最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:
《大模型面试宝典》(2024版) 发布!
喜欢本文记得收藏、关注、点赞。
OpenAI o1于2024年9月13日正式发布,作为OpenAI最新发布的最强推理模型,标志着AI行业进入了一个新时代。o1在测试化学、物理和生物学专业知识的基准GPQA-diamond上,全面超过了人类博士专家,OpenAI宣称“通用人工智能(AGI)之路,已经没有任何阻碍”。
以往的大模型都是在“卷”NLP,语义理解、文本生成,而有点忽略逻辑推理。虽然GPT系列也集成了“In Context Learning(上下文学习)”、“Chain of Thought(思维链)”,但更多在Prmpt Engineering(提示词工程),目的是为了挖掘大模型的能力。这次发布OpenAI o1,开启了模型“卷”逻辑推理之路。
我一直坚信OpenAI还有很多秘密武器没有亮相,山姆·奥特曼果然是投资出身,懂得有节奏推出新产品,完美拿捏用户和投资者的情绪。每当大家觉得OpenAI快不行的时候,一个重磅炸弹丢出,大家认为他又行了,AGI又近了。-- 架构师带你玩转AI

OpenAI o1
一、OpenAI o1
什么是OpenAI o1?我们即将推出OpenAI o1,这是一种经过强化学习训练的新型大型语言模型,用于执行复杂的推理。o1在回答之前会进行思考——它可以在回应用户之前生成一个长长的内部思路链。 – Open AI 官方定义

-
强化学习训练:o1模型的核心在于其采用了强化学习的方法进行训练。这种方法使模型能够在不断试错的过程中优化其决策策略,从而提升其在复杂推理任务中的表现。
-
内部思维链生成:不同于传统的语言模型,o1在回答之前会生成一个内部的思维链。这个思路链是一个逐步推导、逐步分解问题的过程,它模拟了人类思考的方式,使得模型能够更深入地理解问题并给出更准确的答案。
-
复杂推理能力:通过强化学习和内部思维链的生成,o1在复杂推理能力上实现了显著提升。它能够在数学、编码、科学等多个领域表现出色,解决一些传统模型难以应对的复杂问题。

OpenAI o1 vs GPT-4o:为了强调在推理能力上对GPT-4o的改进,我们在一系列不同的人类考试和机器学习基准测试中测试了我们的模型。我们证明了o1在绝大多数推理密集型任务上显著优于GPT-4o。除非另有说明,否则我们对o1的评估采用最大测试时间计算设置。 – Open AI 官方Evals

