【#】SFT 训练
项目地址:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/sft.html
可以使用以下命令进行微调:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
examples/train_lora/llama3_lora_sft.yaml 提供了微调时的配置示例。该配置指定了模型参数、微调方法参数、数据集参数以及评估参数等。您需要根据自身需求自行配置。
### examples/train_lora/llama3_lora_sft.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instructstage: sft
do_train: true
finetuning_type: lora
lora_target: alldataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: trueper_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500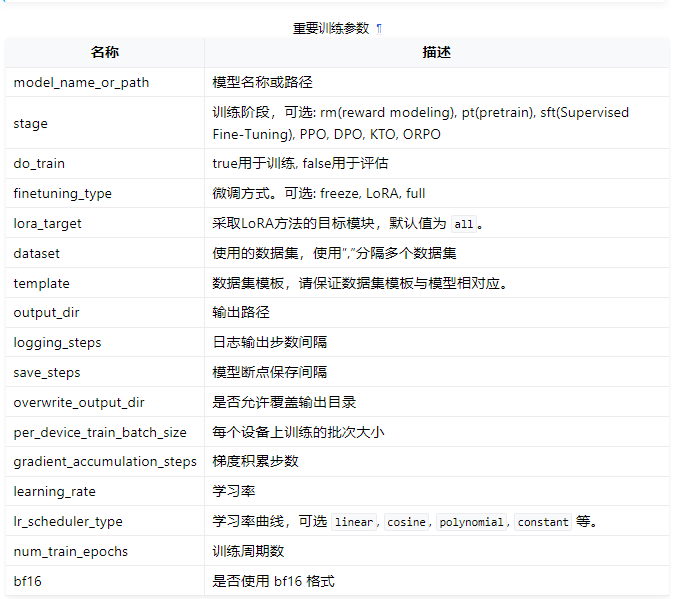
【#】LoRA 合并
教程地址:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/merge_lora.html
当我们基于预训练模型训练好 LoRA 适配器后,我们不希望在每次推理的时候分别加载预训练模型和 LoRA 适配器,因此我们需要将预训练模型和 LoRA 适配器合并导出成一个模型。根据是否量化以及量化算法的不同,导出的配置文件有所区别。
您可以通过 llamafactory-cli export merge_config.yaml 指令来合并模型。其中 merge_config.yaml 需要您根据不同情况进行配置。
量化(Quantization)通过数据精度压缩有效地减少了显存使用并加速推理。LLaMA-Factory 支持多种量化方法,包括:
- AQLM
- AWQ
- GPTQ
- QLoRA
- …
GPTQ 等后训练量化方法(Post Training Quantization)是一种在训练后对预训练模型进行量化的方法。我们通过量化技术将高精度表示的预训练模型转换为低精度的模型,从而在避免过多损失模型性能的情况下减少显存占用并加速推理,我们希望低精度数据类型在有限的表示范围内尽可能地接近高精度数据类型的表示,因此我们需要指定量化位数 export_quantization_bit 以及校准数据集 export_quantization_dataset。
在进行模型合并时,请指定:
model_name_or_path: 预训练模型的名称或路径template: 模型模板export_dir: 导出路径export_quantization_bit: 量化位数export_quantization_dataset: 量化校准数据集export_size: 最大导出模型文件大小export_device: 导出设备export_legacy_format: 是否使用旧格式导出
下面提供一个配置文件示例:
### examples/merge_lora/llama3_gptq.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
template: llama3### export
export_dir: models/llama3_gptq
export_quantization_bit: 4
export_quantization_dataset: data/c4_demo.json
export_size: 2
export_device: cpu
export_legacy_format: false
QLoRA 是一种在 4-bit 量化模型基础上使用 LoRA 方法进行训练的技术。它在极大地保持了模型性能的同时大幅减少了显存占用和推理时间。
### examples/merge_lora/llama3_q_lora.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
examples/merge_lora/llama3_lora_sft.yaml 提供了合并时的配置示例。
## examples/merge_lora/llama3_lora_sft.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
备注:模型
model_name_or_path需要存在且与template相对应。adapter_name_or_path需要与微调中的适配器输出路径output_dir相对应。合并 LoRA 适配器时,不要使用量化模型或指定量化位数。您可以使用本地或下载的未量化的预训练模型进行合并。
【#】模型推理
教程地址:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/inference.html
LLaMA-Factory 支持多种推理方式。
可以使用 llamafactory-cli chat inference_config.yaml 或 llamafactory-cli webchat inference_config.yaml 进行推理与模型对话。对话时配置文件只需指定原始模型 model_name_or_path 和 template ,并根据是否是微调模型指定 adapter_name_or_path 和 finetuning_type。
如果希望向模型输入大量数据集并记录推理输出,您可以使用 llamafactory-cli train inference_config.yaml 使用数据集或 llamafactory-cli api 使用 api 进行批量推理。
使用任何方式推理时,模型 model_name_or_path 需要存在且与 template 相对应。
原始模型推理配置
对于原始模型推理,inference_config.yaml中 只需指定原始模型 ``model_name_or_path和template` 即可。
### examples/inference/llama3.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
template: llama
微调模型推理配置
对于微调模型推理,除原始模型和模板外,还需要指定适配器路径 adapter_name_or_path 和微调类型 finetuning_type。
### examples/inference/llama3_lora_sft.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
多模态模型
