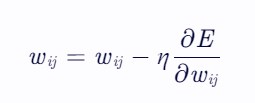前言:
我整体的学习顺序是看的按B站那“唯一”的三维点云的视频学习的(翻了好久几乎没有第二个...)对于深度学习部分,由于本人并没有进行学习,所以没有深究。大多数内容都进行了自己的理解并找了很多网络的资源方便理解,总体而言还是很多不同的。(加粗是重点)
一、概述
想象你站在一片茂密的森林中,四周是参天的树木、错综复杂的藤蔓和散落在地上的落叶。闭上眼睛,去感受周围每一棵树、每一片叶子的具体位置和形状。现在,把你的感受数字化(把你的想象“复制”到电脑里),形成一个由无数个点组成的三维模型,这就是三维点云。你想的和下面是不是一样呢?

简单来说,三维点云是一组在三维空间中带有坐标的点的集合。每一个点都代表了物体表面空间中的一个位置(x,y,z)。通过积累足够多的点,我们可以近似重建出物体的外形或整个场景的结构。点云数据是通过激光扫描仪、深度相机、雷达(LiDAR)等传感器采集的,每个点不仅包含位置信息,某些情况下,还包括颜色、密度、法线等附加属性。
三维点云的应用场景非常广泛,从我们熟悉的电影特效、游戏开发,到更严谨的科学领域如无人驾驶、建筑、考古、医学影像,几乎都能看到点云技术的身影。例如,在无人驾驶汽车中,LiDAR传感器生成的点云帮助车辆感知周围环境,识别行人、障碍物和道路特征,从而做出决策。
在建筑和城市规划中,点云技术被用来扫描建筑物或地形,精确地记录下它们的三维结构,生成数字模型。这些模型不仅能用于设计,还能帮助检测建筑物的老化或损坏,甚至可以用于虚拟现实(VR)中的沉浸式体验。
三维点云的特点如下:
-
数据量大且稀疏:点云虽然能精确描述物体的表面形状,但它并不像图像那样连续。它由离散的点构成,因此数据量通常非常庞大,尤其是高精度的扫描。每一个点都要记录三维坐标,甚至附加参数,导致存储和处理的复杂度较高。并且满足近距离密集远距离稀疏的趋势。
-
无拓扑结构:与常见的网格模型(如多边形网格)不同,点云并没有面与面的连接关系。它们是独立存在的点,缺乏明确的几何拓扑信息。因此,处理点云时,常常需要通过算法去推断点与点之间的关系,进而重建物体的曲面或结构。
-
高灵活性:点云数据可以适应各种形状和复杂结构,不受特定几何形状的限制。无论是有机形态的雕塑、建筑物的复杂外形,还是自然环境中的岩石树木,点云都能灵活地捕捉和表示。
-
无序性:点云数据中的点没有固定的顺序。为了更好地理解这一点,我们可以将三维点云比作一个点的集合,其中每个点都有自己的标签(即三维坐标)。在这个集合中,点的排列顺序是无关紧要的,因为每个点的标签已经明确了它的位置和深度信息。无论我们如何重新排列这些点,只要它们的标签保持不变,点云所代表的三维空间结构就不会改变。(注意:这里我的看法和有些老师说的不太一样,我的理解是,点云中的点是没办法互换的,因为点云数据中的坐标等信息把这个点“定死了”,无序性是指在三维点云数据的文本文件(如txt格式)中,点的顺序是没有要求的!!)
-
非结构性:点云数据不像二维图像那样可以自然地组织成矩阵形式。这种非结构性使得直接将点云数据输入到传统的神经网络中变得困难,需要特殊的处理方法来提取和利用点云数据中的有用信息。
其实在之前SLAM的学习中就接触过点云,在ch5的介绍相机的时候我们介绍过一些相机,比如双目相机和RGB-D的相机都可以制作出点云数据。但是在实际的点云应用中,我们最常用的就是激光雷达,他们都可以得到点的三维坐标xyz,但是有着一些区别的(从现在的电车就可以看出来,加上激光雷达的一般都要比纯相机的贵!!),相机与激光雷达(LiDAR)对比分析表如下:
| 对比项 | 相机(含双目、RGB-D、结构光) | 激光雷达(LiDAR) |
|---|---|---|
| 工作原理 | 利用成像原理,通过计算不同视角的视差来获取深度信息 | 发射激光并测量反射光的时间差来计算距离 |
| 输出数据 | 彩色图像和深度图像 | 点云数据 |
| 精度 | 受成像质量、算法复杂度等因素影响 | 高精度,直接输出空间坐标 |
| 环境适应性 | 受光照条件、纹理等因素影响较大 | 光照条件和纹理对其影响较小 |
| 成本 | 相对较低,尤其是单目相机 | 相对较高,尤其是高线数机械式LiDAR |
| 视野(FOV) | 相对较小,受镜头和传感器尺寸限制 | 较大,尤其是固态LiDAR |
| 实时性 | 受图像处理算法复杂度影响 | 实时性较好 |
| 应用场景 | 适用于室内、近距离、高精度场景 | 适用于室外、远距离、大场景 |
思考一下:我们为什么需要点云数据?与我们日常的图像和视频这种形式的数据有什么区别?
如果你正站在一座雄伟的山峰脚下,四周是连绵起伏的山脉,蓝天白云下,山峦的轮廓清晰可见。如果你用相机拍下这一刻,你会得到一张精美的照片,记录了眼前的美景。但这张照片只是一个二维的投影,它无法告诉你山峰的实际高度、坡度或地形的具体特征。
然而,如果我们使用三维点云技术,情况就完全不同了。点云数据就像是用无数个微小的“光点”来描绘这个世界。每个点都有三个坐标值(x, y, z),这些点共同构成了一个立体的、多维的模型。通过点云数据,我们可以精确地测量山峰的高度、计算山坡的坡度、甚至重建整个山体的地形。这种详细而精确的信息,是传统的二维图像所无法提供的。也就是说三维的点云可以带给我们更多的信息!!这其实也变相的说明了为什么带有激光雷达的电车会越来越受欢迎,因为激光雷达可以不受外界影响(如夜间、强光直射时)地带给我们更多的信息,并且可以以一种更为直观的方式描述它所“看到的”世界。
我知道你可能又要问,我们摄影测量学或者在SLAM里面可能学到过用两张或多张照片来确定深度,为什么不用这种方法?其实很好理解的吧~ 我们通过照片来计算深度和用激光雷达直接测量出深度,这两个的计算量显而易见了吧(一个要疯狂的计算一个直接得出来了...计算推导我在SLAM的博客ch5里面有写到)....而且计算的深度可能会受到环境的影响,误差可能会比激光雷达大那么一丢丢(所以这就是为什么好的辅助驾驶电车都用激光雷达的原因!)。而且目前的摄影测量现在更趋向于无人机进行作业,这也侧向的表明了摄影测量学正朝着利用三维点云技术的方向发展,以实现更高效、更精确和更多样化的测量和建模应用。

