文章目录
- 一、简介
- 二、网络结构
- 2.1编码器部分
- 2.2解码器部分
- 2.3完整代码
- 三、实战案例
一、简介
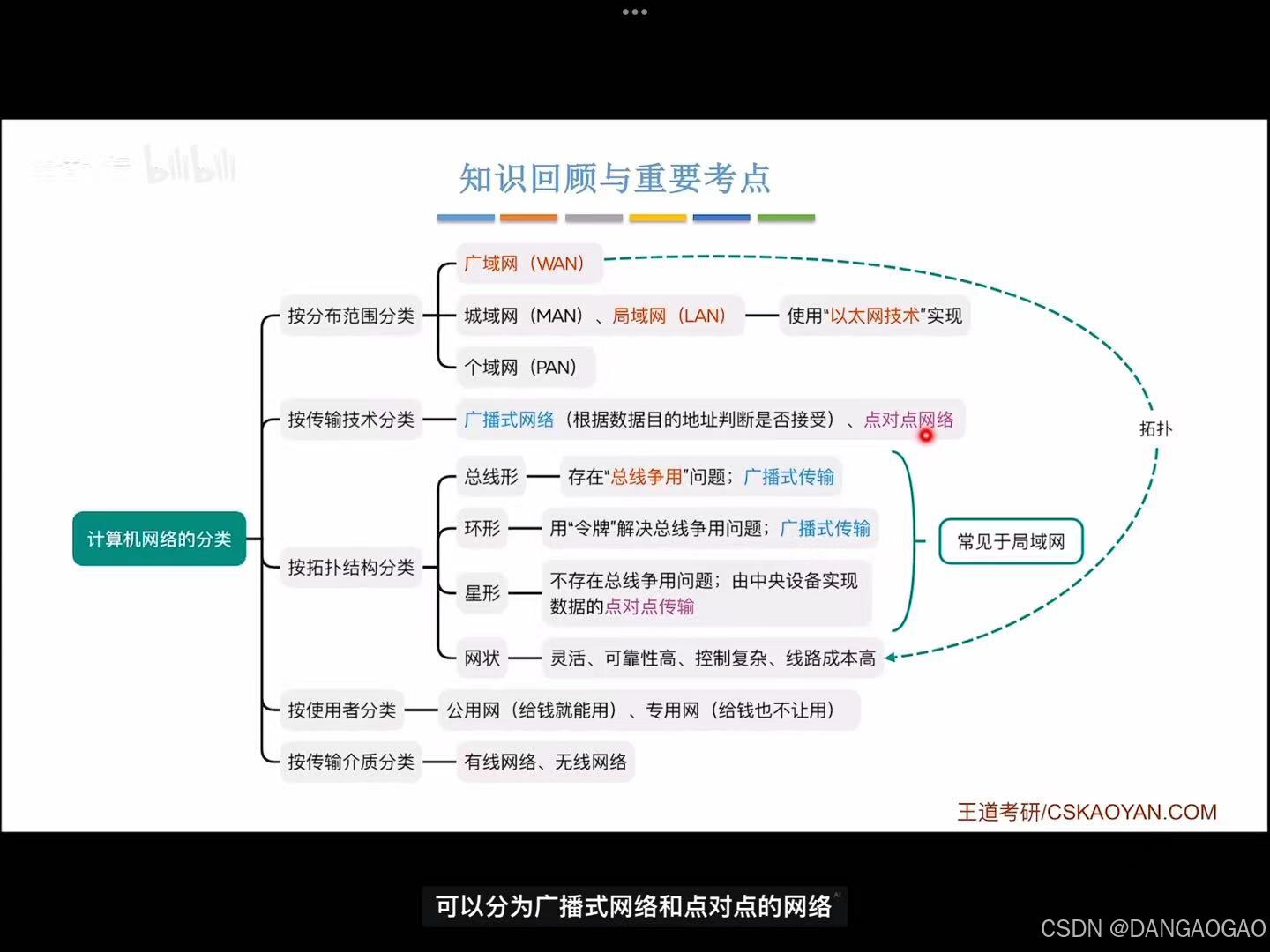
UNet网络是一种用于图像分割的卷积神经网络,其特点是采用了U型网络结构,因此称为UNet。该网络具有编码器和解码器结构,两种结构的功能如下:
- 编码器:逐步提取输入图像的特征并降低空间分辨率。
- 解码器:通过上采样操作将特征图恢复到原始输入图像的尺寸,并逐步生成分割结果。
【CNN角度的编码器、解码器】以卷积神经网络为例,输入为一个猫,进行特征提取后输出图片类别。
- 编码器:完成对输入图片中猫的特征提取。
- 解码器:将特征提取的结果解码为分类结果。

【RNN角度的编码器、解码器】以循环神经网络LSTM为例,输入为一个文本,进行特征提取再输出
- 编码器:将文本表示为向量并实现特征提取。
- 解码器:将向量转化为输出。

UNet算法的关键创新是在解码器中引入了跳跃连接(Skip Connections),即将编码器中的特征图与解码器中对应的特征图进行连接。这种跳跃连接可以帮助解码器更好地利用不同层次的特征信息,从而提高图像分割的准确性和细节保留能力。
二、网络结构
UNet的设计思想是通过编码器逐渐提取丰富的低级特征和高级特征,然后通过解码器逐渐恢复分辨率,并将低级特征和高级特征进行融合,以便获取准确且具有上下文信息的分割结果。这种U字形结构使得UNet能够同时利用全局(高分辨率时的特征图)和局部信息(低分辨率时的特征图),适用于图像分割任务。执行过程可粗略描述为:
输入层 -> 编码器(下采样模块 + 编码器模块) -> 解码器(上采样模块 + 解码器模块)-> 输出层。
即:
- 编码器(Encoder)部分:
- 输入层:接受输入图像作为模型的输入。
- 下采样模块(Downsampling Block):由一系列卷积层(通常是卷积、批归一化和激活函数的组合)和池化层组成,用于逐渐减小特征图的尺寸和通道数。这样可以逐渐提取出更高级别的特征信息。
- 编码器模块(Encoder Block):重复使用多个下采样模块,以便逐渐减小特征图的尺寸和通道数。每个编码器模块通常包含一个下采样模块和一个跳跃连接(Skip Connection),将上一级的特征图连接到下一级,以便在解码器中进行特征融合。
- 解码器(Decoder)部分:
- 上采样模块(Upsampling Block):由一系列上采样操作(如反卷积或转置卷积)和卷积操作组成,用于逐渐增加特征图的尺寸和通道数。这样可以逐渐恢复分辨率并且保留更多的细节信息。
- 解码器模块(Decoder Block):重复使用多个上采样模块,以便逐渐增加特征图的尺寸和通道数。每个解码器模块通常包含一个上采样模块、一个跳跃连接和一个融合操作(如拼接或加权求和),用于将来自编码器的特征图与当前解码器的特征图进行融合。
- 输出层:最后一层是一个卷积层,用于生成最终的分割结果。通常,输出层的通道数等于任务中的类别数,并应用适当的激活函数(如sigmoid或softmax),以产生每个像素点属于各个类别的概率分布。
跳跃连接(skip connection):输入数据直接添加到网络某一层输出之上。这种设计使得信息可以更自由地流动,并且保留了原始输入数据中的细节和语义信息。 使信息更容易传播到后面的层次,避免了信息丢失。跳跃连接通常会通过求和操作或拼接操作来实现。
以图像分类任务为例,假设我们使用卷积神经网络进行特征提取,在每个卷积层后面都加入一个池化层来减小特征图尺寸。然而,池化操作可能导致信息损失。通过添加一个跳跃连接,将原始输入直接与最后一个池化层输出相加或拼接起来,可以保留原始图像中更多的细节和语义信息。

以下内容参考文章:点击跳转
2.1编码器部分

编码器部分由多个下采样模块(down sampling step)组成,每个下采样模块都由两个卷积层(卷积核大小为3x3,且与ReLU函数配合使用。由于图像尺寸变小,可见并未填充)和一个最大池化层(池化核大小2x2,步幅为2,将图像尺寸收缩一半)组成,并且每一次下采样操作后特征图的通道数均增加一倍。
事实上,随着不断执行下采样模块(也成为收缩路径),特征图通道数随着卷积操作也不断增加,从而获取了图像的更多特征。并且在进入下一下采样模块前,进行 2x2 最大池化以获得最大像素值,虽然丢失一些特征,但保留最大像素值。通过这种方式,可将图像中目标的像素按类别进行分割。每一下采样模块的实现代码如下:
【第一个下采样模块】
卷积操作:
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)#(572,572,1)->((572-3+1),(572-3+1),64)->(570,570,64)self.relu1_1 = nn.ReLU(inplace=True)self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # (570,570,64)->((570-3+1),(570-3+1),64)->(568,568,64)self.relu1_2 = nn.ReLU(inplace=True)