在具有挑战性的推理基准测试中,o1相对于GPT-4o有了大幅提升。实线条表示“一次通过”(pass@1)的准确性,而阴影区域则表示64个样本中的多数投票(共识)表现。
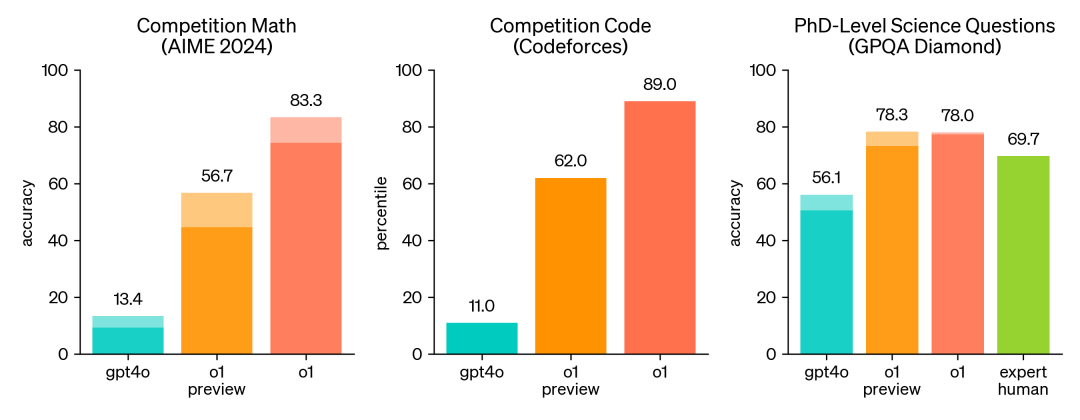
Benchmark测评结果:o1在多个高难度推理基准测试中表现出色,包括超越人类专家和GPT-4o,展示了其强大的推理能力和在某些领域的专业知识。
在许多需要大量推理的基准测试中,o1的表现与人类专家不相上下。最近的前沿模型1在MATH2和GSM8K上的表现非常出色,以至于这些基准测试已无法有效区分不同模型。我们评估了AIME上的数学表现,AIME是一项旨在挑战美国最优秀高中生的数学考试。在2024年的AIME考试中,GPT-4o平均只能解决12%(1.8/15)的问题。而o1在每个问题上使用一个样本平均解决了74%(11.1/15)的问题,使用64个样本的共识解决了83%(12.5/15)的问题,并使用学习到的评分函数对1000个样本进行重新排序后解决了93%(13.9/15)的问题。13.9的分数使其位列全国前500名学生之列,并超过了美国数学奥林匹克竞赛的入围分数线。 – Open AI 官方测评结果
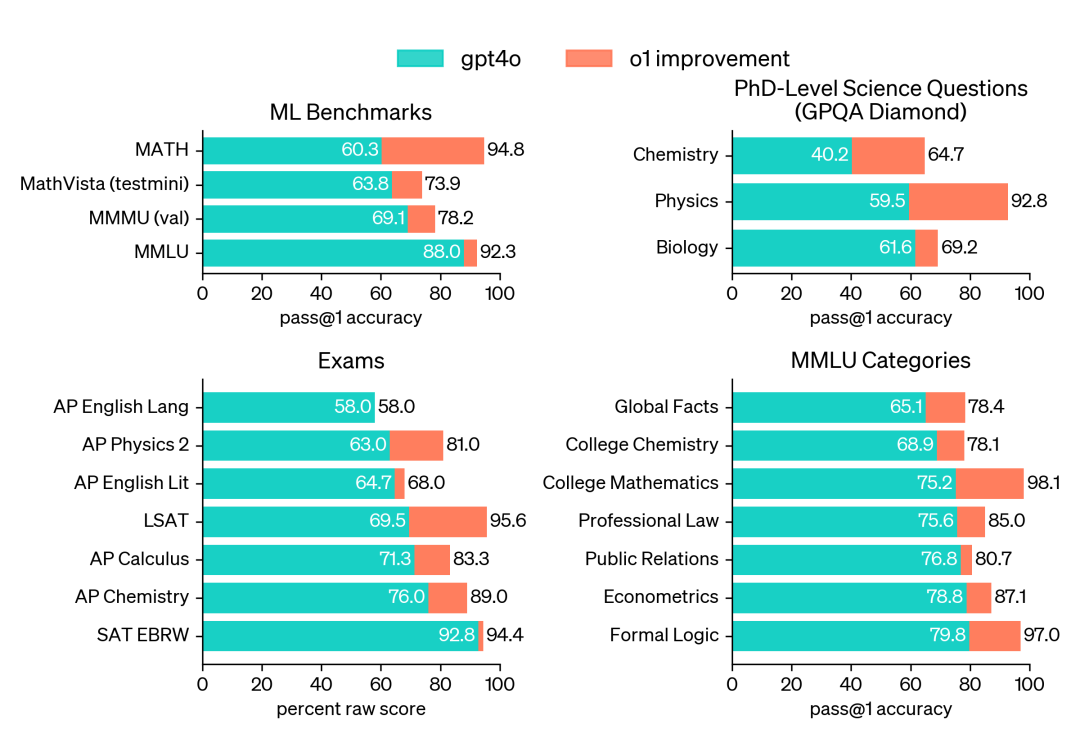
我们还在GPQA钻石上评估了o1,这是一个测试化学、物理和生物学专业知识的困难智能基准测试。为了将模型与人类进行比较,我们招募了拥有博士学位的专家来回答GPQA钻石问题。我们发现,o1的表现超过了这些人类专家,成为首个在该基准测试中做到这一点的模型。这些结果并不意味着o1在所有方面都比拥有博士学位的人更强大——而只是表明该模型在解决一些博士学位获得者预期会解决的问题上更为熟练。在其他一些机器学习基准测试中,o1也超过了最先进的模型。启用视觉感知能力后,o1在MMMU上获得了78.2%的分数,成为首个与人类专家具有竞争力的模型。同时,在MMLU的57个子类别中,o1有54个的表现优于GPT-4o。 – Open AI 官方测评结果

o1在包括54/57个MMLU子类别在内的广泛基准测试中表现优于GPT-4o。这里展示了七个作为示例。
二、思维链 + 强化学习
Chain of Thought(思维链):与人类在回答难题前可能需要长时间思考类似,o1在尝试解决问题时会使用一系列的思考过程。通过强化学习,o1学会了优化其思考过程并改进其使用的策略。它学会了识别和纠正自己的错误,将复杂的步骤分解成更简单的步骤,并在当前方法不起作用时尝试不同的方法。这个过程极大地提高了模型的推理能力。为了说明这一飞跃,我们展示了o1预览版在几个难题上的思考过程。 – Open AI 官方Chain of Thought

OpenAI o1的技术细节如何解读?OpenAI 从GPT3开始转向闭源,很多技术细节都没有公布,OpenAI o1这次也不例外,网上很多人反馈想通过使用o1一步步去debug它的Chain of Thought(思维链),从而去了解o1的思维链思考过程,结果被封号了。
OpenAI o1官方公布的技术概念:Reinforcement Learning(强化学习)、Chain of Thought(CoT,思维链)、Post-training(后训练),这些都不是新技术,但是OpenAI强就强在如何将这些已有技术进行排列组合,进行技术创新,进行灵活应用。我预测未来一段时间,各大模型厂商又会开启新的一轮庖丁解牛,进行你追我赶。-- 架构师带你玩转AI


















