1. 迭代器、返回capacity、返回size、判空、c_str、重载[]和clear的实现
string类的迭代器的功能就类似于一个指针,所以我们可以直接使用一个指针来实现迭代器,但如下图可见迭代器有两个,一个是指向的内容可以被修改,另一个则是指向的内容不能被修改,那么我们就需要实现两个;这个实现其实很简单,我们只需要使用typedef或者using来实现,这里我就两个都实现出来,两个选其一即可;如下图和代码所示: 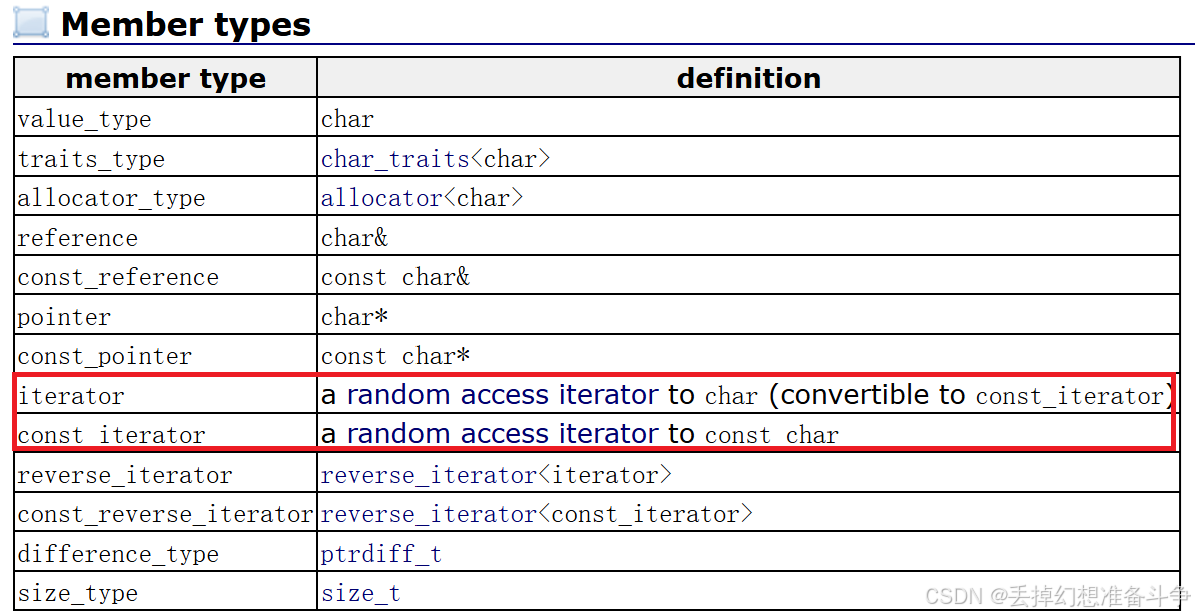
#include<assert.h>
class string
{
public:using iterator = char*;typedef char* iterator;using const_iterator = const char*;typedef const char* const_iterator;//模拟返回指向首元素地址的迭代器iterator begin(){return _str;}//模仿返回指向末尾地址的下一个地址iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}//返回capacitysize_t capacity()const{return _capacity;}//返回size值size_t size() const{return _size;}//判空bool empty()const{return _str[0] == '\0';}//c_strconst char* c_str() const{return _str;}//模拟方括号通过下表访问char& operator[](size_t pos){assert(pos < _size);return _str[pos];}const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}//clearvoid clear(){_str[0] = '\0';//_capacity = 0; //这个大小不能改,改了就废了,这是我犯过的一个错误_size = 0;}
private:char* _str;size_t _size;size_t _capacity;
};
2. 实现string类的构造和析构函数
一般实现类我们都需要先实现他的构造函数和析构函数,我们就先实现string类的构造函数,但string类的构造函数有很多个,我们就挑几个来实现,第一个是模拟 string s1("hello world");第二个是模拟string s1(s2)也就是拷贝构造;
2.1 string s1("hello world")的实现
string.h
class string
{
public://模拟string s1("hello world")string(const char* str = "");//模拟string s1(s2)string(const string& s);private:char* _str;size_t _size;size_t _capacity;
};string.cpp
string::string(const char* str):_size(strlen(str)){_capacity = _size;//一般都会多开一个空间给'\0'_str = new char[_size + 1];strcpy(_str, str);}//模拟string s1(s2)string::string(const string& s1){//我们要创建一个他的大小的空间_str = new char[s1._capacity + 1];strcpy(_str, s1._str);_capacity = s1._capacity;_size = s1._size;}代码的解释:
先来说第一个,有的人问为什么我们不把_capacity和_size的初始化都放到初始化列表里面去,可以尝试着说_size(strlen(str));_capacity(_size);_str(new char[_size+1])这样按着这个顺序来,是因为初始化列表走的顺序不是按初始化列表里的顺序来的,而是按声明的顺序来,如果说我们_size不是第一个声明的话,那么_capacity和_str都错了,可能会取得错误的值,所以我们只把_size放到里面的话就不会出现上面的那种情况, 在函数里面要动态开辟一块空间进行深拷贝(不进行深拷贝的后果前面有说这里就不过多阐述),然后直接用一个strcpy把内容复制到_str来即可;
第二个参数要用传引用避免进行拷贝构造调用,然后需要创建一块和s1一样大的空间,但他并不会给'\0'的顺序算入,所以我们需要+1;
注意!:上面的缺省参数要给char* str="";我们不能给NULL。
析构函数的实现:
string::~string(){delete[]_str;_str = nullptr;_size = 0;_capacity = 0;}3. 实现reserve(不是reverse)操作
reserve就是提前开空间,需要看具体什么意思的话可以去看前一篇c++文章介绍string的使用的;如下代码所示:
void string::reserve(size_t n){//开空间的话我们要判断n是否大于capacityif (n > _capacity){char* temp = new char[n + 1];strcpy(temp, _str);delete[]_str;_str = temp;_capacity = n;}}注意:我们开空间后用一个temp来接收,把_str的内容复制到temp再释放掉_str,不然会造成内容泄漏;
4. 实现push_back和append操作
