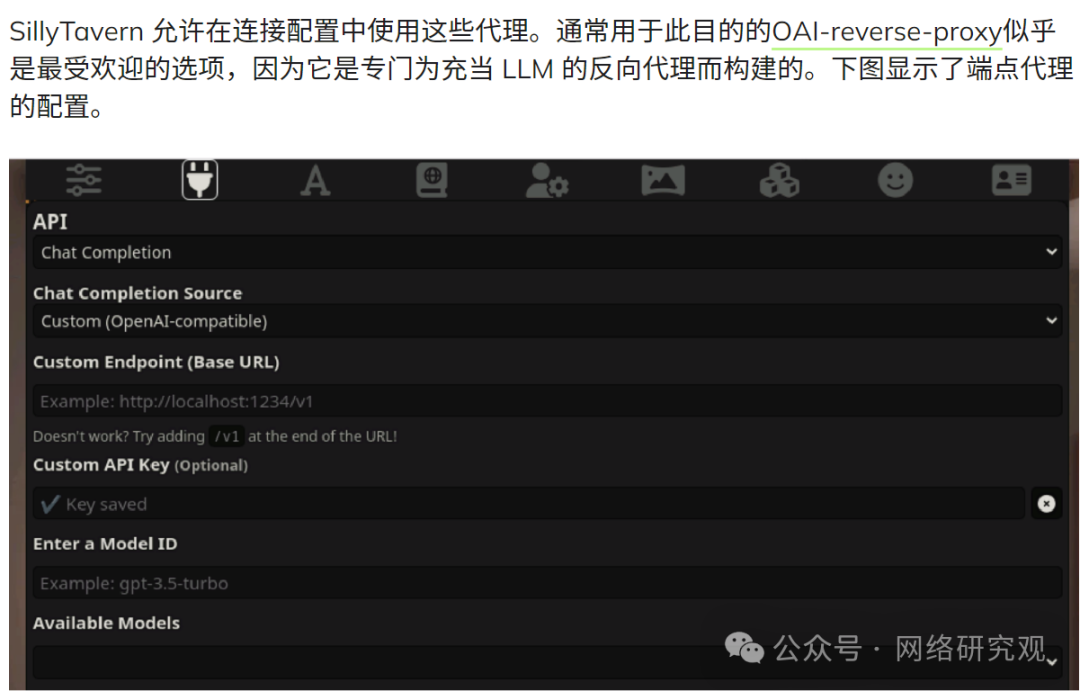
监督学习之cost function
- 成本函数
- 权重、偏置
- 如何实现拟合数据
- 成本函数是如何寻找出来w和b,使成本函数值最小化?
在线性回归中,我们说到评估模型训练中好坏的一个方法,是用成本函数来衡量,下面来详细介绍一下
成本函数
权重、偏置
在线性回归( https://blog.csdn.net/zishuijing_dd/article/details/142131936?spm=1001.2014.3001.5501)一节中,我们要实现的线性模型就是要找出输入x和y的映射关系,这种映射关系可以被表示为y = wx + b,其中需要被确定的两个值,w被称做权重,b被称做偏置。

假设样本数据和拟合的直线如下图:

那么w实际是斜率,b就是截距。样本中的数据用(x(i),y(i))表示,样本中的y值是真实值,通常用y_label标记,而拟合的y = wx + b 线性模型,输入x(i)计算得出的y_predict 被称为预测值。
训练的目标就是让y_predict更接近于y_label,也就是称为更拟合。
如何实现拟合数据
方法就是使用成本函数,这是一种评估y_predict和y_label的差值(误差)的方法,通常用的成本函数是样本数据误差的平方和,也就是(y_predict-y_label)2的和,当然为了防止误差无限变大,我们使用均值,也就是再除上样本个数,整体的公式如下:

注意一下,这个除了2倍的样本数,主要是为了后面计算简单,y_predict是函数f(w,b)的输出,所以公式最终成了上述样式。
这个误差计算方式就叫做均方误差成本函数。
所以实际上我们训练函数的目标就是,寻找合适的w和b,让这个成本函数的值更小
不同的应用经常会选用不同的成本函数,但是平方误差几乎是线性回归的必选,在很多应用上的效果都不错。
成本函数是如何寻找出来w和b,使成本函数值最小化?
为了简化计算,以下面情况为例:
假设样本数据为(1,1),(2,2),(3,3)
偏置b 为0
我们的回归函数就是关于输入x的一个函数,所以它的横轴是x,如下图所示:

当w取不同值的时候,我们来计算成本函数:
注意一点J是关于w的函数,当w 为1的时候,按照公式计算成本函数J:

通过计算,我们知道当w为1的时候,成本函数的结果为0
然后我们依次计算w为0.5,1.5等的时候,成本函数的结果,然后可视化画出成本函数的线:

10412c9d14268716fdea40.png)
通过对成本函数的观察,我们会找到一些w,使得成本函数尽量的小。这些w就是最终的w。
至此我们就找到了合适的w,当然b也是同样的方式。









![[Unity Demo]从零开始制作空洞骑士Hollow Knight第五集:再制作更多的敌人](https://i-blog.csdnimg.cn/direct/93717c69b249436e99d5b478cd623ef9.png)