随着人工智能技术的迅猛发展,智能对话系统在各行各业中的应用越来越广泛。本文将介绍一种名为ChatBI Agent的架构设计,并以电信运营商系统的经分数据统计Agent为案例,结合具体的代码实现,帮助读者了解这一系统的设计理念和实现方式。

一、架构总览
ChatBI Agent的架构图分为四个主要模块:规划模块、工具模块、行动模块和记忆模块。每个模块都有其独特的功能和相互协作的机制,确保系统能够高效、准确地完成各种复杂任务。
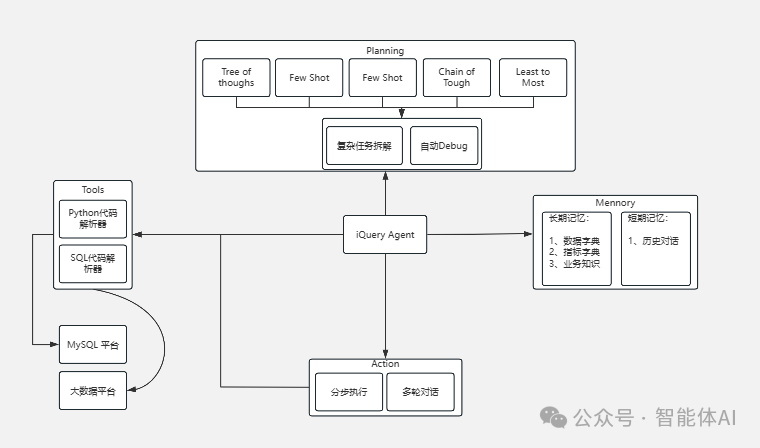
二、 规划模块 (Planning)
规划模块是ChatBI Agent的核心部分之一,负责任务的规划和策略制定。它包括以下几个子模块:
思维树通过构建一个树状结构,帮助系统在复杂问题中找到最优解。这一模块利用层次化思维方式,对问题进行分解和递进处理,确保在每个步骤上都能做出最优决策。
详解ChatBI Agent架构:打造高效数据统计系统
原创 智能体AI 智能体AI
2024年07月16日 07:01 湖南
随着人工智能技术的迅猛发展,智能对话系统在各行各业中的应用越来越广泛。本文将介绍一种名为ChatBI Agent的架构设计,并以电信运营商系统的经分数据统计Agent为案例,结合具体的代码实现,帮助读者了解这一系统的设计理念和实现方式。
一、架构总览
ChatBI Agent的架构图分为四个主要模块:规划模块、工具模块、行动模块和记忆模块。每个模块都有其独特的功能和相互协作的机制,确保系统能够高效、准确地完成各种复杂任务。
图片
二、 规划模块 (Planning)
规划模块是ChatBI Agent的核心部分之一,负责任务的规划和策略制定。它包括以下几个子模块:
思维树 (Tree of Thoughts)
思维树通过构建一个树状结构,帮助系统在复杂问题中找到最优解。这一模块利用层次化思维方式,对问题进行分解和递进处理,确保在每个步骤上都能做出最优决策。
class TreeOfThoughts:
def init(self):
self.tree = {}
def add_thought(self, level, thought):if level not in self.tree:self.tree[level] = []self.tree[level].append(thought)def get_optimal_path(self):optimal_path = []for level in sorted(self.tree.keys()):optimal_path.append(self.tree[level][0]) # 简化处理,只取每层的第一个思维return optimal_path
Few Shot 学习
Few Shot 学习是一种少样本学习方法,通过少量示例数据进行模型训练,使系统能够快速适应新任务。此方法极大地提高了模型的泛化能力和适应性。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
class FewShotLearner:
def init(self, model_name=‘gpt2’):
self.tokenizer = GPT2Tokenizer.from_pretrained(model_name)
self.model = GPT2LMHeadModel.from_pretrained(model_name)
def generate_text(self, prompt, max_length=50):inputs = self.tokenizer.encode(prompt, return_tensors='pt')outputs = self.model.generate(inputs, max_length=max_length, num_return_sequences=1)return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
Chain of Thought
Chain of Thought模块通过连贯的思维链条,帮助系统在复杂任务中保持逻辑一致性。每一步的推理结果都会作为下一步的输入,形成一个连贯的思维过程。
class ChainOfThought:
def init(self):
self.chain = []
def add_thought(self, thought):self.chain.append(thought)def get_chain(self):return ' -> '.join(self.chain)
Least to Most
Least to Most是一种从简单到复杂的任务处理策略。通过先解决简单问题,再逐步攻克复杂问题,确保系统在处理过程中始终保持高效和准确。
class LeastToMost:
def init(self, tasks):
self.tasks = sorted(tasks, key=lambda x: x[‘complexity’])