push_back:进行push_back操作前我们需要判断_str的空间是否足够,如果不够则需要扩容;扩容时按二倍扩容,所以我们需要用一个三目运算符来判断,如果_capacity=0的时候就无法进行二倍扩容操作,那就需要给他一直初始空间大小;如下代码所示:
void string::push_back(char ch){//检查空间if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;}append:append和push_back不一样,append可以插入一个字符串,但我们也是需要考虑空间问题,首先我们需要计算传入的字符串的长度,然后加上我们原有的长度看看是否大于我们的空间容量,如果大于则按二倍扩,但我们又需要考虑一个情况就是如果说二倍扩的空间还是没有我们传入字符串的长度加原有的长度大的话,我们就让他需要多少空间就给多少空间;
void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){size_t NewCapacity = 2 * _capacity;if (NewCapacity < _size + len)NewCapacity = _size + len;reserve(NewCapacity);}strcpy(_str + _size, str);_size += len;}5. 实现insert和erase操作
实现insert和erase的话我们需要对字符进行往前或者往后挪动,这也导致他们的效率不高;实现insert的时候也是需要和上面的一样扩容操作,当我们在hello world中间插入一个this的时候,我们把world挪到后面去给this腾出4个位置;如下代码所示:
string& string::insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){size_t Newcapacity = 2 * _capacity;if (_size + len > Newcapacity)Newcapacity = _size + len;reserve(Newcapacity);}size_t end = _size + len;while (end > pos + len - 1){_str[end] = _str[end - len];--end;}for (size_t i = 0; i < len; i++){_str[pos + i] = str[i];}_size += len;return *this;}erase也同理,但erase有两种情况,第一种是在pos位置删除len长度的时候如果说len长度大于pos后面的长度的时候那就直接让pos位置为'\0',因为\0就是意味着结束,第二种情况则是len小于pos后面的长度,那就需要挪动数据;如下代码所示:
string& string::erase(size_t pos, size_t len){assert(pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{size_t end = pos + len;while (end <= _size){_str[end - len] = _str[end];++end;}_size -= len;}return *this;}6. 实现npos和find的操作
npos在string里面代表最大的值但他是静态成员、不能被修改、还是一个无符号整型,那就直接给他一个-1就可以;如下代码所示:
#include<assert.h>
class string
{
public:const static size_t npos = -1;private:char* _str;size_t _size;size_t _capacity;
};注意!:这里为什么可以给缺省值-1是因为加了const,如果不加const是无法给的,因为被static修饰的变量是不走初始化列表,在定义的时候给值就是给缺省参数,缺省参数是给初始化列表使用的;
find操作实现:find有两个,一个是从指定位置开始找,另一个则是从头遍历到尾,直接进行暴力遍历就可以实现;如下代码所示:
size_t string::find(char c, size_t pos )const{assert(pos <= _size);for (size_t i = pos; i < _size; i++){if (c == _str[i]){return i;}}return npos;} size_t string::find(const char* s, size_t pos )const{//我们要从pos位置找起那么就要_str+pos;assert(pos <= _size);const char* ptr = strstr(_str + pos, s);if (ptr == NULL){return npos;}elsereturn ptr - _str;}注意,这里ptr-_str的操作是指针-指针得到的是中间元素的个数即位置;
7. 实现getline操作
getline的操作是一直往字符串里输入数据,直到碰到输入特定的字符的时候才终止,因为是输入数据,所以需要使用流插入类型,和重载cin一样,并且在进行一下操作的时候我们还需要清楚原有的数据,举个例子如果说你不清楚的话,原先本身s1对象里就有hello world的数据了,当你想输入一个year的时候就会打印hello world year, 而string类里的getline是不会保留hello world的,所以我们先要进行clear操作;如下代码所示:
istream& getline(istream& is, string& s,char delim){s.clear();int i = 0;char buff[256];char ch;ch = is.get();//因为使用cin的时候当碰到' '和'\n'的时候就结束while (ch!=delim){buff[i++] = ch;if (i == 255){buff[i] = '\0';//因为是数组,模拟存储字符串的时候不会有\0s += buff;//因为用+=会自行进行扩容i = 0;}ch = is.get();}if (i > 0){buff[i] = '\0';s += buff;}return is;}代码解释:char buff[255]想做的是减少扩容操作,因为如果进行过多的扩容操作就会导致运行效率降低,那我们就可以预先给他开辟256个空间,然后进行接收输入的数据,但我们不能使用cin,因为cin碰到空格的时候就会结束,所以我们可以使用输入流里的get,然后就对输入的字符开始判断是否是特定字符,再往buff里面放,当i==255的时候,也就是剩下最后一个空间就需要给'\0';
8. 比较运算符重载
很简单,只要实现了两个后面都可以套用,直接上代码;
bool string::operator==(const string& s){return strcmp(this->c_str(), s.c_str());}bool string::operator!=(const string& s){return !((*this)==s);} bool string::operator<(const string& s){return strcmp(this->c_str(), s.c_str()) < 0;}bool string::operator<=(const string& s){return *this < s || *this == s;}bool string::operator>(const string& s){return !(*this <= s);}bool string::operator>=(const string& s){return *this > s || *this == s;}9.实现+=运算符重载
直接套用append和push_back即可;如下代码所示:
string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}
10.实现swap
std里面本身就有一个swap,为什么我们又要另外实现呢?原因是std域内的swap是一个模板,比如我们有两个自定义string类型s1 和s2, 那么传过去就成了会调用拷贝构造,还需要多次开辟空间,所以我们需要在类内实现;其实也是很简单的,我们直接调用std域内的swap对s1和s2的成员进行交换即可;如下代码所示:
void string::swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}void string::swap(string& s1, string& s2){s1.swap(s2);}11. 实现流插入>>和流提取运算符重载<<
流提取简单,其实就是直接打印_str里的值就可以;如下代码所示:
ostream& operator<<(ostream& os, const string& str){for (size_t i = 0; i < str.size(); i++){os << str[i];}return os;}流插入也简单,和append差不多,但是和append不同的一点是,append是遇到特定字符的时候就结束,而流插入cin的则是碰到空格或者换行符的时候结束;如下代码所示:
istream& operator>>(istream& _cin, string& s){s.clear();int i = 0;char buff[255];char ch;ch = _cin.get();//因为使用cin的时候当碰到' '和'\n'的时候就结束while (ch != ' ' && ch != '\n'){buff[i++] = ch;if (i == 255){buff[i] = '\0';//因为是数组,模拟存储字符串的时候不会有\0s += buff[i];//因为用+=会自行进行扩容i = 0;}ch = _cin.get();}if (i > 0){buff[i] = '\0';s += buff;}return _cin;}12. 赋值运算符的重载
赋值运算符的重载有两种情况,举个例子吧,string s1("hello world");string s2("man!");第一种是s1 = s2,第二种是s1 = s1(我也不知道这个写来有什么意义,但string类支持这个操作)我们需要分类讨论这两个,因为赋值运算符的重载是需要释放原空间接收新空间,例如s1 = s2就需要释放s1的空间然后把s2的空间和值给s1,但如果是s1=s1的话,s1的空间释放了就没法进行,所以要分类讨论;如下代码所示:
string& string::operator=(const string& s){//赋值运算符的需要释放原来的空间再复制新的if (this != &s) //这是在说他们指向的不是同一块空间所以进去{delete[]_str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}上面那个太复杂了,下面这个是现代写法:
//现代写法string& string::operator=( string s){swap(s);return *this;}举个例子s1.swap(s2);s2出了函数栈帧自动销毁,然后这里是传值传参不会影响到实参;
END!