LLM 的知识仅限于其训练数据。如希望使 LLM 了解特定领域的知识或专有数据,可:
- 使用本节介绍的 RAG
- 使用你的数据对 LLM 进行微调
- 结合使用 RAG 和微调
1 啥是 RAG?
RAG 是一种在将提示词发送给 LLM 之前,从你的数据中找到并注入相关信息的方式。这样,LLM 希望能获得相关的信息并利用这些信息作出回应,从而减少幻觉概率。
可通过各种信息检索方法找到相关信息。这些方法包括但不限于:
- 全文(关键词)搜索。该方法使用 TF-IDF 和 BM25 等技术,通过匹配查询(例如用户提问)中的关键词与文档数据库中的内容来搜索文档。它根据这些关键词在每个文档中的频率和相关性对结果进行排名
- 向量搜索,也称“语义搜索”。文本文档通过嵌入模型转换为数值向量。然后根据查询向量与文档向量之间的余弦相似度或其他相似度/距离度量,查找并对文档进行排名,从而捕捉更深层次的语义含义
- 混合搜索。结合多种搜索方法(例如全文搜索 + 向量搜索)通常能提高搜索效果
本文主要关注向量搜索。全文搜索和混合搜索目前仅通过 Azure AI Search 集成支持,详情参见 AzureAiSearchContentRetriever。计划在不久的将来扩展 RAG 工具箱,以包含全文搜索和混合搜索。
2 RAG 的阶段
RAG 过程分为两个不同阶段:索引和检索。LangChain4j 提供用于两个阶段的工具。