1.1.点云分割
下面的图中左边是点云图像(类似于真实世界),右边是点云的分割。

点云可以用来表示任何三维物体或场景,从简单的桌子到复杂的城市街区(就像我们最开始的那个图象一样)。
但是,仅仅拥有这幅点云“画”还不够。我们还需要能够从中提取出有用的信息,比如区分出哪些点属于“桌子”,哪些点属于“椅子”,哪些点属于“地板”。这就需要用到一种技术——点云分割。(如下图所示)

什么是点云分割?
点云分割,就是将一个大的点云数据集划分为多个有意义的部分或区域。每个部分代表一个特定的对象或表面。通过点云分割,我们可以更清晰地理解点云中的不同元素,从而更好地进行后续的分析和处理。简单来说,就是把一堆乱七八糟的点,按照某种规律或者特征,分成一个个有意义的小团体。这些点可能来自一辆车、一棵树或者一座房子,它们在三维空间中形成了一个复杂的点云。
对于图像而言,我们需要逐像素点进行判断(比如电车的纯视觉方案,就是判断哪个是建筑物,哪个是行人.....)。对于点云需要逐点(坐标)进行判断所属的类型。
为什么需要点云分割?
1.对象识别:
在现在的电车中,点云分割可以帮助系统识别出道路上的行人、车辆、交通标志等,从而做出正确的驾驶决策。(因为在设计算法时对于道路、车和行人的“躲避权重”是不一样的,所以需要进行点云分割)
2.环境建模:
在建筑和城市规划中,点云分割可以将复杂的场景分解为不同的建筑、道路和绿地,帮助设计师更有效地进行规划和设计。

3.数据简化:
大量的点云数据处理起来非常耗时,通过分割可以将数据简化,减少计算负担,提高处理效率。
点云分割的方法
点云分割有多种方法,每种方法都有其特点和适用场景。下面介绍几种常见的点云分割技术:
1.基于几何特征的分割:
这种方法利用点云中的几何特征(如曲率、法线方向等)来划分不同的区域。例如,平坦的地面和弯曲的物体表面会有不同的几何特征,通过这些特征可以将它们区分开来。
2.基于聚类的分割:
聚类算法(如K-means、DBSCAN)可以根据点之间的距离和密度将点云分成多个簇。每个簇代表一个独立的对象或表面。这种方法适用于没有明显几何特征的场景。
想象一下,你在一个大公园里,里面有各种各样的人:有的在跑步,有的在散步,还有的在野餐。如果我们要把这些人分成不同的小组,我们会怎么分呢?很自然地,我们会把正在做同样活动的人分在一起。跑步的是一组,散步的是一组,野餐的也是一组。这就是聚类的基本思想:把相似的点放在一起,形成一个个小团体。
在点云分割的世界里,聚类算法就像是一个聪明的leader,它可以根据点之间的距离和密度,自动地将点云分成多个簇。每个簇就像是一个独立的小团体,代表了一个特定的对象或表面。在点云分割中,聚类算法可以帮助我们从一堆混乱的点中,找出那些具有相似特征的点,并将它们归为一类。这种方法特别适用于那些没有明显几何特征的场景,因为在这些场景中,传统的基于形状或边缘的分割方法可能不太适用。
拓展:K-means和DBSCAN:两种流行的聚类算法(了解即可)
1.K-means:这个算法就像是在公园里设定几个固定的聚会点。首先,我们随机选择几个点作为初始的聚会中心。然后,每个点都会去找离自己最近的聚会中心,并加入那个小组。接着,我们更新每个小组的中心位置(新的簇中心位置是通过计算簇内所有点的均值来确定的),然后再次分配点。这个过程反复进行,直到每个点都找到了自己的小组,且小组的中心位置不再发生变化。
2.DBSCAN:与K-means不同,DBSCAN更像是一个自由流动的聚会。它不需要预先设定小组的数量,而是根据点的密度来自动形成小组。如果一个点周围有足够的邻居,它就会成为一个新小组的核心。然后,这个小组会逐渐扩大,包括所有密度相连的点。结果就是,密集的区域形成了紧密的小组,而稀疏的区域则被划分为噪声。
——————————分割线——————————
3.基于深度学习的分割:
随着深度学习技术的发展,基于神经网络的点云分割方法越来越流行。这些方法通过训练大量的点云数据,学习如何自动识别和分割不同的对象。这种方法在复杂场景中表现出色,但需要大量的标注数据和计算资源。
4.基于图割的分割:
图割算法将点云视为一个图,每个点是一个节点,点之间的相似性作为边的权重。通过最小化图的切割成本,可以将点云分割成不同的区域。这种方法在处理边界清晰的物体时效果很好。
实际应用案例
假设你是一名城市规划师,正在使用点云数据来设计一个新的公园。通过点云分割,你可以将公园中的树木、草地、步道和建筑等不同元素区分开来。这样,你就可以更方便地进行景观设计,确保每个区域的功能和美观性。
又比如,你是一名自动驾驶工程师,需要开发一个系统来识别道路上的各种障碍物。通过点云分割,你可以将行人、车辆、交通标志等不同对象区分开来,从而确保汽车能够安全地行驶。
1.2.点云补全与生成
点云补全是通过算法预测和填补点云数据中缺失的部分(扫描的点总会有缺失的部分,从上面那些图也可以看出来),使点云模型更加完整和连续。在实际应用中,由于传感器的限制、遮挡物的存在或数据传输的丢失,点云数据常常会出现缺失或不完整的情况。点云补全技术可以帮助我们恢复这些缺失的部分,使点云模型更加准确和完整。

