问题
1.你知道当你打开游戏加载存档时候计算机是在做什么吗?
由于你的CPU只有在数据被加载到DRAM的时候才可以工作,所以当你需要用数据的时候,数据会从SSD复制到DRAM这一过程需要时间,所以会有加载(所有3D模型、纹理和你游戏状态等)的过程。
2.为什么要使用SSD和DRAM两种内存呢?
那是因为SSD是将数据永久的存储在由一万亿(a trillion)个所有的存储单元组成的大规模3D阵列中,造就了TB的存储空间;而DRAM是将数据临时存储在由数十亿(a billion)个微小电容存储单元组成的二维阵列中,造就了GB的存储器。
从SSD读写数据的速度是50微妙,而DRAM的读写速度是17纳秒,是SSD速速的3000倍。 打比方就是,一架超音喷气机以3马赫的速度前进和一只乌龟进行比赛。
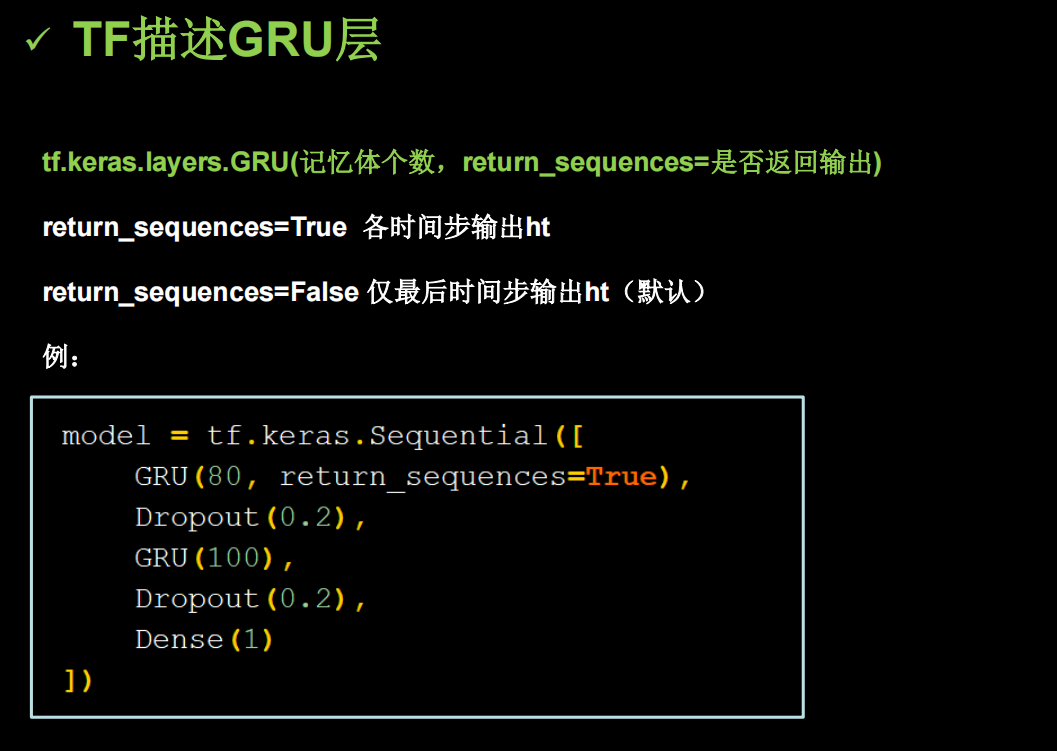
图1是一个有8个芯片的DRAM条

16GB DRAM条
图2是一个尺寸较小的SSD

2TB SSD
总结:计算机可以在SSD上存储TB数据,先花费几秒将数据从SSD复制到DRAM(在使用数据之前就预先移动它,进行预取(prefetching)),再花费几纳秒来访问DRAM上的数据。
本文将讲述CPU是如何跟存储器们进行通信并将数据从SSD移动到DRAM上的;然后将打开一个DRAM微芯片看看数十亿的存储单元是如何组织成库的,以及数据是如何被写入和从存储单元中读取出来的,在这个工程中我们将深入研究单个存储单元内部的纳米结构,并看到每个电容器如何在物理上存储1bit数据;最后我们将探索一些(内存技术)突破和优化点,比如突发缓冲器(burst buffer)和折叠式DRAM布局,他们使得DRAM以难以置信的速度移动数据。全篇以Crucial DDR5 为讨论对象。
3.CPU是如何跟存储器们进行通信的?