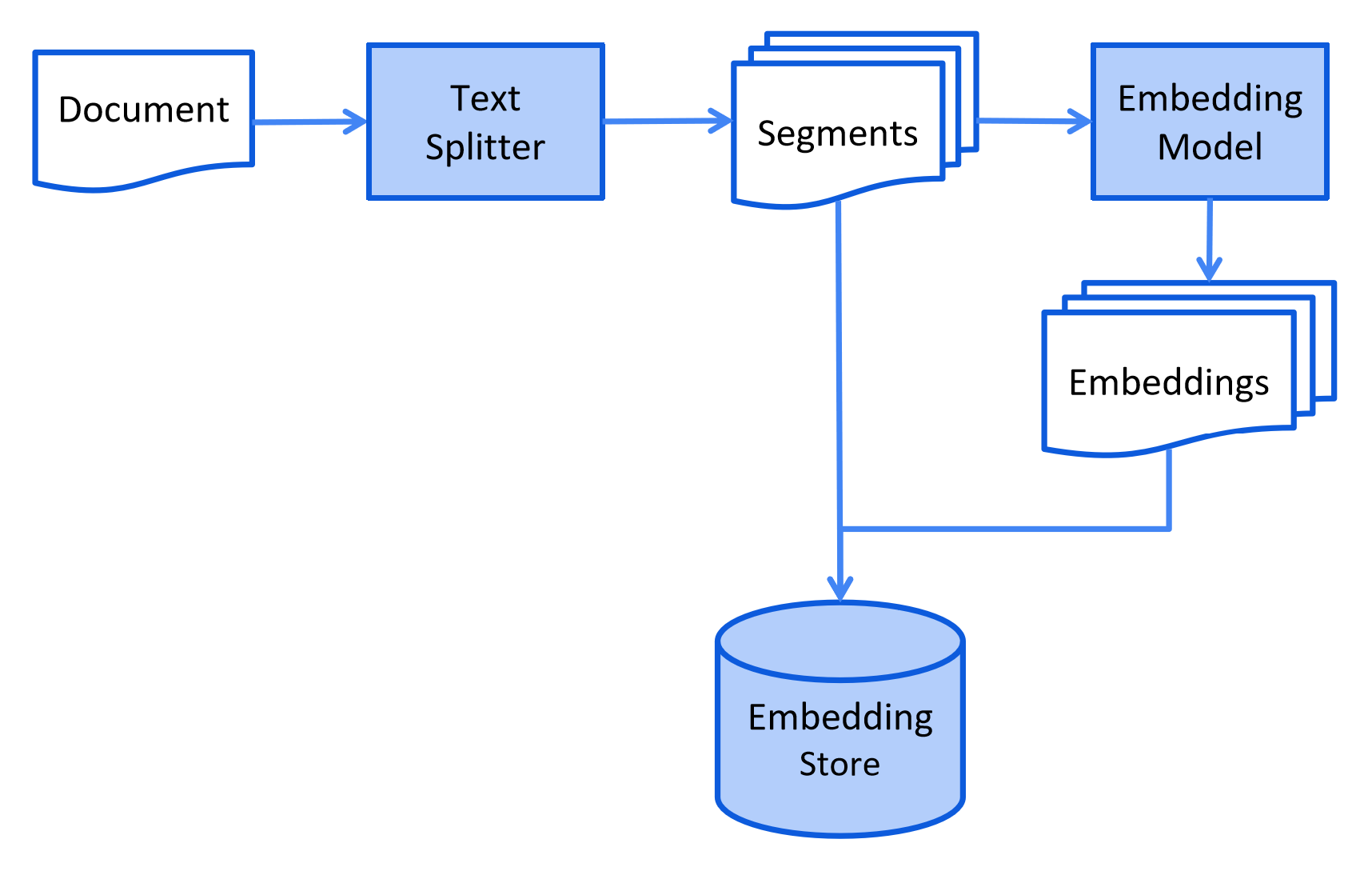
2.1 索引
文档会进行预处理,以便在检索阶段实现高效搜索。
该过程可能因使用的信息检索方法而有所不同。对向量搜索,通常包括清理文档,利用附加数据和元数据对其进行增强,将其拆分为较小的片段(即“分块”),对这些片段进行嵌入,最后将它们存储在嵌入存储库(即向量数据库)。
通常在离线完成,即用户无需等待该过程的完成。可通过例如每周末运行一次的定时任务来重新索引公司内部文档。负责索引的代码也可以是一个仅处理索引任务的单独应用程序。
但某些场景,用户可能希望上传自定义文档以供 LLM 访问。此时,索引应在线进行,并成为主应用程序的一部分。
索引阶段的简化流程图
2.2 检索
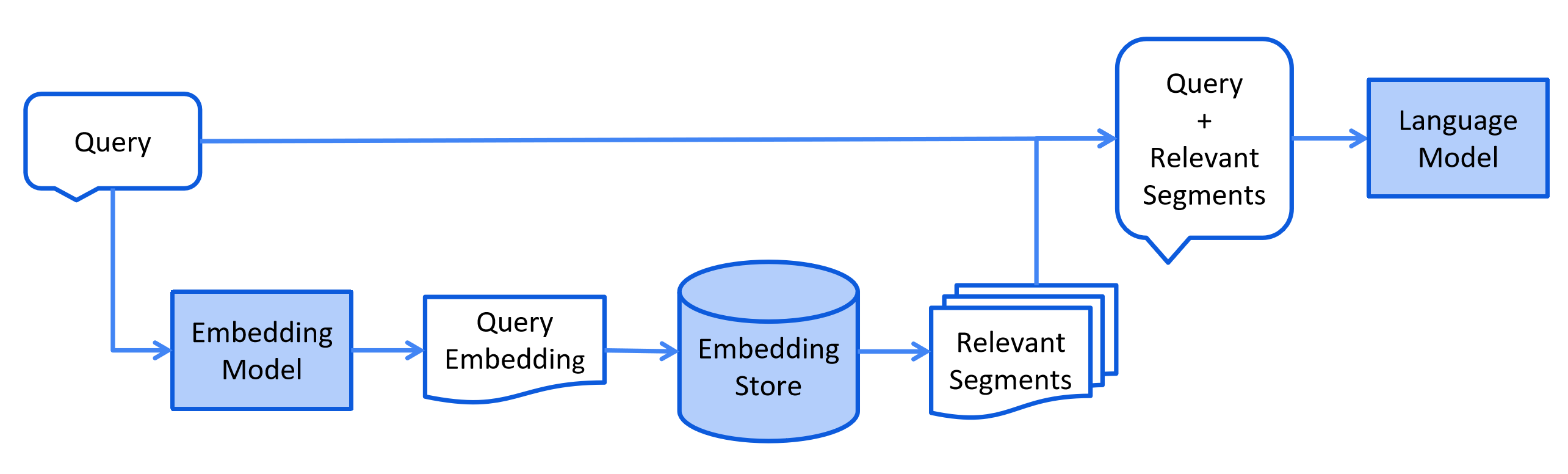
通常在线进行,当用户提交一个问题时,系统会使用已索引的文档来回答问题。
该过程可能会因所用的信息检索方法不同而有所变化。对于向量搜索,通常包括嵌入用户的查询(问题),并在嵌入存储库中执行相似度搜索。然后,将相关片段(原始文档的部分内容)注入提示词并发送给 LLM。
检索阶段的简化流程图
3 简单 RAG
LangChain4j 提供了“简单 RAG”功能,使你尽可能轻松使用 RAG。无需学习嵌入技术、选择向量存储、寻找合适的嵌入模型、了解如何解析和拆分文档等操作。只需指向你的文档,LangChain4j 就会自动处理!
