在当今数字化转型的时代,大型语言模型(LLMs)已经成为了不可或缺的工具,它们在自然语言理解、生成和推理方面展现了非凡的能力。然而,这些模型普遍采用的是“一刀切”的方式,即对于相同的输入给予所有用户相似的响应。这种方式虽然能够满足大多数情况下的需求,但在需要根据个人偏好定制内容的情境下就显得力不从心了。为了解决这个问题,来自中国人民大学高瓴人工智能学院与百度公司的研究团队提出了一种名为PPlug的新颖个性化LLM模型。
个性化的重要性
随着技术的进步,人们对数字助手的要求越来越高,不再满足于通用化的答案,而是希望能够得到更加符合自己兴趣爱好的回应。因此,如何使LLMs具备个性化的输出能力变得尤为重要。现有的解决方案主要包括两种:一种是对每个用户的特定数据进行微调以创建独特的个性化模型;另一种则是通过检索用户的相关历史文本作为示例来引入个性化信息。但前者由于需要为每位用户单独训练模型而成本高昂,后者则可能因为打破了用户历史记录的连续性而导致效果不佳。
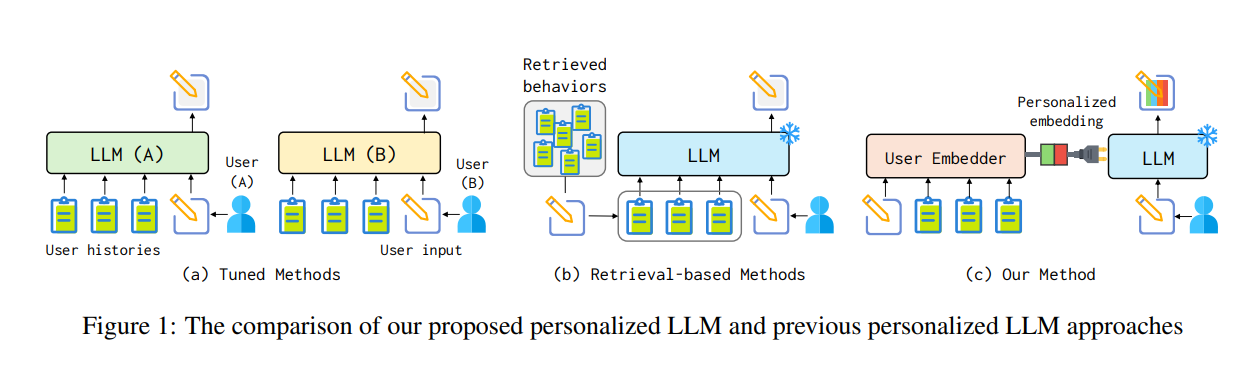
如上图所示,传统的基于微调的方法虽然可以实现一定程度上的个性化,但由于其高昂的成本限制了广泛应用的可能性。相比之下,基于检索的方法虽然降低了成本,但由于缺乏对用户整体风格和偏好的全面捕捉,往往只能达到次优的表现。
PPlug:创新之处何在?