首先一个DRAM条被称为DIMM(Dual Inline Memory Module),每个DIMM上有8个DRAM芯片,主板上有4个DRAM插槽,DARM通过两个内存通道连接到CPU。左边的两个共享一个内存通道,右边的两个共享另一个内存通道。
CPU内部除了众多内核和许多其他的元素外,还有一个内存控制存储器(memory controller),它对DRAM进行管理和并与之通信。还有一个部分与插入M2插槽的SSD进行通信,还有与插入SATA连接器的SSD和硬盘进行通信,CPU利用他们和mapping table管理SSD到DRAM的数据流,以及从DRAM到Cache Memory的数据流。
对于DDR5来说每个内存通道被分成两个部分:Channel A和 Channel B,使用32条数据导线一次独立传输32bits。通过21个额外的数据导线携带一个地址和读取和写入数据的位置。并使用7个控制信号线转发命令。
地址和命令被发送到Channel A和Channel B上的所有四个芯片,并由他们共享。32个数据线导线在各芯片上进行分配,因此每个芯片一次只能读或写8位。
主板为DRAM提供powers ,由Power Management Chips控制。DRAM微芯片内部有一个裸芯片(die),一个DRAM die 由8个bank group组成,每个bank group有4个banks,每个bank里面都有一个高65536,横8192个存储单元的巨大阵列。为了访问170亿个存储单元,我们需要31位的地址,前三位选择bank groups,后两位选择bank,剩下的16位地址选择65536中确切的行,因为每个芯片一次只能读或写8位,所以8192列是由8个一组的存储单元组成的,所以最后的10位用来确定列(8192 / 8 = 2^10),优化:31位地址被分成两部分RAS(Row Address Strobe)和CAS(Column Address Strobe),并且只用21条导线来发送,先发送RAS,再发送CAS。
4.裸芯片内部是啥样的?
裸芯片又叫做集成电路,是在直径100毫米的硅晶片制造的,每片硅晶片上有2500个左右的裸芯片,每个裸芯片上有数十亿个纳米级的存储单元(memory cell),每个memory cell被称为1T1C单元(1 Transitor 1 Capacitor, 1晶体管 1电容),大小为十几纳米,memory cell内部如下:

一个电容器,以电荷或电子的形式存储1比特数据;晶体管用来访问和读写数据。如果电容被电子充电到1v,它就是二进制的1;如果没有电荷处于0v就是二进制的0,所以电容只能容纳1bit数据。“字节线”连接到晶体管的栅极,"位线"连接晶体管通道的另一侧。
施加电压使晶体管导通,电子可以留过通道,从而使电容器连接到位线这使我们可以给电容充电,写下一个1;或者给电容放电,写一个0。当字线关闭,晶体管被关闭,电容与位线隔离,从而保存了之前写入的数据或电荷。因为晶体管特别小,只有十几纳米宽,电子会慢慢在通道内泄露,所以电容需要被刷新(具体刷新方式后面指出)。
当一个字节线被激活只有该行的所有电容连接到其相应的位线,从而激活该行所有的存储单元,在任何时候只有一行处于激活状态,因为如果有多行激活,一列中的多个电容会互相干扰。
1.前5位选择库;
2.接下来的16位被发送到Row Decoder(行解码器)以激活单个行,从而打开该行的所有晶体管,并将8192个电容连接到位线上,同时其他行全部处于关闭状态。
地址剩余10位会被送到Column Multiplexer(列复用器),多路复用器接受顶部的8192位线,并根据10位地址将一组特定的8位线连接到底部的8个输入和输出I/O导线
DRAM Control
为了刚好理解 Reading Writing Refreshing 让我们线了解两个元素,每一位线底部添加一个Sense Amplifier(感应放大器),和列复用器外添加读取和写入驱动(各一个)