那为什么要补全呢?还是拿我本人喜欢的电车举例吧!假如我们是某电车的辅助驾驶工程师,需要处理来自激光雷达的点云数据。由于车辆行驶过程中可能会遇到遮挡物,导致某些区域的数据缺失。通过点云补全,我们就可以恢复这些缺失的数据,提高系统的环境感知能力,确保自动驾驶的安全性。目前补全方法的发展趋势更趋向于结合深度学习进行点云的补全。(类似于AI换脸或修复一些老照片)
点云生成是指通过各种传感器和技术手段,将现实世界中的物体或场景转换为一系列三维点的过程。每个点在空间中都有一个精确的位置(x, y, z 坐标),这些点共同构成了一个三维模型,即点云。

1.3.点云的物体检测
依旧!拿我熟悉的电车举例^ . ^!在无人或辅助驾驶汽车中,点云物体检测是实现环境感知的关键技术之一。激光雷达(LiDAR)传感器发射激光脉冲并接收反射回来的光,以此来测量车辆周围物体的距离和位置,生成点云数据。这些点云数据包含了丰富的三维空间信息,是无人驾驶汽车“看”世界的眼睛。


点云物体检测的成功实施对于无人驾驶汽车的安全性和可靠性至关重要。它不仅帮助车辆避免碰撞,还能够提高导航和路径规划的效率,确保乘客的舒适体验。点云的物体检测也是如今点云研究的热门方向之一。
1.4.点云配准
点云配准是指将多个不同视角或不同时间获取的点云数据对齐,使它们在同一个坐标系下形成一个完整的三维模型。简单来说,就是将多个部分拼接在一起,使它们无缝对接,成为一个整体。
单独的点云数据通常只能覆盖场景的一部分。通过点云配准,可以将多个部分拼接在一起,形成一个完整的三维模型。这对于大型场景的建模尤为重要,如建筑物、城市街区等。比如百度地图的实景地图,它通过安装在车辆上的激光雷达设备,可以高速扫描周围环境,从而生成高密度的点云数据,由于车在一直运动,所以在拼接之前需要做配准工作(找好图中同一地物的对应关系后进行对齐)。

1.5.点云的特征提取
手中握有一个充满无数点的三维点云数据,这些点共同构成了一个复杂的三维模型。如何从这些海量数据中提取出有用的信息,以便进行进一步的分析和处理呢?这就需要进行点云的特征提取。
点云特征提取是指从点云数据中提取出具有代表性和区分性的特征,以便进行后续的处理和分析。这些特征可以是几何特征(如曲率、法线方向)、统计特征(如点密度、分布)或其他高级特征(如局部形状描述符)。通过特征提取,可以将原始的点云数据转换为更紧凑、更有意义的表示形式,从而提高处理效率和准确性。
二、3D点云和一个经典网路——PointNet
通过传感器扫描(比如百度实景地图的扫描车、无人驾驶车上面旋转的传感器)得到了点云数据。

如果我们用记事本打开点云的.txt文件的话,会发现大量的点数据,其中会包含三个维度xyz的坐标还有额外特征(法向量信息,提供了每个点所在平面在三维空间中的朝向或倾斜角度。也就是说我们知道了法向量就可以知道点所在的平面了)
PS:理解“点的朝向和倾斜”
理解点云中的法向量概念时,关键是要明白我们并不是在讨论单个孤立点的朝向或倾斜,而是讨论该点所在的局部表面的朝向或倾斜。点云数据本质上是对一个连续表面的离散采样,每个点代表了该表面上的一个采样点。因此,每个点的法向量实际上是描述了该点所在的小区域(局部表面)的朝向。
比如一个球体。球体表面的每个点都有一个法向量,指向球体的外部。这些法向量告诉我们每个点所在的局部表面是朝哪个方向的。即使每个点本身没有朝向,但它所在的局部表面有朝向。

2.1.PointNet
PointNet 是一种用于处理点云数据的深度学习模型。点云是由大量三维空间中的点组成的集合,这些点可以来自激光雷达扫描、3D相机等设备。在传统的计算机视觉中,我们通常处理的是二维图像,而PointNet则是专门设计来直接处理这种三维点云数据的。
2.1.1.PointNet能做什么?
PointNet 可以用来完成三种主要任务:
1.Classification(分类):
这个任务的目标是识别整个点云属于哪一类对象。比如,给定一个汽车的点云数据,PointNet 能够判断出这是一个“汽车”。
2.Part Segmentation(部件分割):
在这个任务中,PointNet 不仅要识别物体的整体类别,还要将物体的不同部分区分开来。例如,对于一把椅子,它可以区分出椅背、椅座和椅腿。
3.Semantic Segmentation(语义分割):
与部件分割类似,但语义分割是在更大的场景中操作,目的是将场景中的每个点标记为特定类别的标签。这可以应用于室内或室外环境,例如,识别出哪些点代表地面,哪些点代表建筑物,哪些点代表行人等。