若需定制化RAG,请跳到rag-apis。
当然,这种“简单 RAG”的质量会比定制化 RAG 设置的质量低一些。然而,这是学习 RAG 或制作概念验证的最简单方法。稍后,您可以轻松地从简单 RAG 过渡到更高级的 RAG,逐步调整和自定义各个方面。
3.1 导入 langchain4j-easy-rag 依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-easy-rag</artifactId><version>0.34.0</version>
</dependency>3.2 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation");这将加载指定目录下的所有文件。
底层发生了什么?
Apache Tika 库被用于检测文档类型并解析它们。由于我们没有显式指定使用哪个 DocumentParser,因此 FileSystemDocumentLoader 将加载 ApacheTikaDocumentParser,该解析器由 langchain4j-easy-rag 依赖通过 SPI 提供。
咋自定义加载文档?
若想加载所有子目录中的文档,可用 loadDocumentsRecursively :
List<Document> documents = FileSystemDocumentLoader.loadDocumentsRecursively("/home/langchain4j/documentation");还可通过使用 glob 或正则表达式过滤文档:
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation", pathMatcher);使用
loadDocumentsRecursively时,可能要在 glob 中使用双星号(而不是单星号):glob:**.pdf。
3.3 预处理
并将文档存储在专门的嵌入存储中也称向量数据库。这是为了在用户提出问题时快速找到相关信息片段。可用 15+ 种支持的嵌入存储,但为简化操作,使用内存存储:
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);底层发生了啥?
EmbeddingStoreIngestor通过 SPI 从langchain4j-easy-rag依赖中加载DocumentSplitter。每个Document被拆分成较小的片段(即TextSegment),每个片段不超过 300 个 token,且有 30 个 token 的重叠部分。EmbeddingStoreIngestor通过 SPI 从langchain4j-easy-rag依赖中加载EmbeddingModel。每个TextSegment都使用EmbeddingModel转换为Embedding。
选择 bge-small-en-v1.5 作为简单 RAG 的默认嵌入模型。该模型在 MTEB 排行榜 上取得了不错的成绩,其量化版本仅占用 24 MB 空间。因此,我们可以轻松将其加载到内存中,并在同一进程中通过 ONNX Runtime 运行。
可在完全离线的情况下,在同一个 JVM 进程中将文本转换为嵌入。LangChain4j 提供 5 种流行的嵌入模型开箱即用。
所有
TextSegment和Embedding对被存储在EmbeddingStore中创建一个AI 服务,它将作为我们与 LLM 交互的 API:
interface Assistant {String chat(String userMessage);
}ChatLanguageModel chatModel = OpenAiChatModel.builder().apiKey(System.getenv("OPENAI_API_KEY")).modelName(GPT_4_O_MINI).build();Assistant assistant = AiServices.builder(Assistant.class).chatLanguageModel(chatModel).chatMemory(MessageWindowChatMemory.withMaxMessages(10)).contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore)).build();配置 Assistant 使用 OpenAI 的 LLM 来回答用户问题,记住对话中的最近 10 条消息,并从包含我们文档的 EmbeddingStore 中检索相关内容。
- 对话!