对于多模态模型,您可以运行以下指令进行推理。
llamafactory-cli webchat examples/inferece/llava1_5.yaml
examples/inference/llava1_5.yaml 的配置示例如下:
model_name_or_path: llava-hf/llava-1.5-7b-hf
template: vicuna
visual_inputs: true
vllm推理框架
若使用vllm推理框架,请在配置中指定: infer_backend 与 vllm_enforce_eager。
### examples/inference/llama3_vllm.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
template: llama3
infer_backend: vllm
vllm_enforce_eager: true使用数据集批量推理
使用数据集批量推理时,需要指定模型、适配器(可选)、评估数据集、输出路径等信息并且指定 do_predict 为 true。下面提供一个 示例,可以通过 使用数据集进行批量推理。
llamafactory-cli train examples/train_lora/llama3_lora_predict.yaml如果您需要多卡推理,则需要在配置文件中指定 deepspeed 参数。
# examples/train_lora/llama3_lora_predict.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sftdeepspeed: examples/deepspeed/ds_z3_config.yaml # deepspeed配置文件### method
stage: sft
do_predict: true
finetuning_type: lora### dataset
eval_dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 50
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: saves/llama3-8b/lora/predict
overwrite_output_dir: true### eval
per_device_eval_batch_size: 1
predict_with_generate: true
ddp_timeout: 180000000只有 stage 为 sft 的时候才可设置 predict_with_generate 为 true。
使用api批量推理
如果需要使用 api 进行批量推理,您只需指定模型、适配器(可选)、模板、微调方式等信息。
下面是一个配置文件的示例:
# examples/inference/llama3_lora_sft.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora下面是一个启动并调用 api 服务的示例:
可以使用 如下 启动 api 服务:
API_PORT=8000 CUDA_VISIBLE_DEVICES=0 llamafactory-cli api examples/inference/llama3_lora_sft.yaml并运行以下示例程序进行调用:
# api_call_example.py
from openai import OpenAI
client = OpenAI(api_key="0",base_url="http://0.0.0.0:8000/v1")
messages = [{"role": "user", "content": "Who are you?"}]
result = client.chat.completions.create(messages=messages, model="meta-llama/Meta-Llama-3-8B-Instruct")
print(result.choices[0].message)【#】模型评估
教程地址:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/eval.html
在完成模型训练后,可以通过 llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml 来评估模型效果。
配置示例文件 examples/train_lora/llama3_lora_eval.yaml 具体如下:
### examples/train_lora/llama3_lora_eval.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft # 可选项### method
finetuning_type: lora### dataset
task: mmlu_test
template: fewshot
lang: en
n_shot: 5### output
save_dir: saves/llama3-8b/lora/eval### eval
batch_size: 4
在 批量推理 的过程中,模型的 BLEU 和 ROUGE 分数会被自动计算并保存,您也可以通过此方法评估模型。
下面是相关参数的介绍:

针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

【#】加速技术
LLaMA-Factory 支持多种加速技术,包括:FlashAttention 、 Unsloth 。
FlashAttention
FlashAttention 能够加快注意力机制的运算速度,同时减少对内存的使用。
如果您想使用 FlashAttention,请在启动训练时在训练配置文件中添加以下参数:
flash_attn: fa2Unsloth
Unsloth 框架支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大语言模型并且支持 4-bit 和 16-bit 的 QLoRA/LoRA 微调,该框架在提高运算速度的同时还减少了显存占用。
如果您想使用 Unsloth,请在启动训练时在训练配置文件中添加以下参数:
use_unsloth: True【#】调优算法
LLaMA-Factory 支持多种调优算法,包括:Full Parameter Fine-tuning 、 Freeze 、 LoRA 、 Galore 、 BAdam 。
Full Parameter Fine-tuning
全参微调指的是在训练过程中对于预训练模型的所有权重都进行更新,但其对显存的要求是巨大的。
如果您需要进行全参微调,请将 finetuning_type 设置为 full 。下面是一个例子:
### examples/train_full/llama3_full_sft_ds3..yaml
# ...
finetuning_type: full
# ...
# 如果需要使用deepspeed:
deepspeed: examples/deepspeed/ds_z3_config.json
Freeze
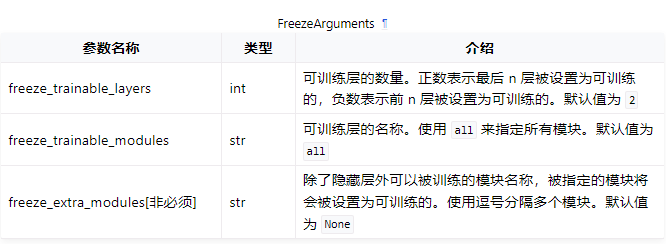
Freeze(冻结微调)指的是在训练过程中只对模型的小部分权重进行更新,这样可以降低对显存的要求。
如果您需要进行冻结微调,请将 finetuning_type 设置为 freeze 并且设置相关参数, 例如冻结的层数 freeze_trainable_layers 、可训练的模块名称 freeze_trainable_modules 等。
以下是一个例子:
...
### method
stage: sft
do_train: true
finetuning_type: freeze
freeze_trainable_layers: 8
freeze_trainable_modules: all
...
LoRA
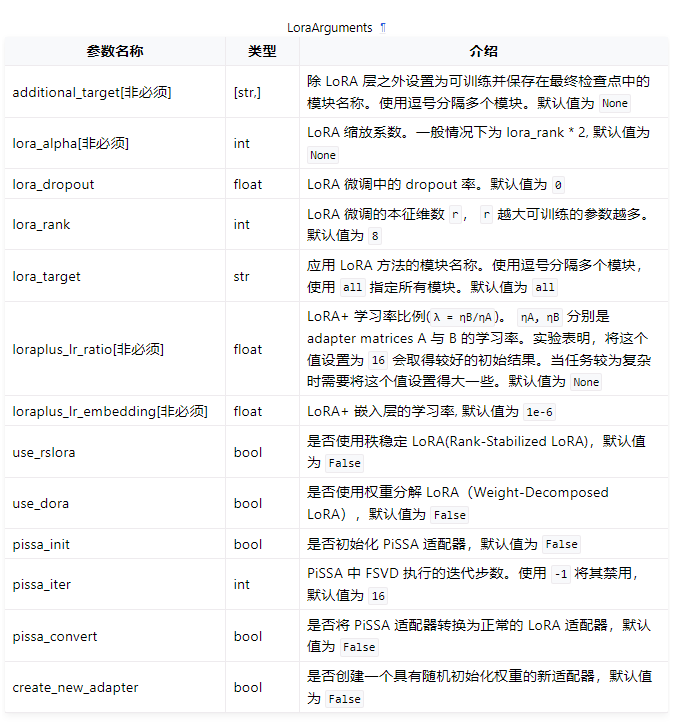
如果您需要进行 LoRA 微调,请将 finetuning_type 设置为 lora 并且设置相关参数。下面是一个例子:
...
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
lora_rank: 8
lora_alpha: 16
lora_dropout: 0.1
...