2.1.2.PointNet的工作原理简述
PointNet 的核心思想是对输入的点云数据中的每个点独立地应用多层感知机(MLP),然后通过一个对称函数(如最大池化)汇总所有点的信息,从而获得整个点云的特征表示。这种设计使得模型能够处理无序的点集,并且具有一定的旋转和平移不变性。
想象你有一堆散落在桌面上的小珠子,这些小珠子代表了三维空间中的点,也就是点云数据。PointNet 的任务就是从这些小珠子中提取有用的信息,来识别出它们代表的对象,或者区分出对象的不同部分。
1. 处理每个点
- 多层感知机 (MLP):PointNet 会对每个小珠子单独进行分析,就像你用放大镜仔细观察每个小珠子一样。它会计算出每个小珠子的位置、颜色、形状等特征。这一步就像是给每个小珠子打上标签,记录下它的各种属性。
2. 汇总信息
- 对称函数(最大池化):处理完所有的小珠子后,PointNet 需要把这些信息汇总起来,形成对整个对象的理解。给出的例子用到的方法叫“最大池化”。简单来说,就是从所有小珠子的特征中挑出最显著的那些。比如,如果大部分小珠子都是红色的,那么“最大池化”就会认为这个对象的主要特征是“红色”。
3. 输出结果
- 分类:如果任务是识别这个对象是什么,PointNet 会根据汇总的信息判断出这是一个“苹果”还是一个“橙子”。
- 部件分割:如果任务是区分对象的不同部分,PointNet 会告诉你是哪些小珠子组成了“果皮”,哪些小珠子组成了“果肉”。
- 语义分割:如果任务是在一个更大的场景中识别不同的物体,比如在一个房间里,PointNet 会告诉你哪些小珠子代表“地板”,哪些小珠子代表“桌子”,哪些小珠子代表“椅子”。
2.2.基本出发点
1. 无序性
点云数据的一个重要特点是无序性。这意味着,点云中的点没有固定的顺序,可以随意排列。例如,一个包含100个点的点云,这100个点可以以任意顺序出现,但它们代表的物体不会因此改变。所以在我们求“最大值”的时候,它的置换不变性(打乱顺序不影响运算)这一个特性就显现出来了。
然后我们需要做什么?直接求最大值可以吗?当然不行!!!!那么多点就用一个最大值代替了也太不合理了吧!比如1000个三维向量取最大值最后浓缩的也是一个三维向量,相当于3000个特征最后用三个特征代替了...这损失的特征有点多啊。
怎么理解呢?这样看,每个三维向量有3个特征,分别对应于x、y、z三个坐标轴上的位置。然而,这些特征并不是可以相互替代的类别,而是共同构成了一个点在三维空间中的精确位置。直接用一个向量的最大值来代替所有向量,意味着只保留了每个坐标轴上的最大位置信息,而忽略了其他所有点的位置信息。
在三维空间中,每个点的位置都是独一无二的,它们共同构成了点云的形状和结构。如果我们只用最大值来代表整个点云,那么点云中的大部分细节和形状信息就会丢失。例如,一个球体和一个立方体的点云在取最大值后可能会得到相同的三维向量,因为它们在每个坐标轴上的最大值可能是相同的,但显然这两个形状是完全不同的。这下你肯定理解了吧!!!!!!
接下来,我们需要做的是在保持置换不变性的前提下,有效地聚合点云中所有点的特征,以便捕捉到整个点云的全局信息。直接求最大值虽然具有置换不变性,但它只能保留最大值对应的特征,而忽略了其他点的特征,这显然不足以代表整个点云。那我们做一个升维不就可以了吗?(一维:多个点的特征取最大值用一个特征代替,多维:这些点可以取多个特征)
而实际上就是如此,通过一个权重矩阵来提升维度。你肯定好奇这个矩阵是怎么来的吧,提前简单了解一下:
权重矩阵W1如何得到?(了解)
权重矩阵 W1 的作用是将每个点的低维特征(例如3维坐标 x,y,z)映射到高维特征空间。具体来说,假设每个点的初始特征是3维的,我们希望将其映射到64维的特征空间,那么 W1 就是一个 3×64的矩阵。


通过上述训练过程,权重矩阵 W1 会被逐步调整,最终学会如何将低维特征映射到高维特征,从而提高模型的性能。总体就是计算机通过不断的“试错”选择出损失最小的答案,或许这就是为什么叫“机器”学习的原因吧!
你或许又有一个小疑问:
什么是Relu?
ReLU 的计算简单,不需要复杂的数学运算,适合大规模数据的快速处理。

2. 对称函数
为了处理这种无序性,PointNet 使用了一个对称函数。对称函数的一个关键特性是,无论输入的顺序如何,输出都是一样的。最常见的对称函数是最大池化(Max Pooling)。也就是说分别对每个特征进行特征提取(卷积或全连接MLP),然后再最大池化(MAX)得到全局输出。随后依据这些特征进行分类的任务即可。
我们上面升维的过程就是MLP感知机。(其实后面输出k分类的降维<全连接层FC>也用到这个了!区别就只有一个,MLP的激活函数是ReLU,全连接层的激活函数是softmax)
2.3.网络架构(加粗是重点)