读(Reading)
1.读取命令和31位地址从CPU发送到DRAM上
2.前五位选择一个特定的库
3.关闭该组所有的字节线(隔离所有电容)
4.将所有8000左右的位线预充到0.5v
6.16位地址打开一个行
7.情况1:如果一个电容持有1并被冲到1v,那么这些电荷就会从电容流向0.5伏的位线上,导致位线电压增加,感应放大器能检测到这种电压的轻微变化,并将位线上的电压一直推高到1v。
情况2:如果一个电容中存储了0,电荷就会从位线流到电容,0.5v的比特线电压就会下降,感应放大器能检测到这种电压的轻微变化,并将位线电压下降到0v或接地。
8000多条位线都根据电容中存储的电荷量被驱动到1/0 v,OPEN Row
8.列地址复用器使用10位列地址,来连接相应的8个位线到读取驱动器
9.最后通过8条数据导线将8个值和电压发送给CPU
写(Writing)
1.写入命令和31位地址从CPU发送到DRAM上
2.前五位选择一个特定的库
3.关闭该组所有的字节线(隔离所有电容)
4.将所有8000左右的位线预充到0.5v
6.16位地址打开一个行
7.情况1:如果一个电容持有1并被冲到1v,那么这些电荷就会从电容流向0.5伏的位线上,导致位线电压增加,感应放大器能检测到这种电压的轻微变化,并将位线上的电压一直推高到1v。
情况2:如果一个电容中存储了0,电荷就会从位线流到电容,0.5v的比特线电压就会下降,感应放大器能检测到这种电压的轻微变化,并将位线电压下降到0v或接地。
8000多条位线都根据电容中存储的电荷量被驱动到1/0 v,OPEN Row
8.列地址复用器使用10位列地址,来连接相应的8个位线到写入驱动器(包含了CPU沿着数据导线发送并要求写入的8个bit)
9.写入驱动比感应放大器强的多,它可以覆盖在位线上的任何电压,并将位线上的电压驱动到1、0伏写入。
说明:
1.写入和读取是使用channel memory 上四个芯片同时进行的,他们使用相同的31位地址和命令线,但是每个芯片都有不同的数据线。
2.DDR5的二进制1的电压实际是1.1v,而位线预充电电压是这些电压的一半,在写入和刷新高电压的时候,大概1.4v的电压被施加并存储,在各电容中以获得二进制的1
3.bank groups ,banks,bitlines,wordlines数量分别是8,32,8192,65536
刷新(Refreshing )
由于晶体管特别小,会导致电容的电量产生泄露,为了保证数据正确就需要进行刷新操作,具体步骤如下:
Row Closing->Bitline Prechargeing->Next Row Opening->Sense Amplifer Refreshing
一行接一行的做,每行大约需要50ns,把53336行做完需要3ms,每个库64ms刷新一次
DRAM速度快的惊人的突破和优化(的技术)
在Row Hit的情况下,我们直接跳过打开行的步骤,只用10列的地址来复用一组不同的8列或位线,将他们连接到Write 或 Read Driver从而节省不少时间;
1.Column Address(Select/Multiplex[CAS])
2.Access 1T1C Cells(Read or Write Data using the Data IO lines)
在Row miss的情况下,指下一个地址是针对不同的行,需要DRAM需要进行如下操作:
1.Row Closing(Isolate All 1T1C Cells)
2.Bitline Prechargeing
3.Row Opening(Using Row Address & Sense Amplifiers[RAS])
4.Column Address(Select/Multiplex[CAS])
5.Access 1T1C Cells(Read or Write Data using the Data IO lines)
为什么有32个banks?