LoRA+
在LoRA中,适配器矩阵 A 和 B 的学习率相同。您可以通过设置 loraplus_lr_ratio 来调整学习率比例。在 LoRA+ 中,适配器矩阵 A 的学习率 ηA 即为优化器学习率。适配器矩阵 B 的学习率 ηB 为 λ * ηA。其中 λ 为 loraplus_lr_ratio 的值,一般取16。
rsLoRA
LoRA 通过添加低秩适配器进行微调,然而当增大 lora_rank 时,其训练速度会减慢。rsLoRA(Rank-Stabilized LoRA) 通过修改缩放因子使得模型训练更加稳定。使用 rsLoRA 时, lora_rank 的大小对训练速度没有影响。注意,使用rsLoRA时, 您只需要将 use_rslora 设置为 True ,而无需修改 lora_rank, lora_alpha 等参数。
DoRA
DoRA (Weight-Decomposed Low-Rank Adaptation)提出尽管 LoRA 大幅降低了推理成本,但这种方式取得的性能与全量微调之间仍有差距。
DoRA 将权重矩阵分解为大小与单位方向矩阵的乘积,并进一步微调二者(对方向矩阵则进一步使用 LoRA 分解),从而实现 LoRA 与 Full Fine-tuning 之间的平衡。
如果您需要使用 DoRA,请将 use_dora 设置为 True 。
PiSSA
在 LoRA 中,适配器矩阵 A 由 kaiming_uniform 初始化,而适配器矩阵 B 则全初始化为0。这导致一开始的输入并不会改变模型输出并且使得梯度较小,收敛较慢。PiSSA 通过奇异值分解直接分解原权重矩阵进行初始化,其优势在于它可以更快更好地收敛。
如果您需要使用 PiSSA,请将 pissa_init 设置为 True 。
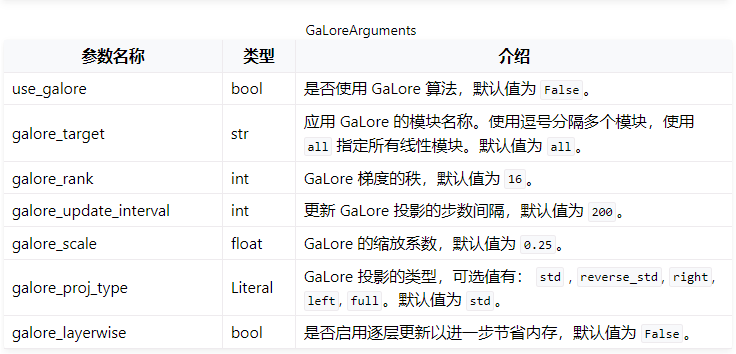
Galore
当需要在训练中使用 GaLore(Gradient Low-Rank Projection)算法时,可以通过设置 GaloreArguments 中的参数进行配置。
下面是一个例子:
### method
stage: sft
do_train: true
finetuning_type: full
use_galore: true
galore_layerwise: true
galore_target: mlp,self_attn
galore_rank: 128
galore_scale: 2.0
- 不要将 LoRA 和 GaLore/BAdam 一起使用。
galore_layerwise为true时请不要设置gradient_accumulation参数。
BAdam
BAdam 是一种内存高效的全参优化方法,您通过配置 BAdamArgument 中的参数可以对其进行详细设置。下面是一个例子:
### model
...
### method
stage: sft
do_train: true
finetuning_type: full
use_badam: true
badam_mode: layer
badam_switch_mode: ascending
badam_switch_interval: 50
badam_verbose: 2
pure_bf16: true
...
不要将 LoRA 和 GaLore/BAdam 一起使用。
使用 BAdam 时请设置 finetuning_type 为 full 且 pure_bf16 为 True 。
badam_mode = layer 时仅支持使用 DeepSpeed ZeRO3 进行 单卡 或 多卡 训练。
badam_mode = ratio 时仅支持 单卡 训练。

【#】分布训练-NativeDDP
LLaMA-Factory 支持单机多卡和多机多卡分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
DDP (DistributedDataParallel) 通过实现模型并行和数据并行实现训练加速。使用 DDP 的程序需要生成多个进程并且为每个进程创建一个 DDP 实例,他们之间通过 torch.distributed 库同步。
DeepSpeed 是微软开发的分布式训练引擎,并提供ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水线并行等优化技术。您可以根据任务需求与设备选择使用。
FSDP 通过全切片数据并行技术(Fully Sharded Data Parallel)来处理更多更大的模型。在 DDP 中,每张 GPU 都各自保留了一份完整的模型参数和优化器参数。而 FSDP 切分了模型参数、梯度与优化器参数,使得每张 GPU 只保留这些参数的一部分。除了并行技术之外,FSDP 还支持将模型参数卸载至CPU,从而进一步降低显存需求。

NativeDDP 是 PyTorch 提供的一种分布式训练方式,您可以通过以下命令启动训练:
**单机多卡-**llamafactory-cli
可以使用 llamafactory-cli 启动 NativeDDP 引擎。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml如果 CUDA_VISIBLE_DEVICES 没有指定,则默认使用所有GPU。如果需要指定GPU,例如第0、1个GPU,可以使用:
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train config/config1.yaml**单机多卡-**torchrun
可以使用 torchrun 指令启动 NativeDDP 引擎进行单机多卡训练。下面提供一个示例:
torchrun --standalone --nnodes=1 --nproc-per-node=8 src/train.py \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en_demo \