输入数据是一个点云 P,其中包含 n 个点,每个点有 d 维特征(通常是3维坐标 x,y,z,但在某些数据集中可能更多)。为了处理不同类别的点云数据,通常会固定一个采样点个数 n,这样输入数据的形状为 n×d。接下来,对这 n 个点进行升维操作,通过一个多层感知机(MLP)将每个点的低维特征映射到高维特征。例如,从3维特征升至64维,这一阶段的MLP可以表示为 hi=ReLU(W1pi+b1),其中 W1 是一个 d×64 的矩阵,b1 是一个64维的向量。经过这一操作,每个点的特征变为64维,输出的形状为 n×64。接着,继续使用MLP对特征进行进一步提取和转换,例如,从64维升至128维,再从128维升至1024维。经过这一系列操作,每个点的特征最终变为1024维,输出的形状为 n×1024。然后,使用最大池化函数对所有点的特征进行汇总,提取出全局特征。最大池化函数的作用是从所有点的特征中选出每个维度的最大值,形成一个全局特征向量,最终得到的全局特征向量的形状为 1×1024。最后,使用一个全连接层(FC)加上 softmax 函数来输出类别概率(k分类)。这一阶段的全连接层可以表示为 y=softmax(W4g+b4),其中 W4 是一个 1024×k 的矩阵,b4 是一个 k维的向量,k 是类别数量。输出的形状为 1×k,表示每个类别的概率。
上图中还提到了分割任务,分割任务的目标是为点云中的每个点分配一个类别标签。在前面的特征提取过程中,我们已经得到了每个点的64维局部特征和1024维全局特征。具体来说,64维特征表示每个点的局部信息,而1024维全局特征表示整个点云的全局信息。为了充分利用这两种特征,PointNet进行了以下操作:首先,将每个点的64维局部特征与1024维全局特征进行拼接。拼接操作将每个点的局部特征和全局特征结合起来,形成一个更高维的特征向量。具体来说,64维局部特征和1024维全局特征拼接后,每个点的特征维度变为1088维,形状为 n×1088。这样,每个点不仅保留了自己的局部特征,还包含了全局特征,从而能够更好地捕捉点云的整体结构和局部细节。接下来,拼接后的特征向量通过一个MLP进行进一步处理,将1088维特征降维到128维。经过这一操作,每个点的特征维度变为128维,形状为 n×128。这一阶段的MLP有助于提取更高级的特征,同时减少特征的维度,降低后续计算的复杂度。最后,继续使用另一个MLP将128维特征进一步降维到 m 维,其中 m 是分割任务中类别的数量。经过这一操作,每个点的特征维度变为 m 维,形状为 n×m。这一阶段的MLP将特征映射到每个类别的概率分布(这一步就是在告诉我每个点属于m个类别中的哪一类!),最终输出每个点的分割结果。
PS:relu和softmax函数的区别
| 函数类型 | 用途 | 定义 | 输出范围 | 主要作用 |
|---|---|---|---|---|
| Softmax函数 | 输出层,多分类问题 | 将原始分数转换为概率分布 | (0, 1) | 将分数转换为概率,使得输出可解释为类别的预测概率(k分类) |
| ReLU激活函数 | 隐藏层 | f(x) = max(0, x) | [0, ∞) | 引入非线性,缓解梯度消失问题,提高训练速度 |
2.4.PointNet++
我们在上面的整个过程中可以发现PointNet的许多问题,比如其中的每个点都缺少了相互之间的联系,只在最后“强硬的”融合了一下全局特征,点与点之间貌似没什么关联,这个结构从某种程度上来说有点不太符合主流了。所以PointNet++这个新版本就修复了这个Bug。

现在啊,每个点在PointNet++中就不再孤立了,而是通过局部邻域的划分和特征提取,形成了更强的关联性。具体来说,PointNet++ 首先将点云划分为多个局部邻域,每个邻域中包含许多邻近的点(也就是把差不多的点分到一块了)。在每个局部邻域内,提取该局部邻域的特征(卷积)(诶!!正好!卷积不就是分块提取特征吗!!)。这样,每个局部邻域的特征既包含了该区域内点的局部信息,也通过最大池化提取了该区域的全局信息。通过多层次的特征提取和聚合,PointNet++ 能够捕捉不同尺度的局部结构。较低层次的特征表示关注较小范围内的局部细节,较高层次的特征表示关注较大范围内的全局结构。
与之前的PointNet相比,PointNet++ 的不同之处在于,之前的模型是“单打独斗”,即每个点的特征是独立提取的,而PointNet++ 则是“抱团取暖”。通过在局部邻域内进行特征提取,点和点之间形成了更强的关联性。这种设计使得模型能够更好地理解和捕捉点云的复杂结构和局部细节。
思考:范围如何选定?(圈在哪画?)
从点云中均匀采样,选择一些点作为局部邻域的中心点。例如,可以使用FPS(最远点采样) 方法,从点云中选择一定数量的点,这些点尽可能均匀地分布在点云中。至于半径,我们可以预先设定一个固定的半径值。例如,可以选择一个合适的半径 r,使得每个局部邻域包含一定数量的点。这个半径可以根据点云的密度和任务需求来调整。
2.5.FPS最远点采样
选取了一个知乎上面的解释,浅显易懂。

PointNet++ 中的分组方法
-
基于半径的分组:这是PointNet++ 中最常用的方法之一。选择一个中心点后,在这个中心点周围定义一个球形区域(半径为r),然后将这个球内的所有点归为一组。如果在这个球内点的数量少于预设值,则可以选择最近的点来填充,确保每组有相同的点数。这种方法的好处是能够捕捉到不同密度区域的信息。若多于预设值,则先按各点到中心点的距离进行排序后排除掉最远的几个点。
-
基于k近邻的分组:另一种方法是在给定一个中心点后,找到距离该点最近的k个点,将这k+1个点(包括中心点本身)作为一组。这种方法的优点是可以动态调整每组的大小,适应不同密度的点云。
也就是说,比如我们输入一批数据(视频中的batch意思就是在单次迭代中模型所处理的数据量,如果 batch size 设置为32,那么 batch*1024 就意味着每次迭代处理32个批次,共计32 * 1024 = 32768个样本。)共1024个,每个点有6个特征(xyz和对应法向量信息)。假如我们要分128个中心点,每个组中有16个样本,最后输出结果就是128*16*6。我们也可以根据实际情况选择多种半径和样本点个数,以便特征更加丰富(把不同半径提取出来的特征拼接到一块而不是同时选择多个半径)。
什么是卷积?
卷积核在输入图像上滑动,每次覆盖一个小区域(通常称为“感受野”)。对于每个位置,卷积核与该区域的像素值进行逐元素乘法,并将结果相加,得到一个输出值。这个过程可以想象成一个“滑动窗口”,在图像上移动并计算每个位置的响应。