为了克服上述问题,PPlug模型应运而生。它通过构建一个轻量级插件用户嵌入模块,对每位用户的所有历史上下文进行全面建模,并生成一个用户特定的嵌入向量。当这个嵌入被附加到任务输入时,LLM就能更好地理解和把握用户的习惯与喜好,从而产生更加个性化的输出结果,且无需调整模型自身的参数。这种方法不仅保持了用户历史记录的一致性和连贯性,还能有效反映用户的综合特征。
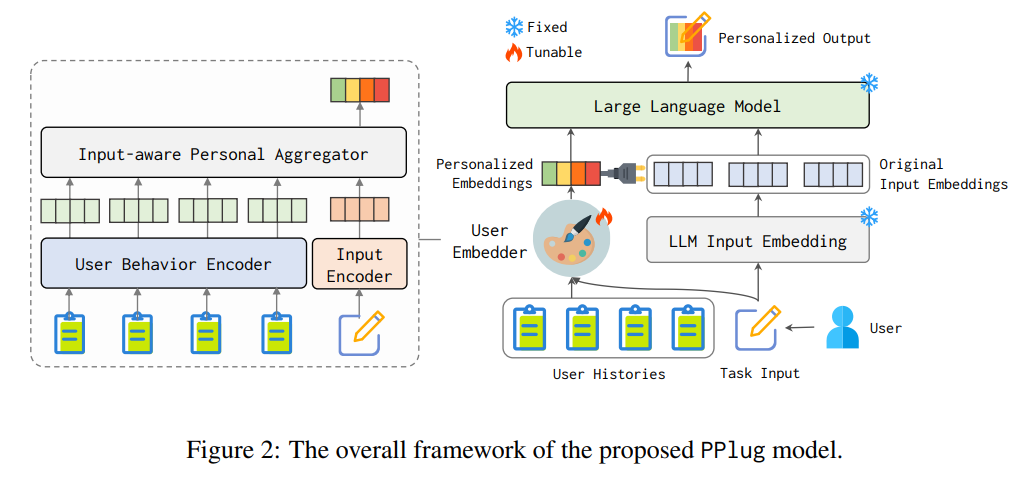
从图2可以看出,PPlug首先通过用户的历史行为生成一个代表该用户的嵌入向量,然后将此向量与当前的任务输入结合在一起送入LLM中。这样一来,模型就能够利用这一额外的信息来生成更加贴合用户喜好的内容。
实验验证
为了评估PPlug的实际效果,研究人员在多个任务上进行了广泛测试,包括但不限于情感分析、电影标签分类以及推文改写等。实验结果表明,在语言模型个性化基准测试(LaMP)中,PPlug相较于现有方法表现出了显著的优势,某些情况下甚至实现了高达35.8%的性能提升。
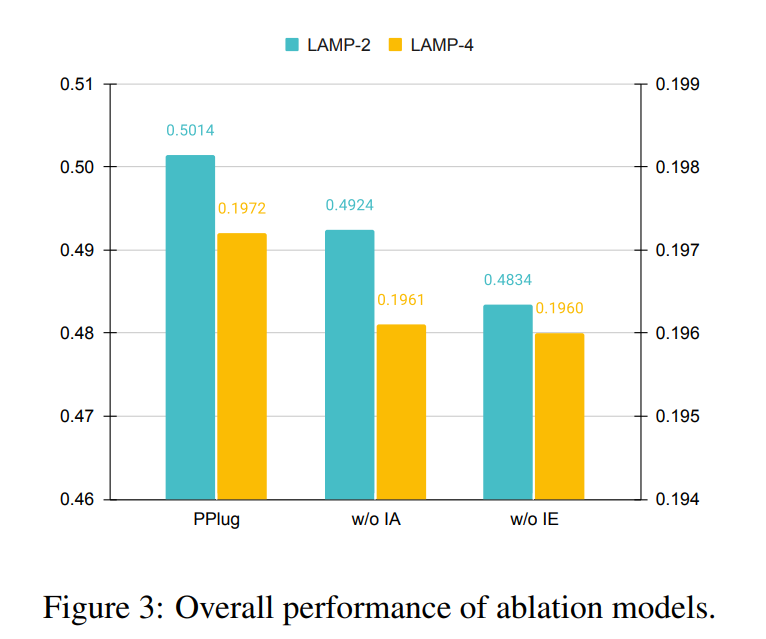
如图3所示,在各项评测指标上,PPlug均优于其他几种常见的个性化方法,特别是在那些要求高度一致性的任务上更是如此。这充分证明了PPlug在提高个性化质量方面的有效性。
结论
综上所述,PPlug提供了一种新颖有效的途径来增强LLMs的个性化能力,使其能够更好地服务于每一位用户。未来,随着更多类似技术的发展和完善,我们可以期待看到更加智能、更加人性化的AI系统出现在我们的日常生活中。而对于开发者而言,掌握并应用这样的前沿技术也将成为提升产品竞争力的关键所在。
本文通过对《LLMs+ Persona-Plug= Personalized LLMs》这篇论文的研究成果进行了深入浅出地解读,并结合论文中的图表形象地展示了PPlug模型的核心优势及其相对于传统方法的改进之处。希望这篇文章能够帮助大家更好地理解当前AI领域内关于个性化服务的研究进展,并激发起对未来科技发展的美好憧憬。
论文地址:https://arxiv.org/pdf/2409.11901
原文链接:https://mp.weixin.qq.com/s/VL1yj42Ynes-ndK6scvtyA
关于个性化大语言模型:PPlug分享结束,如果对文章感兴趣别忘了点赞、关注噢~