--template llama3 \
--finetuning_type lora \
--output_dir saves/llama3-8b/lora/ \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 100 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16**单机多卡-**accelerate
可以使用 accelerate 指令启动进行单机多卡训练。
首先运行以下命令,根据需求回答一系列问题后生成配置文件:
accelerate config下面提供一个示例配置文件:
# accelerate_singleNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
可以通过运行以下指令开始训练:
accelerate launch \
--config_file accelerate_singleNode_config.yaml \
src/train.py training_config.yaml多机多卡-lla****mafactory-cli
FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yamlFORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yam
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
多机多卡-torchrun
可以使用 torchrun 指令启动 NativeDDP 引擎进行多机多卡训练。
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=0 \
--master_addr=192.168.0.1 train.py
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=1 \
--master_addr=192.168.0.1 train.py多机多卡-accelerate
可以使用 accelerate 指令启动进行多机多卡训练。
首先运行以下命令,根据需求回答一系列问题后生成配置文件:
accelerate config下面提供一个示例配置文件:
# accelerate_multiNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false可以通过运行以下指令开始训练:
accelerate launch \
--config_file accelerate_multiNode_config.yaml \
train.py llm_config.yaml【#】分布训练-DeepSpeed
DeepSpeed 是由微软开发的一个开源深度学习优化库,旨在提高大模型训练的效率和速度。在使用 DeepSpeed 之前,您需要先估计训练任务的显存大小,再根据任务需求与资源情况选择合适的 ZeRO 阶段。
- ZeRO-1: 仅划分优化器参数,每个GPU各有一份完整的模型参数与梯度。
- ZeRO-2: 划分优化器参数与梯度,每个GPU各有一份完整的模型参数。
- ZeRO-3: 划分优化器参数、梯度与模型参数。
简单来说:从 ZeRO-1 到 ZeRO-3,阶段数越高,显存需求越小,但是训练速度也依次变慢。此外,设置 offload_param=cpu 参数会大幅减小显存需求,但会极大地使训练速度减慢。因此,如果您有足够的显存, 应当使用 ZeRO-1,并且确保 offload_param=none。
LLaMA-Factory提供了使用不同阶段的 DeepSpeed 配置文件的示例。包括:
- ZeRO-0 (不开启)
- ZeRO-2
- ZeRO-2+offload
- ZeRO-3
- ZeRO-3+offload
https://huggingface.co/docs/transformers/deepspeed 提供了更为详细的介绍。
单机多卡-llamafactory-cli
可以使用 llamafactory-cli 启动 DeepSpeed 引擎进行单机多卡训练。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml为了启动 DeepSpeed 引擎,配置文件中 deepspeed 参数指定了 DeepSpeed 配置文件的路径:
...deepspeed: examples/deepspeed/ds_z3_config.json...单机多卡-deepspeed
可以使用 deepspeed 指令启动 DeepSpeed 引擎进行单机多卡训练。
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json下面是一个例子:
deepspeed --num_gpus 8 src/train.py \
--deepspeed examples/deepspeed/ds_z3_config.json \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en \
--template llama3 \
--finetuning_type full \
--output_dir saves/llama3-8b/lora/full \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16使用 deepspeed 指令启动 DeepSpeed 引擎时您无法使用 CUDA_VISIBLE_DEVICES 指定GPU。而需要:
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json