在遥感图像处理中我们学到过,通道是指图像的一个维度。对于灰度图像,只有一个通道(即灰度值)。对于彩色图像,通常有三个通道(红、绿、蓝,简称RGB)。每个通道可以看作是一个独立的二维矩阵。 在三维点云中,点的信息通常包括xyz三维坐标还有其对应的法向量这6个元素,所以在三维点云的通道数值通常为6.
卷积是如何进行特征提取的?
1. 输入数据
假设我们有一个输入图像,这个图像有6个不同的通道(比如6种不同类型的传感器数据)。每个通道可以看作是一个二维矩阵,矩阵的大小是图像的高度和宽度,如(28,28,6),分别对应长宽和通道数。
2. 卷积核
卷积核(也叫滤波器)是一些小的二维矩阵,它们的大小通常比输入图像小得多(例如3x3或5x5)。每个卷积核也有6个通道,与输入图像的6个通道相对应。
3. 卷积操作
卷积操作就是用卷积核在输入图像上滑动,每到一个位置就进行以下操作:
- 对齐:将卷积核与输入图像的一个局部区域对齐。
- 逐元素乘法:卷积核中的每个元素与对齐的输入图像局部区域中的对应元素相乘。
- 求和:将所有乘法结果相加,得到一个单一的数值。若为多通道还需要将各通道对应值求和。
- 移动:将卷积核移动到下一个位置,重复上述操作。

4. 特征图
每个卷积核会生成一个特征图。特征图是一个二维矩阵,记录了卷积核在输入图像上滑动时生成的所有数值。每个特征图可以看作是对输入图像的一种特定特征的响应。而每个簇中点不唯一(比如上面的16个点),也就是说卷积过后每个簇中会得到对应的值(16个),需要MAX操作来得到特征。
5. 多个卷积核
为了提取更多的特征,我们可以使用多个卷积核。假设我们使用64个卷积核,每个卷积核都会生成一个特征图。这样,我们最终会得到64个特征图,每个特征图都捕捉了输入图像的不同特征。
6. 输出
最终的输出是一个三维数据,其形状为 (高度, 宽度, 64)。这里的64表示有64个特征图,每个特征图都有自己的高度和宽度。
结合上面的采样方法,我们也可以进行分组采样,也就是说我们可以分别对不同半径进行特征提取,只不过多了一步最后的特征拼接,也就是把不同中心点得到的特征拼到一起(MSG)。
输出后我们可以进行很多操作,比如可以在此连接一次全连接层进行k分类,还可以进行几次上采样(一种插值,权重参数由距离决定,距离越远权重越小,也就是影响越小)变回到原来的量(如128->1024个),随后针对每个点进行全连接,输出各个类别的可能性。

2.6.Cloudcompare点云分割
上面我们介绍的是深度学习的方法进行点云分割,但是呢...可能深度学习并不适用于所有的人(而且...这些东西学起来好像不简单...有点复杂),比如你只想简单的处理一些简单的数据,就没必要搭建一个复杂的网络了。所以下面就是不用深度学习的方法,利用cc软件进行分割。步骤如下:
1. 加载点云数据
- 选择
File->Open或者直接点击工具栏上的打开图标,选择并加载你的点云文件(如 .las, .ply, .e57 等格式)。
2. 预览点云
- 加载后,点云数据会在主窗口中显示。你可以使用鼠标进行缩放、旋转和平移来查看数据。
3. 选择分割工具
- 在菜单中选择
Tools->Segmentation。或者,也可以使用工具栏上的分割工具图标(像一把剪刀)。
4. 选择分割方法
-
手动分割:
- 点击并拖动鼠标在点云上画出你想要分割的区域。释放鼠标按钮后,选中的部分会成为一个新的点云子集。
手动分割我找到一个视频,讲述很清晰
CloudCompare点云手动分割与加标签_哔哩哔哩_bilibili简单介绍cloud compare进行手动分割和加标签,感谢三联,同时欢迎私信交流!!!, 视频播放量 13759、弹幕量 1、点赞数 270、投硬币枚数 178、收藏人数 485、转发人数 121, 视频作者 爱吃橙子的助手, 作者简介 博士在读,摄影小白,不定期分享专业相关视频,,相关视频:CloudCompare入门教程-双语字幕,三维点云课程 超级详细,自制CloudCompare点云处理从入门到精通,CloudCompare 使用点云构建数字高程模型,CloudCompare教学(中英字幕),基于cloudcompare对点云与模型的偏差分析,Segment Any Point Cloud:运用视觉基础模型分割一切点云,3D点云标注,如何在 CloudCompare 中快速对齐和合并两个点云模型,点云入门处理与实战(Open3D)——表面重建![]() https://www.bilibili.com/video/BV14G4y1r7rz/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109
https://www.bilibili.com/video/BV14G4y1r7rz/?spm_id_from=333.337.search-card.all.click&vd_source=033a75d9cfb0b0df5347cafb8b033109
-
使用形状分割:
- 选择形状(如矩形、圆形或多边形)来框选区域。点击并拖动鼠标定义形状,松开后,形状内的点云会被选中。
-
自动分割(如使用法向量或平面检测):
- 选择
Tools->Segmentation->...,然后选择一个算法,比如Label Connected Comp(将点云分组,并基于分组结果以最小距离分割为独立的点云簇)、Cross Section、Extract Sections。根据选择的算法,调整参数来进行分割。
- 选择
官方文档如下:
CloudCompareWiki![]() https://www.cloudcompare.org/doc/wiki/index.php/Main_Page个别博主的相关介绍:
https://www.cloudcompare.org/doc/wiki/index.php/Main_Page个别博主的相关介绍:
CloudCompare功能介绍-Cross Section-CSDN博客![]() https://blog.csdn.net/Xu_Huitong/article/details/130332458CloudCompare功能介绍-Label Connected Components-CSDN博客
https://blog.csdn.net/Xu_Huitong/article/details/130332458CloudCompare功能介绍-Label Connected Components-CSDN博客![]() https://blog.csdn.net/Xu_Huitong/article/details/129239371
https://blog.csdn.net/Xu_Huitong/article/details/129239371
5. 执行分割
- 在选定区域或使用算法后,点击
Segment或Apply按钮,CloudCompare会根据你的设置进行点云分割。
6. 保存分割结果
- 分割后,新的点云段会显示在CloudCompare的DB Tree中。你可以:
- 右键点击新生成的点云段,选择
Save来保存这个分割出的部分。 - 或者选择
File->Save As来保存所有或选定的点云数据。
- 右键点击新生成的点云段,选择
三、点云补全

