文章目录
- 一、自然语言处理基础知识
- 1.1 常见自然语言处理任务
- 1.2 自然语言处理的几个阶段
- 二、Transformers简单介绍
- 2.1 Transformers相关库介绍
- 2.2 Transformers 相关库安装
- 三、简单代码,启动NLP应用
一、自然语言处理基础知识
1.1 常见自然语言处理任务
- 情感分析(sentiment analysis):对给定的文本分析其情感极性
- 文本生成(text-generation):根据给定的文本进行生成
- 命名实体识别(ner): 标记句子中的实体
- 阅读理解(questin-answering):给定上下文与问题,从上下文中抽取答案
- 掩码填充(fill-mask):填充给定文本中的掩码词
- 文本摘要(summarization):生成一段长文本的摘要
- 机器翻译(translation):将文本翻译成另外一种语言
- 特征提取(feature-extraction):生成给定文本的张量提示
- 对话机器人(conversational):根据用户输入文本,产生回应,与用户对话
1.2 自然语言处理的几个阶段
- 第一阶段:统计模型+数据(特征工程
- 决策树、SVM、HMM、CRF、TH-IDF、BOW
- 第二阶段:神经网络+数据
- Linear、CNN、RNN、GRU、LSTM、Transformer、Word2vec、Glove
- 第三阶段:神经网络+预训练模型+(少量)数据
- GPT、BERT、RoBerta、ALBERT、BART、T5
- 第四阶段: 神经网络+更大的预训练模型+Prompt
- ChatGPT、Bloom、LLaMA、Alpaca、Vicuna、MOSS、文心一言、通义千问、星火
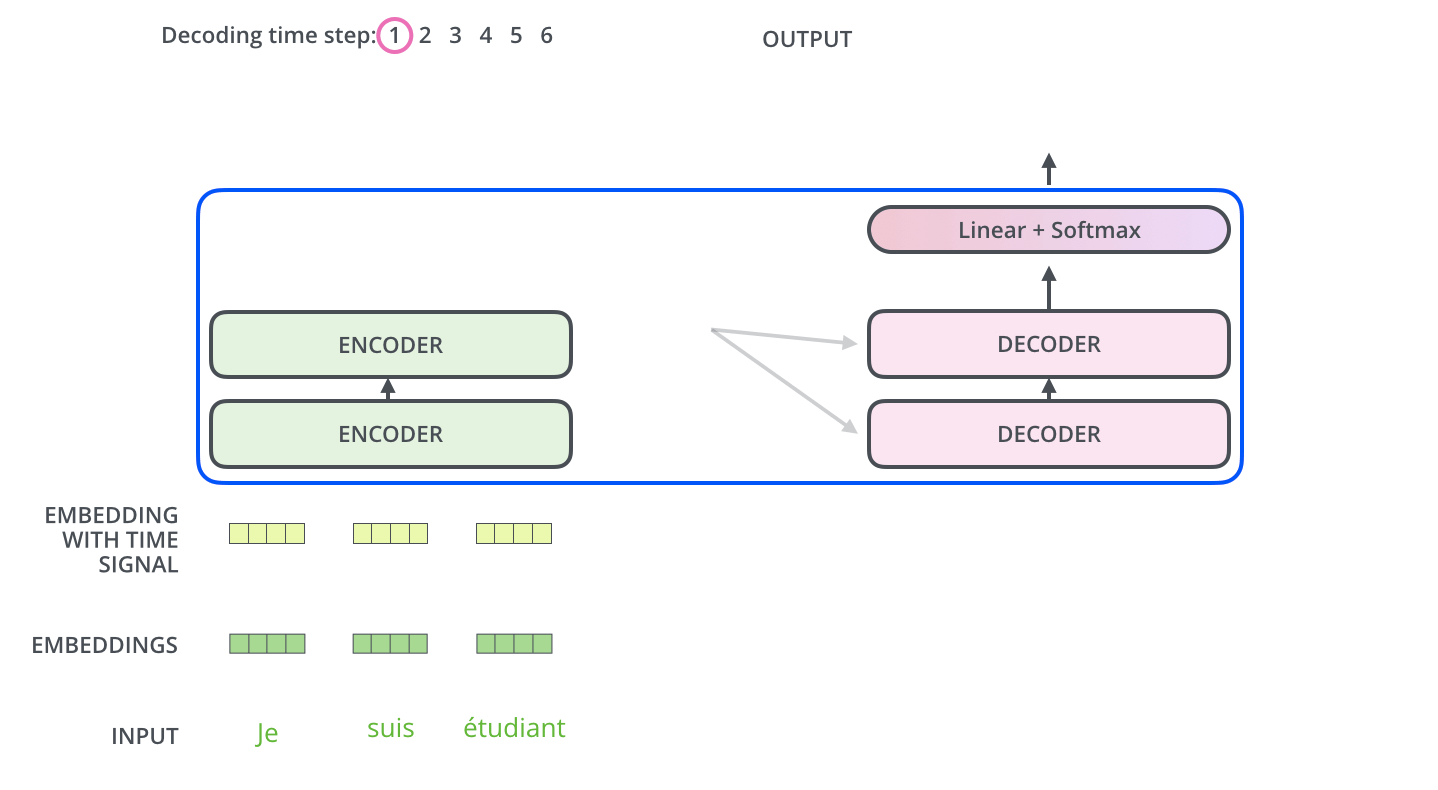
二、Transformers简单介绍
- 官网:https://huggingface.co/
- 一个好用的镜像网站: https://hf-mirror.com/
- HuggingFace出品,最常使用的自然语言处理工具
- 实现了大量基于Transformer架构的主流预训练模型,并且不局限于自然语言处理模型,还包括图像、音频以及多模态的模型
- 提供了海量的预训练模型与数据集,同时支持用户自行上传、社区完善,文档全,上手简单
2.1 Transformers相关库介绍
- Tranformers:核心库,包括了模型加载、模型训练、流水线(pipeline)等
- Tokenizer:分词器,对数据进行预处理,文本到token序列的相互转换
- Datasets:数据集库,提供了数据的加载、处理等方法
- Evaluate:评估函数,提供了各种评价指标的计算函数
- PETF: 搞笑微调模型的库,提供了几种搞笑微调的方法,小参数量撬动大模型
- Accelerate:分布式训练,提供了分布式训练解决方案,包括大模型的加载与推理解决方案
- Optimum:优化加速库,支持多种后端,如Onnxruntime,OpenVINO等
- Gradio:可视化部署库,几行代码,快速实现基于Wed交互的算法演示系统
2.2 Transformers 相关库安装
pip install transformers datasets evaluate peft accelerate gradio optimum sentencepiece
其他包缺啥补啥
三、简单代码,启动NLP应用
会自动下载模型,但有时候访问Github比较慢,可以自行搜索如何修改hosts。
from transformers import AutoModelForQuestionAnswering, pipeline
import gradio as gr
gr.Interface.from_pipeline(pipeline("question-answering", model="uer/roberta-base-finetuned-dianping-chinese")).launch()
也可以离线下载模型,登录huggingface官网或者镜像网站,搜索到指定的模型,然后下载文件,到models文件夹即可

from transformers import AutoModelForQuestionAnswering, pipeline
import gradio as gr
gr.Interface.from_pipeline(pipeline("question-answering", model="../../models/models")).launch()接下来,登录URL,就可以操作一个简单的网页交互拉。