当Row Thrashing的时候效率低
每个库的行、列、感应放大器和解码器都是相互独立运行的,因此来自不同库的多个行可以被同时打开,以增加行命中的可能性,并减少CPU访问数据的平均时间,CPU可以一次性刷新一个bank group的一个bank,同时使用其他三个库从而减少刷新的影响。
为什么库的高度明显大于宽度?通过将所有库一个挨一个的合并在一起,你可以认为这个芯片上实际有6.5万行高,26.2万行宽。
DRAM 包装上的参数是什么意思?
DRAM包装上通常有4个数字用于行命中、预充电、行错过的时间相关参数。
1.Active to Percharge Delay [tRAS]:激活一行和接下来的预充电之前所需的时间
2.Precharge[tRP]:打开一行之前对位线进行预充电所需要的时间
3.RAS to CAS Delay[tRCD] : 所有行被隔离并且位线被预充电的情况下,打开一行所需要的时间
4.CAS Latency[CL]从发送一个打开了的行的地址起,到接受到存储在这些列的数据的时间
[tRAS]->Percharge Bitlines-> [tRP] [tRCD] [CL]
||||||||||||||||||||||||||||||||||||||||||||Data Out
容量单位有GB
每秒钟传输的数百万为单位的数据传输量
兆字节每秒的峰值数据传输率
什么是Burst Buffer?
读写 driver前添加一个128位的临时存储位置“Burst Buffer”,我们用128条导线连接到128位缓冲区位置,接下来10位列地址被分成两部分,6bit用于多路复用器,4bit用于突发缓冲器。
对于一个读取命令010101 1110,128个存储单元和位线将使用6个列的位线连接到突发缓冲器上,从而临时加载或者缓存128个值到burst buffer,通过使用缓冲区的4位,突发缓冲区的8个快速访问数据的位置被连接到读驱动器上(缓冲区是8*16的),并将数据发送给CPU,通过循环使用着4位,所有16组8位都能被读出,因此其突发长度位16。对于写入来说操作方法类似。
这种设计的好处是,每个微芯片中16组8位(缓冲区),总共1024bits(16 * 8 * 8 bankgroups),只要这些数据是相邻的就可以很快的被访问,读取或写入。
什么是Subarrays?
每一个bank (65536*8192是很大的导致了极长的字行和位行),特别是和每个memory cells相比的时候,因此这个庞大的阵列被分解成1024*1024小块,每个子阵列下面都有“中间感应放大器”,并对字线进行细分,并使用分层解码方案,通过位线的细分使得每个微小电容所连接的导线的距离和数量对应位线到感应放大器的扰动减少了,因此电容不需要很大,这种方法让我们减少8000多个晶体管的栅极和通道的负载,因此打开所有接入晶体管的时间也减少了。
折叠式DRAM架构?
将感应放大器放在每个位线底部,主要是让每列有两个位线连接到每个感应放大器上,以及让交替排列的存储单元连接到左边和右边的位线,因此让线的数量增加了1倍。
感应放大器内部?
当一个位线是1的时候,未激活的线将被这个交叉耦合反相器驱动为相反的值,即0,这两条位线被称为‘差分对’
Note:
SSD(固态硬盘,Solid-state drive )
DRAM(动态随机访问存储器,Dynamic Random-Access Memory )也可称为main memory(主内存)或working memory(工作内存)
1 TB=1,000,000,000,000 字节×8 位/字节=8,000,000,000,000 位
1 GB=1,000,000,000 字节×8 位/字节=8,000,000,000 位
1 microsecond = 10^-6 seconds
1 nanosecond = 10^-9 seconds
晶体管栅极(the gate of the transistor):在栅极施加电压可以使晶体管导通。
一个裸芯片里面有170亿个memory cell,(32 banks * 8192 Columns * 65536 Rows = 17179869184 1T1C),这些memory cells被排成大规模阵列,叫做 bank。
感应放大器是必要的,因为电容器非常小,而位线特别长。