在实际应用中,点云数据往往不完整。比如,当我们用3D扫描仪扫描一个物体时,可能会有一些地方没有扫描到,导致点云数据有缺失。这种不完整的点云会影响到后续的处理和应用,因此我们需要一种方法来补全这些缺失的部分。
点云补全的目标是通过已有的点云数据,预测并生成缺失部分的点,使点云数据更加完整和准确。这可以帮助我们在后续的应用中获得更好的效果,比如更精确的3D建模、更准确的物体识别等。
3.1.PF-Net模型(了解)
PF-Net(Point Fractal Network)是一种针对3D点云补全任务的深度学习模型。在3D计算机视觉领域,尤其是在对象重建和增强现实等应用中,对缺失部分的高质量补全是非常关键的。PF-Net通过生成缺失的3D点云数据来实现这一目标。例如,假设完整点云包含2048个点,而不完整点云包含512个点,那么模型将生成512个点来补全不完整点云。
下图中,作者先进行了下采样(如下图分别是512->128->64个点,注意这个是缺失的部分,他们不是输入!!输入的是全部的2048个点!!!),随后分别卷积进行特征提取(最开始提取出来的特征分别为2048(包含缺失点的总特征)->1024->512个)(三个提取出来的特征经过处理(最大池化)后变为等量以便后续拼接,经作者的试验后定为1920个)并拼接。随后在经过MLP整合到最终的特征。接下来通过三个全连接“降维”(特征数变化为1024->512->256),随后我们就可以看到点的预测个数从上到下依次减少。而预测的过程是从下到上,先预测一个骨架(经过reshape后为64个点),再补充细节。也就是说FC2生成时不仅仅考虑了自身的点情况,还要以FC3为基本骨架。
注意:补全模型是根据已知的特征而预测缺失数据的,输入的数据是全部的点!!!最开始的512个点经过几次采样后的操作针对的都是缺失点!这个操作是方便了后续生成骨架并逐步预测缺失部分的!!
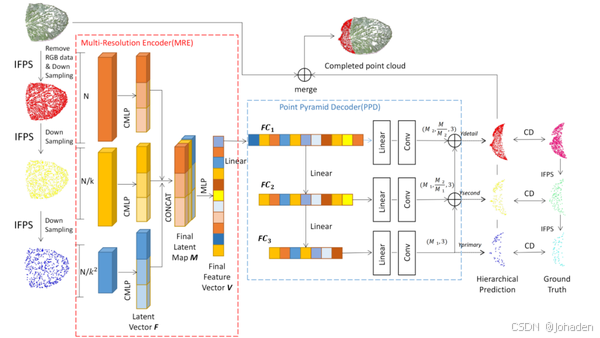
3.1.1.模型结构(了解)
PF-Net由编码器(Encoder)和解码器(Decoder)两部分组成。
①编码器(Encoder)
编码器负责从输入的不完整点云中提取特征。PF-Net使用了PointNet++作为编码器,因为PointNet++能够有效地提取点云的局部特征。
1.1 PointNet++编码器
- 分组:将点云中的点按照空间关系分组(半径)。
- 卷积:在每个组内进行卷积操作,提取局部特征。卷积操作通常使用MLP(多层感知机)来实现。
- 池化:通过池化操作(如最大池化)将局部特征聚合为全局特征。
1.2 特征提取
编码器的输出是点云的全局特征和局部特征。全局特征表示整个点云的总体信息,局部特征表示点云的局部细节。
②解码器(Decoder)
解码器负责根据编码器提取的特征生成完整的点云。PF-Net的解码器采用了一种基于自回归(Autoregressive)的方法来生成点。
2.1 特征映射
将编码器提取的全局特征和局部特征拼接在一起,形成一个综合特征向量。这个综合特征向量包含了点云的全局和局部信息,有助于生成更准确的点。
2.2 点生成
- 初始点:从高维空间中随机采样一个初始点。
- 逐步生成:在每一步中,使用当前生成的点和拼接后的特征向量作为输入,生成下一个点。这个过程可以看作是一个递归过程,直到生成足够多的点为止。
四、点云滤波
点云滤波是指通过一系列算法和技术,对原始点云数据进行处理,以去除噪声点、减少数据量、保留关键特征的过程。滤波的目的在于提高点云数据的质量,使其更适合后续的处理任务,如配准、分割、特征提取等。这个过程是在预处理数据中的一个过程,在配准之前。