def execute_tasks(self):results = []for task in self.tasks:results.append(self.execute_task(task))return resultsdef execute_task(self, task):# 具体任务执行逻辑return f"Executed task: {task['name']}"
复杂任务解释
复杂任务解释模块负责将复杂的任务分解为可管理的子任务,并为每个子任务制定详细的执行计划。这一模块的存在,确保了系统能够应对各种复杂和多变的任务需求。
class ComplexTaskDecomposer:
def decompose(self, task):
sub_tasks = []
# 分解任务的具体逻辑
return sub_tasks
自动Debug
自动Debug模块通过自动化调试和错误修复,提升系统的稳定性和可靠性。当系统在执行过程中遇到错误时,能够自动检测并进行修正,确保任务顺利完成。
class AutoDebugger:
def debug(self, process):
try:
process.run()
except Exception as e:
self.fix_error(e)
def fix_error(self, error):# 错误修复逻辑pass
三、工具模块 (Tools)
工具模块为ChatBI Agent提供了各种必要的工具和平台支持,确保系统能够高效完成各项任务。
Python代码解析器
Python代码解析器能够解析和执行Python代码,使系统能够进行各种复杂的数据处理和计算任务。
def execute_python_code(code):
exec(code)
SQL代码解释器
SQL代码解释器负责解析和执行SQL查询,帮助系统从数据库中提取和处理数据。
import mysql.connectordef execute_sql_query(query):conn = mysql.connector.connect(user='user', password='password', host='localhost', database='database')cursor = conn.cursor()cursor.execute(query)result = cursor.fetchall()cursor.close()conn.close()return result
MySQL平台
MySQL平台为系统提供了一个稳定和高效的数据库管理平台,确保数据的存储和检索高效可靠。class MySQLPlatform:def __init__(self, config):self.conn = mysql.connector.connect(**config)def query(self, sql):cursor = self.conn.cursor()cursor.execute(sql)result = cursor.fetchall()cursor.close()return resultdef close(self):self.conn.close()
大数据平台
大数据平台使系统能够处理和分析海量数据,支持各种大数据应用场景,为系统提供强大的数据分析能力。
from pyspark.sql import SparkSession
class BigDataPlatform:
def init(self):
self.spark = SparkSession.builder.appName(“BigDataApp”).getOrCreate()
def process_data(self, data):df = self.spark.createDataFrame(data)# 数据处理逻辑return df.collect()
四、行动模块 (Action)
行动模块负责执行系统的各种任务和操作,通过与用户的交互,实现各种复杂的对话和任务处理。
公开对话
公开对话模块使系统能够进行开放式对话,与用户进行多轮互动,确保对话的连贯性和逻辑性。
class PublicDialogue:
def init(self):
self.dialogue_history = []
def add_message(self, message):self.dialogue_history.append(message)def get_dialogue(self):return '\n'.join(self.dialogue_history)
多轮对话
多轮对话模块通过记录和管理对话历史,确保系统能够在长时间对话中保持上下文一致性和逻辑连贯性。
class MultiTurnDialogue:
def init(self):
self.turns = []