池化操作
#采用最大池化进行下采样,图片大小减半,通道数不变,由(568,568,64)->(284,284,64)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
【第二个下采样模块】
卷积操作:
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) #(284,284,64)->(282,282,128)self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) #(282,282,128)->(280,280,128)self.relu2_2 = nn.ReLU(inplace=True)
池化操作:
# 采用最大池化进行下采样(280,280,128)->(140,140,128)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
编码器部分总代码:
class Unet(nn.Module):def __init__(self):super(Unet, self).__init__()#第一个下采样模块self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)self.relu1_1 = nn.ReLU(inplace=True)self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) self.relu1_2 = nn.ReLU(inplace=True)self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) #第二个下采样模块self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) #(284,284,64)->(282,282,128)self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) #(282,282,128)->(280,280,128)self.relu2_2 = nn.ReLU(inplace=True)self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) #第三个下采样模块self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0)self.relu3_1 = nn.ReLU(inplace=True)self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0)self.relu3_2 = nn.ReLU(inplace=True)self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2)#第四个下采样模块self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0)self.relu4_1 = nn.ReLU(inplace=True)self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0)self.relu4_2 = nn.ReLU(inplace=True)self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) #第五个下采样模块self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024self.relu5_1 = nn.ReLU(inplace=True)self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0)self.relu5_2 = nn.ReLU(inplace=True)
在五个下采样操作后,特征图大小变为 ( 28 , 28 , 1024 ) (28,28,1024) (28,28,1024)。
2.2解码器部分

- up-conv 2x2:上采样操作,通过反卷积操作实现。
- copy and crop:复制和裁剪,将下采样模块输出的特征图进行复制和裁剪,方便和上采样生成的特征图进行拼接。
在下采样操作中,模型已经得到了所有类的像素特征值。虽然使用最大池化操作时丢失了一些细节信息,但无需担心。在上采样中,模型通过将具有相同下采样滤波器的级别的特征图复制到相同的上采样过滤器级别来获得完整的图像,从而保留特征。因此,我们得到完整的图像,并可以定位每个类的图像中存在的位置,并且,再次通过应用卷积来学习全尺寸图像。所以在上采样时,下采样模块输出的每个特征图都被添加到上采样模块的相应特征层中,以获得全分辨率图像,从而实现类别的定位,这一过程也被称为跳跃连接。