--include localhost:1 表示只是用本节点的gpu1。多机多卡-deepspeed
LLaMA-Factory 支持使用 DeepSpeed 的多机多卡训练,您可以通过以下命令启动:
FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=192.168.0.1可以使用 deepspeed 指令来启动多机多卡训练。
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json多机多卡-accelerate
可以使用 accelerate 指令启动 DeepSpeed 引擎。首先通过以下命令生成 DeepSpeed 配置文件:
accelerate config下面提供一个配置文件示例:
# deepspeed_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:deepspeed_multinode_launcher: standardgradient_accumulation_steps: 8offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: falsezero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false随后,可以使用以下命令启动训练:
accelerate launch \
--config_file deepspeed_config.yaml \
train.py llm_config.yaml【#】DeepSpeed 配置文件
ZeRO-0
### ds_z0_config.json
{"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","gradient_clipping": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"zero_optimization": {"stage": 0,"allgather_partitions": true,"allgather_bucket_size": 5e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 5e8,"contiguous_gradients": true,"round_robin_gradients": true}
}
ZeRO-2
只需在 ZeRO-0 的基础上修改 zero_optimization 中的 stage 参数即可。
### ds_z2_config.json
{..."zero_optimization": {"stage": 2,...}
}
ZeRO-2+offload
只需在 ZeRO-0 的基础上在 zero_optimization 中添加 offload_optimizer 参数即可。
### ds_z2_offload_config.json
{..."zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},...}
}
ZeRO-3
只需在 ZeRO-0 的基础上修改 zero_optimization 中的参数。
### ds_z3_config.json
{..."zero_optimization": {"stage": 3,"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true}
}
ZeRO-3+offload
只需在 ZeRO-3 的基础上添加 zero_optimization 中的 offload_optimizer 和 offload_param 参数即可。
### ds_z3_offload_config.json
{..."zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},...}
}https://www.deepspeed.ai/docs/config-json/ 提供了关于deepspeed配置文件的更详细的介绍。
【#】分布训练-FSDP
PyTorch 的全切片数据并行技术 FSDP (Fully Sharded Data Parallel)能让我们处理更多更大的模型。LLaMA-Factory支持使用 FSDP 引擎进行分布式训练。
FSDP 的参数 ShardingStrategy 的不同取值决定了模型的划分方式:
FULL_SHARD: 将模型参数、梯度和优化器状态都切分到不同的GPU上,类似ZeRO-3。SHARD_GRAD_OP: 将梯度、优化器状态切分到不同的GPU上,每个GPU仍各自保留一份完整的模型参数。类似ZeRO-2。NO_SHARD: 不切分任何参数。类似ZeRO-0。
FSDP-llamafactory-cli
只需根据需要修改examples/accelerate/fsdp_config.yaml以及examples/extras/fsdp_qlora/llama3_lora_sft.yaml ,文件然后运行以下命令即可启动 FSDP+QLoRA 微调:
bash examples/extras/fsdp qlora/train.shFSDP-accelerate
可以使用 accelerate 启动 FSDP 引擎, 节点数与 GPU 数可以通过 num_machines 和 num_processes 指定。对此,Huggingface 提供了便捷的配置功能。只需运行:
accelerate config根据提示回答一系列问题后,我们就可以生成 FSDP 所需的配置文件。当然您也可以根据需求自行配置 fsdp_config.yaml 。