String answer = assistant.chat("如何使用 LangChain4j 实现简单 RAG?");4 访问源信息
如希望访问增强消息的检索源,可将返回类型包装在 Result 类中:
interface Assistant {Result<String> chat(String userMessage);
}Result<String> result = assistant.chat("如何使用 LangChain4j 实现简单 RAG?");String answer = result.content();
List<Content> sources = result.sources();流式传输时,可用 onRetrieved() 指定一个 Consumer<List<Content>>:
interface Assistant {TokenStream chat(String userMessage);
}assistant.chat("如何使用 LangChain4j 实现简单 RAG?").onRetrieved(sources -> ...).onNext(token -> ...).onError(error -> ...).start();5 RAG API
LangChain4j 提供丰富的 API 让你可轻松构建从简单到高级的自定义 RAG 流水线。本节介绍主要的领域类和 API。
5.1 文档(Document)
Document 类表示整个文档,例如单个 PDF 文件或网页。当前,Document 只能表示文本信息,但未来的更新将支持图像和表格。
package dev.langchain4j.data.document;/*** 表示通常对应于单个文件内容的非结构化文本。此文本可能来自各种来源,如文本文件、PDF、DOCX 或网页 (HTML)。* 每个文档都可能具有关联的元数据,包括其来源、所有者、创建日期等*/
public class Document {/*** Common metadata key for the name of the file from which the document was loaded.*/public static final String FILE_NAME = "file_name";/*** Common metadata key for the absolute path of the directory from which the document was loaded.*/public static final String ABSOLUTE_DIRECTORY_PATH = "absolute_directory_path";/*** Common metadata key for the URL from which the document was loaded.*/public static final String URL = "url";private final String text;private final Metadata metadata;API
Document.text()返回Document的文本内容Document.metadata()返回Document的元数据(见下文)Document.toTextSegment()将Document转换为TextSegment(见下文)Document.from(String, Metadata)从文本和Metadata创建一个DocumentDocument.from(String)从文本创建一个带空Metadata的Document
5.2 元数据(Metadata)
每个 Document 都包含 Metadata,用于存储文档的元信息,如名称、来源、最后更新时间、所有者或任何其他相关细节。
Metadata 以KV对形式存储,其中键是 String 类型,值可为 String、Integer、Long、Float、Double 中的任意一种。
用途
- 在将文档内容包含到 LLM 的提示词中时,可以将元数据条目一并包含,向 LLM 提供额外信息。例如,提供文档名称和来源可以帮助 LLM 更好地理解内容。
- 在搜索相关内容以包含在提示词中时,可以根据元数据条目进行过滤。例如,您可以将语义搜索范围限制为属于特定所有者的文档。
- 当文档的来源被更新(例如文档的特定页面),您可以通过其元数据条目(例如“id”、“source”等)轻松找到相应的文档,并在嵌入存储中更新它,以保持同步。
API
Metadata.from(Map)从Map创建MetadataMetadata.put(String key, String value)/put(String, int)/ 等方法添加元数据条目Metadata.getString(String key)/getInteger(String key)/ 等方法返回元数据条目的值,并转换为所需类型Metadata.containsKey(String key)检查元数据中是否包含指定键的条目Metadata.remove(String key)从元数据中删除指定键的条目Metadata.copy()返回元数据的副本Metadata.toMap()将元数据转换为Map
5.3 文档加载器(Document Loader)
可从 String 创建一个 Document,但更简单的是使用库中包含的文档加载器之一:
FileSystemDocumentLoader来自langchain4j模块UrlDocumentLoader来自langchain4j模块AmazonS3DocumentLoader来自langchain4j-document-loader-amazon-s3模块AzureBlobStorageDocumentLoader来自langchain4j-document-loader-azure-storage-blob模块GitHubDocumentLoader来自langchain4j-document-loader-github模块TencentCosDocumentLoader来自langchain4j-document-loader-tencent-cos模块
5.4 文本片段转换器
TextSegmentTransformer 类似于 DocumentTransformer(如上所述),但它用于转换 TextSegment。
与 DocumentTransformer 类似,没有统一的解决方案,建议根据您的数据自定义实现 TextSegmentTransformer。
提高检索效果的有效方法是将 Document 的标题或简短摘要包含在每个 TextSegment 。
5.5 嵌入
Embedding 类封装了一个数值向量,表示嵌入内容(通常是文本,如 TextSegment)的“语义意义”。
关于向量嵌入的内容:
- https://www.elastic.co/what-is/vector-embedding
- https://www.pinecone.io/learn/vector-embeddings/
- https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings
API
Embedding.dimension()返回嵌入向量的维度(即长度)CosineSimilarity.between(Embedding, Embedding)计算两个Embedding之间的余弦相似度Embedding.normalize()对嵌入向量进行归一化(就地操作)