第一个上采样模块细节如下:

最下面的下采样模块输出特征图大小为 ( 28 , 28 , 1024 ) (28,28,1024) (28,28,1024),经过反卷积操作(up-conv 2x2)得到大小为 ( 56 , 56 , 512 ) (56,56,512) (56,56,512)的特征图,即尺寸扩大一倍,通道数减半。之后,将左侧下采样模块输出的 ( 64 , 64 , 512 ) (64,64,512) (64,64,512)图像进行复制并中心裁剪(copy and crop)同样转化为 ( 56 , 56 , 512 ) (56,56,512) (56,56,512)大小,并与之拼接得到 ( 56 , 56 , 1024 ) (56,56,1024) (56,56,1024)大小的特征图(可见,此拼接仅是通道方向的拼接)。代码实现:
# 上采样中反卷积操作的实现
self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512
同理也可得到其他反卷积操作的实现:
self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256
self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128
self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64
右半部分卷积操作的代码实现:
【第一次卷积】
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512self.relu6_1 = nn.ReLU(inplace=True)self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512self.relu6_2 = nn.ReLU(inplace=True)
【第二次卷积】
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256self.relu7_1 = nn.ReLU(inplace=True)self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256self.relu7_2 = nn.ReLU(inplace=True)
【第三次卷积】
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128self.relu8_1 = nn.ReLU(inplace=True)self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128self.relu8_2 = nn.ReLU(inplace=True)
【第四次卷积】
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64self.relu9_1 = nn.ReLU(inplace=True)self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64self.relu9_2 = nn.ReLU(inplace=True)
【第五次卷积】
# 最后的conv1*1self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0) #64x388x388->2x388x388
中心裁剪操作的实现:
# 中心裁剪,def crop_tensor(self, tensor, target_tensor):target_size = target_tensor.size()[2]tensor_size = tensor.size()[2]delta = tensor_size - target_sizedelta = delta // 2# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]
【第一次上采样+拼接】
# 第一次上采样,需要"Copy and crop"(复制并裁剪)up1 = self.up_conv_1(x10) # 得到56*56*512# 需要对x8进行裁剪,从中心往外裁剪crop1 = self.crop_tensor(x8, up1)# 拼接操作up_1 = torch.cat([crop1, up1], dim=1)
【第二次上采样+拼接】
# 第二次上采样,需要"Copy and crop"(复制并裁剪)up2 = self.up_conv_2(y2)# 需要对x6进行裁剪,从中心往外裁剪crop2 = self.crop_tensor(x6, up2)# 拼接up_2 = torch.cat([crop2, up2], dim=1)
【第三次上采样+拼接】