### /examples/accelerate/fsdp_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAPfsdp_backward_prefetch: BACKWARD_PREfsdp_forward_prefetch: falsefsdp_cpu_ram_efficient_loading: truefsdp_offload_params: true # offload may affect training speedfsdp_sharding_strategy: FULL_SHARDfsdp_state_dict_type: FULL_STATE_DICTfsdp_sync_module_states: truefsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: fp16 # or bf16
num_machines: 1 # the number of nodes
num_processes: 2 # the number of GPUs in all nodes
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false请确保
num_processes和实际使用的总GPU数量一致
随后,您可以使用以下命令启动训练:
accelerate launch \
--config_file fsdp_config.yaml \
src/train.py llm_config.yaml不要在 FSDP+QLoRA 中使用 GPTQ/AWQ 模型
【#】模型量化
https://llamafactory.readthedocs.io/zh-cn/latest/advanced/quantization.html
随着语言模型规模的不断增大,其训练的难度和成本已成为共识。而随着用户数量的增加,模型推理的成本也在不断攀升,甚至可能成为限制模型部署的首要因素。因此,我们需要对模型进行压缩以加速推理过程,而模型量化是其中一种有效的方法。
大语言模型的参数通常以高精度浮点数存储,这导致模型推理需要大量计算资源。量化技术通过将高精度数据类型存储的参数转换为低精度数据类型存储, 可以在不改变模型参数量和架构的前提下加速推理过程。这种方法使得模型的部署更加经济高效,也更具可行性。
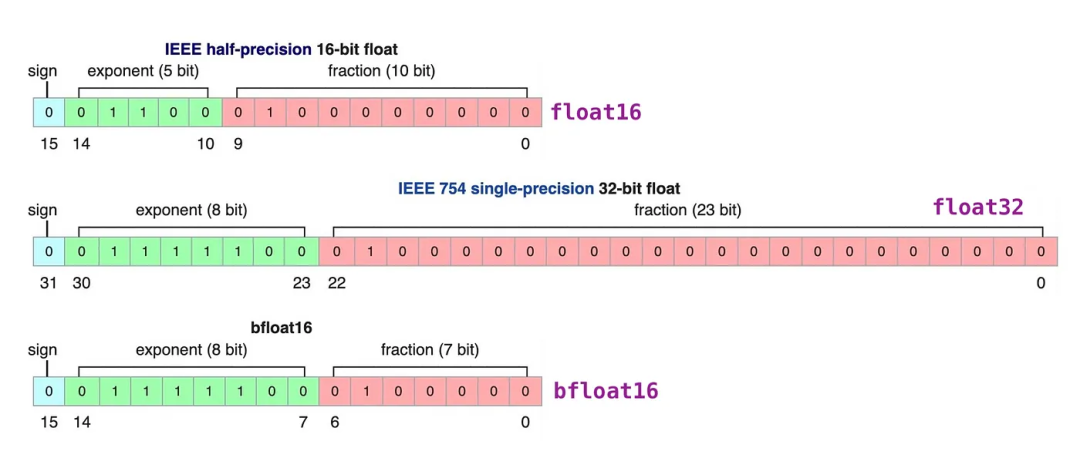
浮点数一般由3部分组成:符号位、指数位和尾数位。指数位越大,可表示的数字范围越大。尾数位越大、数字的精度越高。
量化可以根据何时量化分为:后训练量化和训练感知量化,也可以根据量化参数的确定方式分为:静态量化和动态量化。
PTQ
后训练量化(PTQ, Post-Training Quantization)一般是指在模型预训练完成后,基于校准数据集(calibration dataset)确定量化参数进而对模型进行量化。
GPTQ
**GPTQ(Group-wise Precision Tuning Quantization)是一种静态的后训练量化技术。”静态”指的是预训练模型一旦确定,经过量化后量化参数不再更改。GPTQ 量化技术将 fp16 精度的模型量化为 4-bit ,在节省了约 75% 的显存的同时大幅提高了推理速度。**为了使用GPTQ量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-GPTQ
QAT
在训练感知量化(QAT, Quantization-Aware Training)中,模型一般在预训练过程中被量化,然后又在训练数据上再次微调,得到最后的量化模型。
AWQ
**AWQ(Activation-Aware Layer Quantization)是一种静态的后训练量化技术。其思想基于:有很小一部分的权重十分重要,为了保持性能这些权重不会被量化。AWQ 的优势在于其需要的校准数据集更小,且在指令微调和多模态模型上表现良好。**为了使用 AWQ 量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-AWQ
AQLM
**AQLM(Additive Quantization of Language Models)作为一种只对模型权重进行量化的PTQ方法,在 2-bit 量化下达到了当时的最佳表现,并且在 3-bit 和 4-bit 量化下也展示了性能的提升。**尽管 AQLM 在模型推理速度方面的提升并不是最显著的,但其在 2-bit 量化下的优异表现意味着您可以以极低的显存占用来部署大模型。
OFTQ
OFTQ(On-the-fly Quantization)指的是模型无需校准数据集,直接在推理阶段进行量化。OFTQ是一种动态的后训练量化技术. OFTQ在保持性能的同时。因此,在使用OFTQ量化方法时,您需要指定预训练模型、指定量化方法 quantization_method 和指定量化位数 quantization_bit 下面提供了一个使用bitsandbytes量化方法的配置示例:
model_name_or_path:meta-llama/Meta-Llama-3-8B-Instruct
quantization_bit:4
quantization_method:bitsandbytes# choices: [bitsandbytes (4
bitsandbytes
区别于 GPTQ, bitsandbytes 是一种动态的后训练量化技术。bitsandbytes 使得大于 1B 的语言模型也能在 8-bit 量化后不过多地损失性能。经过bitsandbytes 8-bit 量化的模型能够在保持性能的情况下节省约50%的显存。
HQQ
依赖校准数据集的方法往往准确度较高,不依赖校准数据集的方法往往速度较快。HQQ(Half-Quadratic Quantization)希望能在准确度和速度之间取得较好的平衡。作为一种动态的后训练量化方法,HQQ无需校准阶段, 但能够取得与需要校准数据集的方法相当的准确度,并且有着极快的推理速度。
EETQ