嵌入模型
EmbeddingModel 接口代表一种特殊类型的模型,将文本转换为 Embedding。
当前支持的嵌入模型可以在这里找到。
API
EmbeddingModel.embed(String)嵌入给定的文本EmbeddingModel.embed(TextSegment)嵌入给定的TextSegmentEmbeddingModel.embedAll(List<TextSegment>)嵌入所有给定的TextSegmentEmbeddingModel.dimension()返回该模型生成的Embedding的维度
嵌入存储
EmbeddingStore 接口表示嵌入存储,也称为向量数据库。它用于存储和高效搜索相似的(在嵌入空间中接近的)Embedding。
当前支持的嵌入存储可以在这里找到。
EmbeddingStore 可以单独存储 Embedding,也可以与相应的 TextSegment 一起存储:
- 它可以仅按 ID 存储
Embedding,嵌入的数据可以存储在其他地方,并通过 ID 关联。 - 它可以同时存储
Embedding和被嵌入的原始数据(通常是TextSegment)。
API
EmbeddingStore.add(Embedding)将给定的Embedding添加到存储中并返回随机 IDEmbeddingStore.add(String id, Embedding)将给定的Embedding以指定 ID 添加到存储中EmbeddingStore.add(Embedding, TextSegment)将给定的Embedding和关联的TextSegment添加到存储中,并返回随机 IDEmbeddingStore.addAll(List<Embedding>)将一组Embedding添加到存储中,并返回一组随机 IDEmbeddingStore.addAll(List<Embedding>, List<TextSegment>)将一组Embedding和关联的TextSegment添加到存储中,并返回一组随机 IDEmbeddingStore.search(EmbeddingSearchRequest)搜索最相似的EmbeddingEmbeddingStore.remove(String id)按 ID 从存储中删除单个EmbeddingEmbeddingStore.removeAll(Collection<String> ids)按 ID 从存储中删除多个EmbeddingEmbeddingStore.removeAll(Filter)删除存储中与指定Filter匹配的所有EmbeddingEmbeddingStore.removeAll()删除存储中的所有Embedding
嵌入搜索请求(EmbeddingSearchRequest)
EmbeddingSearchRequest 表示在 EmbeddingStore 中的搜索请求。其属性如下:
Embedding queryEmbedding: 用作参考的嵌入。int maxResults: 返回的最大结果数。这是一个可选参数,默认为 3。double minScore: 最低分数,范围为 0 到 1(含)。仅返回得分 >=minScore的嵌入。这是一个可选参数,默认为 0。Filter filter: 搜索时应用于Metadata的过滤器。仅返回Metadata符合Filter的TextSegment。
过滤器(Filter)
关于 Filter 的更多细节可以在这里找到。
嵌入搜索结果(EmbeddingSearchResult)
EmbeddingSearchResult 表示在 EmbeddingStore 中的搜索结果,包含 EmbeddingMatch 列表。
嵌入匹配(Embedding Match)
EmbeddingMatch 表示一个匹配的 Embedding,包括其相关性得分、ID 和嵌入的原始数据(通常是 TextSegment)。
嵌入存储导入器
EmbeddingStoreIngestor 表示一个导入管道,负责将 Document 导入到 EmbeddingStore。
在最简单的配置中,EmbeddingStoreIngestor 使用指定的 EmbeddingModel 嵌入提供的 Document,并将它们与其 Embedding 一起存储在指定的 EmbeddingStore 中:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder().embeddingModel(embeddingModel).embeddingStore(embeddingStore).build();ingestor.ingest(document1);
ingestor.ingest(document2, document3);
ingestor.ingest(List.of(document4, document5, document6));可选地,EmbeddingStoreIngestor 可以使用指定的 DocumentTransformer 来转换 Document。这在您希望在嵌入之前对文档进行清理、增强或格式化时非常有用。
可选地,EmbeddingStoreIngestor 可以使用指定的 DocumentSplitter 将 Document 拆分为 TextSegment。这在文档较大且您希望将其拆分为较小的 TextSegment 时非常有用,以提高相似度搜索的质量并减少发送给 LLM 的提示词的大小和成本。
可选地,EmbeddingStoreIngestor 可以使用指定的 TextSegmentTransformer 来转换 TextSegment。这在您希望在嵌入之前对 TextSegment 进行清理、增强或格式化时非常有用。
示例:
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()// 为每个 Document 添加 userId 元数据条目,便于后续过滤.documentTransformer(document -> {document.metadata().put("userId", "12345");return document;})// 将每个 Document 拆分为 1000 个 token 的 TextSegment,具有 200 个 token 的重叠.documentSplitter(DocumentSplitters.recursive(1000, 200, new OpenAiTokenizer()))// 为每个 TextSegment 添加 Document 的名称,以提高搜索质量.textSegmentTransformer(textSegment -> TextSegment.from(textSegment.metadata("file_name") + "\n" + textSegment.text(),textSegment.metadata())).embeddingModel(embeddingModel).embeddingStore(embeddingStore).build();关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&券等营销中台建设
交易平台及数据中台等架构和开发设计
车联网核心平台-物联网连接平台、大数据平台架构设计及优化
LLM Agent应用开发
区块链应用开发
大数据开发挖掘经验
推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!