# 第三次上采样,需要"Copy and crop"(复制并裁剪)up3 = self.up_conv_3(y4)# 需要对x4进行裁剪,从中心往外裁剪crop3 = self.crop_tensor(x4, up3)up_3 = torch.cat([crop3, up3], dim=1)
【第四次上采样+拼接】
# 第四次上采样,需要"Copy and crop"(复制并裁剪)up4 = self.up_conv_4(y6)# 需要对x2进行裁剪,从中心往外裁剪crop4 = self.crop_tensor(x2, up4)up_4 = torch.cat([crop4, up4], dim=1)
2.3完整代码

import torch
import torch.nn as nnclass Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64self.relu1_1 = nn.ReLU(inplace=True)self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64self.relu1_2 = nn.ReLU(inplace=True)self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128self.relu2_2 = nn.ReLU(inplace=True)self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256self.relu3_1 = nn.ReLU(inplace=True)self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256self.relu3_2 = nn.ReLU(inplace=True)self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512self.relu4_1 = nn.ReLU(inplace=True)self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512self.relu4_2 = nn.ReLU(inplace=True)self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024self.relu5_1 = nn.ReLU(inplace=True)self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024self.relu5_2 = nn.ReLU(inplace=True)# 接下来实现上采样中的up-conv2*2self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512self.relu6_1 = nn.ReLU(inplace=True)self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512self.relu6_2 = nn.ReLU(inplace=True)self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256self.relu7_1 = nn.ReLU(inplace=True)self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256self.relu7_2 = nn.ReLU(inplace=True)self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128self.relu8_1 = nn.ReLU(inplace=True)self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128self.relu8_2 = nn.ReLU(inplace=True)self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64self.relu9_1 = nn.ReLU(inplace=True)self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64self.relu9_2 = nn.ReLU(inplace=True)# 最后的conv1*1self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)# 中心裁剪,def crop_tensor(self, tensor, target_tensor):target_size = target_tensor.size()[2]tensor_size = tensor.size()[2]delta = tensor_size - target_sizedelta = delta // 2# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]def forward(self, x):x1 = self.conv1_1(x)x1 = self.relu1_1(x1)x2 = self.conv1_2(x1)x2 = self.relu1_2(x2) # 这个后续需要使用down1 = self.maxpool_1(x2)x3 = self.conv2_1(down1)x3 = self.relu2_1(x3)x4 = self.conv2_2(x3)x4 = self.relu2_2(x4) # 这个后续需要使用down2 = self.maxpool_2(x4)x5 = self.conv3_1(down2)x5 = self.relu3_1(x5)x6 = self.conv3_2(x5)x6 = self.relu3_2(x6) # 这个后续需要使用down3 = self.maxpool_3(x6)x7 = self.conv4_1(down3)x7 = self.relu4_1(x7)x8 = self.conv4_2(x7)x8 = self.relu4_2(x8) # 这个后续需要使用down4 = self.maxpool_4(x8)x9 = self.conv5_1(down4)x9 = self.relu5_1(x9)x10 = self.conv5_2(x9)x10 = self.relu5_2(x10)# 第一次上采样,需要"Copy and crop"(复制并裁剪)up1 = self.up_conv_1(x10) # 得到56*56*512# 需要对x8进行裁剪,从中心往外裁剪crop1 = self.crop_tensor(x8, up1)up_1 = torch.cat([crop1, up1], dim=1)y1 = self.conv6_1(up_1)y1 = self.relu6_1(y1)y2 = self.conv6_2(y1)y2 = self.relu6_2(y2)# 第二次上采样,需要"Copy and crop"(复制并裁剪)up2 = self.up_conv_2(y2)# 需要对x6进行裁剪,从中心往外裁剪crop2 = self.crop_tensor(x6, up2)up_2 = torch.cat([crop2, up2], dim=1)y3 = self.conv7_1(up_2)y3 = self.relu7_1(y3)y4 = self.conv7_2(y3)y4 = self.relu7_2(y4)# 第三次上采样,需要"Copy and crop"(复制并裁剪)up3 = self.up_conv_3(y4)# 需要对x4进行裁剪,从中心往外裁剪crop3 = self.crop_tensor(x4, up3)up_3 = torch.cat([crop3, up3], dim=1)y5 = self.conv8_1(up_3)y5 = self.relu8_1(y5)y6 = self.conv8_2(y5)y6 = self.relu8_2(y6)# 第四次上采样,需要"Copy and crop"(复制并裁剪)up4 = self.up_conv_4(y6)# 需要对x2进行裁剪,从中心往外裁剪crop4 = self.crop_tensor(x2, up4)up_4 = torch.cat([crop4, up4], dim=1)y7 = self.conv9_1(up_4)y7 = self.relu9_1(y7)y8 = self.conv9_2(y7)y8 = self.relu9_2(y8)# 最后的conv1*1out = self.conv_10(y8)return out
if __name__ == '__main__':input_data = torch.randn([1, 1, 572, 572])unet = Unet()output = unet(input_data)print(output.shape)# torch.Size([1, 2, 388, 388])
三、实战案例
准备复现论文:点击跳转
准备复现项目:点击跳转








![[笔记]2024大厂变频器,电机参数一览](https://i-blog.csdnimg.cn/direct/e10ff6fab8dd4630bb6e03f4e3033bf6.png)
![灵当CRM index.php接口SQL注入漏洞复现 [附POC]](https://i-blog.csdnimg.cn/direct/079763a4ee7c4281be9214b25bf9e402.png)