EETQ(Easy and Efficient Quantization for Transformers)是一种只对模型权重进行量化的PTQ方法。具有较快的速度和简单易用的特性。
【#】训练方法
https://llamafactory.readthedocs.io/zh-cn/latest/advanced/trainers.html
Pre-training
大语言模型通过在一个大型的通用数据集上通过无监督学习的方式进行预训练,来学习语言的表征/初始化模型权重/学习概率分布。期望在预训练后模型能够处理大量、多种类的数据集,进而可以通过监督学习的方式来微调模型使其适应特定的任务。
预训练时,请将 stage 设置为 pt ,并确保使用的数据集符合 预训练数据集 格式 。
(https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html#id7)
下面提供预训练的配置示例:
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct### method
stage: pt
do_train: true
finetuning_type: lora
lora_target: all### dataset
dataset: c4_demo
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000** **
Post-training
在预训练结束后,模型的参数得到初始化,模型能够理解语义、语法以及识别上下文关系,在处理一般性任务时有着不错的表现。尽管模型涌现出的零样本学习,少样本学习的特性使其能在一定程度上完成特定任务, 但仅通过提示(prompt)并不一定能使其表现令人满意。因此,我们需要后训练(post-training)来使得模型在特定任务上也有足够好的表现。
Supervised Fine-Tuning
Supervised Fine-Tuning(监督微调)是一种在预训练模型上使用小规模有标签数据集进行训练的方法。相比于预训练一个全新的模型,对已有的预训练模型进行监督微调是更快速更节省成本的途径。
监督微调时,请将 stage 设置为 sft 。下面提供监督微调的配置示例:
stage: sft
fintuning_type: lora
RLHF
由于在监督微调中语言模型学习的数据来自互联网,所以模型可能无法很好地遵循用户指令,甚至可能输出非法、暴力的内容,因此我们需要将模型行为与用户需求对齐(alignment)。通过 RLHF(Reinforcement Learning from Human Feedback) 方法,我们可以通过人类反馈来进一步微调模型,使得模型能够更好更安全地遵循用户指令。
Reward model
但是,获取真实的人类数据是十分耗时且昂贵的。一个自然的想法是我们可以训练一个奖励模型(reward model)来代替人类对语言模型的输出进行评价。为了训练这个奖励模型,我们需要让奖励模型获知人类偏好,而这通常通过输入经过人类标注的偏好数据集来实现。在偏好数据集中,数据由三部分组成:输入、好的回答、坏的回答。奖励模型在偏好数据集上训练,从而可以更符合人类偏好地评价语言模型的输出。
在训练奖励模型时,请将 stage 设置为 rm ,确保使用的数据集符合 偏好数据集 格式并且指定奖励模型的保存路径。以下提供一个示例:
...
stage: rm
dataset: dpo_en_demo
...
output_dir: saves/llama3-8b/lora/reward
...
PPO
在训练奖励完模型之后,我们可以开始进行模型的强化学习部分。与监督学习不同,在强化学习中我们没有标注好的数据。语言模型接受prompt作为输入,其输出作为奖励模型的输入。奖励模型评价语言模型的输出,并将评价返回给语言模型。确保两个模型都能良好运行是一个具有挑战性的任务。一种实现方式是使用近端策略优化(PPO,Proximal Policy Optimization)。其主要思想是:我们既希望语言模型的输出能够尽可能地获得奖励模型的高评价,又不希望语言模型的变化过于“激进”。通过这种方法,我们可以使得模型在学习趋近人类偏好的同时不过多地丢失其原有的解决问题的能力。
在使用 PPO 进行强化学习时,请将 stage 设置为 ppo,并且指定所使用奖励模型的路径。下面是一个示例:
...
stage: ppo
reward_model: saves/llama3-8b/lora/reward
...
DPO
既然同时保证两个语言模型与奖励模型的良好运行是有挑战性的,一种想法是我们可以丢弃奖励模型, 进而直接基于人类偏好训练我们的语言模型,这大大简化了训练过程。
在使用 DPO 时,请将 stage 设置为 dpo,确保使用的数据集符合 偏好数据集 格式并且设置偏好优化相关参数。以下是一个示例:
...
### method
stage: dpo
pref_beta: 0.1
pref_loss: sigmoid # choices: [sigmoid (dpo), orpo, simpo]
dataset: dpo_en_demo
...
KTO
KTO
KTO(Kahneman-Taversky Optimization) 的出现是为了解决成对的偏好数据难以获得的问题。KTO使用了一种新的损失函数,使其只需二元的标记数据, 即只需标注回答的好坏即可训练,并取得与 DPO 相似甚至更好的效果。
在使用 KTO 时,请将 stage 设置为 kto ,设置偏好优化相关参数并使用 KTO 数据集。
以下是一个示例:
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
...
stage: kto
pref_beta: 0.1
...
dataset: kto_en_dem
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