def add_turn(self, user_message, agent_response):self.turns.append((user_message, agent_response))def get_full_dialogue(self):return '\n'.join([f"User: {t[0]}\nAgent: {t[1]}" for t in self.turns])
五、 记忆模块 (Memory)
记忆模块负责管理和存储系统的各种记忆信息,确保系统能够在复杂对话中保持信息的连贯性和一致性。
长期记忆
长期记忆模块负责存储系统的长期知识和信息,包括历史对话和业务知识,确保系统在长期任务中能够保持稳定和一致。
class LongTermMemory:
def init(self):
self.memory = []
def add_memory(self, info):self.memory.append(info)def get_memory(self):return self.memory
短期记忆
短期记忆模块负责存储系统的短期对话信息,确保系统在当前对话中能够准确记忆和调用相关信息。
class ShortTermMemory:
def init(self):
self.memory = []
def add_memory(self, info):self.memory.append(info)def get_memory(self):return self.memory
六、iQuery Agent的集成与工作流程
iQuery Agent作为ChatBI Agent的核心,负责将各个模块集成在一起,并通过协调各模块的工作,完成复杂任务。其工作流程如下:
任务规划:根据用户需求,由规划模块制定任务策略。
工具调用:根据任务需求,调用相应的工具模块进行数据处理。
执行任务:通过行动模块与用户进行交互,执行任务。
记忆管理:在任务执行过程中,记忆模块负责管理和存储各种记忆信息,确保对话的连贯性和一致性。
七、实际应用案例
电信运营商系统经分数据统计Agent
为了更好地理解ChatBI Agent的工作原理,我们通过一个实际应用案例来展示其具体的应用场景。
案例:电信运营商系统的经分数据统计Agent
任务需求:电信运营商需要对过去一年的用户数据进行统计分析,并生成详细报告。
任务规划:规划模块制定数据分析策略,确定数据提取、处理和分析步骤。
工具调用:调用SQL代码解释器从MySQL平台中提取用户数据,并通过Python代码解析器进行数据处理和分析。
执行任务:通过行动模块与运营商进行多轮对话,获取详细需求,并生成报告。
记忆管理:记忆模块记录和存储数据分析过程中的各种信息,确保分析结果的连贯性和准确性。
代码实现:
配置MySQL连接
config = {
‘user’: ‘user’,
‘password’: ‘password’,
‘host’: ‘localhost’,
‘database’: ‘telecom’
}
创建MySQL平台实例
mysql_platform = MySQLPlatform(config)
从数据库中提取用户数据
user_data_query = “SELECT * FROM user_data WHERE date BETWEEN ‘2023-01-01’ AND ‘2023-12-31’”
user_data = mysql_platform.query(user_data_query)
使用Python代码解析器进行数据处理和分析
python_code = “”"
import pandas as pd
def analyze_data(data):
df = pd.DataFrame(data, columns=[‘user_id’, ‘usage’, ‘date’])
report = df.groupby(‘user_id’).agg({‘usage’: ‘sum’}).reset_index()
return report.to_dict()
analyze_data(user_data)
“”"
exec(python_code)
模拟与运营商进行多轮对话
dialogue = MultiTurnDialogue()
dialogue.add_turn(“请提供过去一年的用户数据统计报告。”, “好的,我们正在处理您的请求。”)
dialogue.add_turn(“报告已生成,请查看。”, “谢谢。”)
显示对话历史
print(dialogue.get_full_dialogue())
关闭MySQL连接
mysql_platform.close()
八、总结
通过对ChatBI Agent架构的详细解析,并结合电信运营商系统的经分数据统计Agent的实际应用案例和代码实现,我们可以看到其在任务规划、工具调用、任务执行和记忆管理等方面的强大能力。该系统通过各个模块的协同工作,能够高效、准确地完成各种复杂任务,具有广泛的应用前景。希望本文能够帮助大家更好地理解和应用ChatBI Agent,为企业智能化发展提供有力支持。
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】