4.1.常见的点云滤波方法
1. 低通滤波(Low-Pass Filter)
原理:低通滤波是一种信号处理技术,用于去除高频噪声,保留低频信号。在点云中,低通滤波可以平滑点云数据,减少高频噪声,使点云表面更加平滑。
例子:假设你在拍摄一个雕像的点云数据,但由于环境干扰,点云数据中有很多细小的凹凸不平。通过低通滤波,可以平滑这些细小的凹凸,使雕像表面更加光滑。
应用场景:适用于需要平滑点云表面、减少高频噪声的情况。
2. 直通滤波(Pass-Through Filter)
原理:直通滤波是一种基于范围的滤波方法,通过设定一个轴向的范围,去除不在该范围内的点。通常用于去除不需要的背景点或特定区域的点。
例子:假设你在拍摄一个房间的点云数据,但房间外有很多无关的物体。通过直通滤波,可以设定一个高度范围,去除所有高于或低于这个范围的点,从而只保留房间内的点云数据。
应用场景:适用于需要去除特定区域或背景点的情况。
3. 高斯滤波(Gaussian Filter)
原理:高斯滤波通过高斯函数对点云数据进行平滑处理,减少高频噪声。高斯滤波在每个点的邻域内应用一个高斯权重,使得邻近点对当前点的影响逐渐减小。
例子:假设你在拍摄一个建筑物的点云数据,但建筑物表面有很多细小的裂纹。通过高斯滤波,可以平滑这些裂纹,使建筑物表面更加光滑。
应用场景:适用于需要平滑点云表面、减少高频噪声的情况。
4. 双边滤波(Bilateral Filter)
原理:双边滤波是一种结合了空间邻近性和灰度相似性的滤波方法。它不仅考虑了点的空间距离,还考虑了点的属性值(如颜色、反射强度等)的相似性。双边滤波可以在平滑点云的同时,保留边缘和细节。
例子:假设你在拍摄一个城市的点云数据,城市中有许多建筑物和树木。通过双边滤波,可以平滑建筑物表面,同时保留建筑物和树木的边缘和细节。
应用场景:适用于需要平滑点云表面、同时保留边缘和细节的情况。
5. 统计滤波(Statistical Outlier Removal)
原理:统计滤波通过统计方法检测和去除离群点。具体来说,它会计算每个点到其邻近点的距离均值和标准差,如果某个点的距离均值超过了设定的阈值,就会被认为是噪声点并被去除。
例子:假设你在拍摄一个广场上的雕塑的点云数据。由于风的影响,有些点云数据被风吹得偏离了原本的位置,形成了离群点。通过统计滤波,可以计算每个点到其邻近点的距离,找出那些距离过远的点并将其去除,从而得到一个更干净的点云数据。
应用场景:适用于需要去除离群点、减少噪声的情况。
6. CSF地面滤波(Cloth Simulation Filter for Ground Segmentation)
原理:CSF地面滤波是一种基于布料模拟的地面分割方法。它将点云数据看作一块布料,通过模拟布料的下垂过程,将地面点和其他非地面点分开。
例子:假设你在拍摄一个森林的点云数据,森林中有许多树木和地面。通过CSF地面滤波,可以将地面点和树木点分开,从而只保留地面点或树木点。
应用场景:适用于需要将地面点和其他非地面点分开的情况,常用于地形建模和自动驾驶等领域。
7. 坡度法地面滤波(Slope-Based Ground Segmentation)
原理:坡度法地面滤波通过计算点云数据的坡度(即点的高度变化率),将地面点和其他非地面点分开。通常设定一个坡度阈值,低于该阈值的点被认为是地面点。
例子:假设你在拍摄一个山地的点云数据,山地上有许多岩石和植被。通过坡度法地面滤波,可以计算每个点的坡度,将坡度低于阈值的点识别为地面点,从而将地面点和岩石、植被点分开。
应用场景:适用于需要将地面点和其他非地面点分开的情况,常用于地形建模和地质调查等领域。
软件实现操作:
CloudCompare——点云滤波_cloudcompare点云滤波-CSDN博客文章浏览阅读3.6w次,点赞97次,收藏590次。CloudCompare——点云滤波_cloudcompare点云滤波https://blog.csdn.net/qq_36686437/article/details/120011047
五、点云配准
假设现在有两组点云数据,一组是从前面扫描的雕像,另一组是从侧面扫描的同一个雕像。因为这两组点云是从不同角度获取的,所以它们的位置和方向都不一样。点云配准就是要解决这个问题,让这两组点云能够正确地拼接到一起,形成一个完整的雕像模型。
点云配准通常分为粗配准和精配准两个阶段:
-
粗配准:这是第一步,我们需要找到一个大致的变换,让两个点云看起来像是在同一个地方。这一步不需要非常精确,但需要足够好,以便进行下一步。
-
精配准:在这一步,我们会使用更精细的方法来调整点云的位置,直到它们尽可能地匹配。这通常涉及到迭代的过程,不断地调整直到达到最佳匹配。
传统算法有ICP、RPM等,需要手动输入很多经验参数选择。
ICP算法,全称Iterative Closest Point,是一种用于点云配准的经典算法。它的核心思想是通过迭代的方式,逐步调整两组点云之间的相对位置,使得它们之间的距离最小化,从而实现精确对齐。
CloudCompare——实现点云由粗到精的配准_点云粗配准-CSDN博客文章浏览阅读3w次,点赞85次,收藏426次。CloudCompare——实现点云由粗到精的配准_点云粗配准https://blog.csdn.net/qq_36686437/article/details/119966436
在科学研究中,使用标靶球进行点云配准是一种常见的方法,它利用预先放置在扫描场景中的球形标靶来辅助配准过程(由于野外特征点可能不清楚,故把它看作特征点)。以下是使用标靶球进行配准的基本步骤:
-
准备标靶球:选择适当大小和颜色的球形标靶,确保它们在扫描过程中能够被清晰地识别。标靶球的数量和分布应该足够覆盖整个扫描区域,以便在不同的扫描站之间建立联系。
-
布置标靶球:在扫描场景中布置标靶球,确保它们在不同的扫描站中都能被捕捉到。标靶球应该放置在不会被遮挡的位置,并且在空间中均匀分布。
-
进行扫描:使用激光扫描仪或其他设备对场景进行扫描,捕获包含标靶球的点云数据。确保每个扫描站都能够捕捉到足够的标靶球,以便后续的配准。
-
提取球心坐标:从捕获的点云数据中提取标靶球的球心坐标。这通常通过拟合球面模型来实现,可以使用专门的算法或软件工具来自动完成这一过程。
-
配准点云:使用标靶球的球心坐标作为公共点,将不同扫描站捕获的点云数据进行配准。这可以通过直接匹配球心坐标或使用标靶球作为参考点来实现。配准过程中可能需要考虑旋转和平移变换。
-
验证配准结果:检查配准后的点云是否对齐良好。可以通过可视化检查或计算配准误差来评估配准的质量。如果配准结果不理想,可能需要调整配准参数或重新进行配准。
深度学习算法:RPM-Net等(需要手动设置的参数和迭代交给神经网络做,但是速度很慢)由于本人没有学习过深度学习,所以不做任何代码解析。
[CVPR 2020] RPM-Net: Robust Point Matching using Learned Features_rpmnet-CSDN博客文章浏览阅读7.6k次,点赞23次,收藏92次。零、概要论文: RPM-Net: Robust Point Matching using Learned Featurestag: CVPR 2020; registration代码: https://github.com/yewzijian/RPMNet/作者: Zi Jian Yew, Gim Hee Lee机构: Department of Computer Science, National University of Singapore笔者整理了一个最近几年150多篇点云的论文列表,_rpmnethttps://blog.csdn.net/zhulf0804/article/details/109071416