今年以来,商家营销工具业务需求井喷,需求数量多且耗时都比较长,技术侧面临很大的压力。因此这篇文章主要讨论营销工具前端要如何应对这样大规模的业务需求。

问题拆解
我们核心面对的问题主要如下:
1. 人力有限
我们除了要支撑存量页面的日常迭代,还需要完成大量页面的新增,虽然有短期的人力支援,但总体还是捉襟见肘。
2. 如何保障交付质量和体验?
商家营销工具核心的业务目标之一是体验优化,因此对前端交付页面的质量和体验,都有一定要求。而我们有大部分人力是新人,如何保证交付质量和体验?
3. 支援撤出后,长尾需求如何应对?
新增页面的持续优化迭代会带来大量长尾需求。支援撤出后如何应对?
问题总结一句话其实就是:如何高效高质量地支撑相比以往更多的需求。
最初的思路其实很简单:提高代码复用率。
这样:
1. 一方面提高了研发效率,以应对人力瓶颈。
2. 另一方面能通过沉淀下来的标准代码,拔高整体交付产物的质量和体验下限。

统一产品形态与设计规范
前端提高代码复用率的方式,最常用的就是组件沉淀(基础组件基本配套齐全,这里主要指业务组件)。但组件沉淀的实际效果,会受很多因素的影响:
1. 业务形态是否稳定?
针对一个业务场景沉淀的组件,会因该场景的业务调整而面临改造,不稳定的业务形态,会降低组件沉淀的收益。“三天两变”的业务形态下沉淀组件,可能会带来负收益。
2. UI是否稳定?
道理和业务形态相同。
我们当然有一些方法能够尽可能降低这些因素带来的影响。比如可以将 业务逻辑 与 UI 分离,让他们可以独立变更,互不影响;也可以对组件做更多层次更抽象的封装,来让组件能“灵活”地适应不同场景。
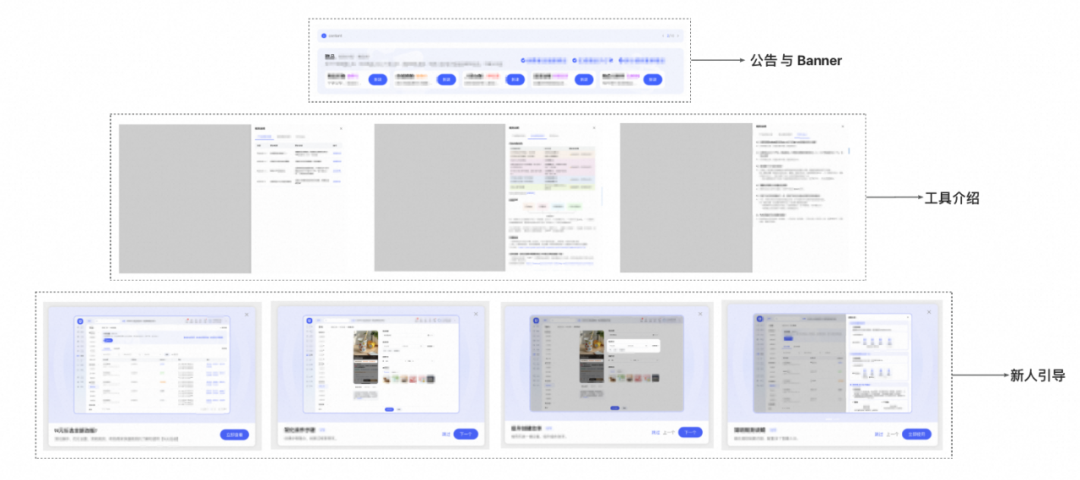
但在螺丝壳里做道场,不如考虑从源头解决问题。下边是几个存量工具的PC端页面:
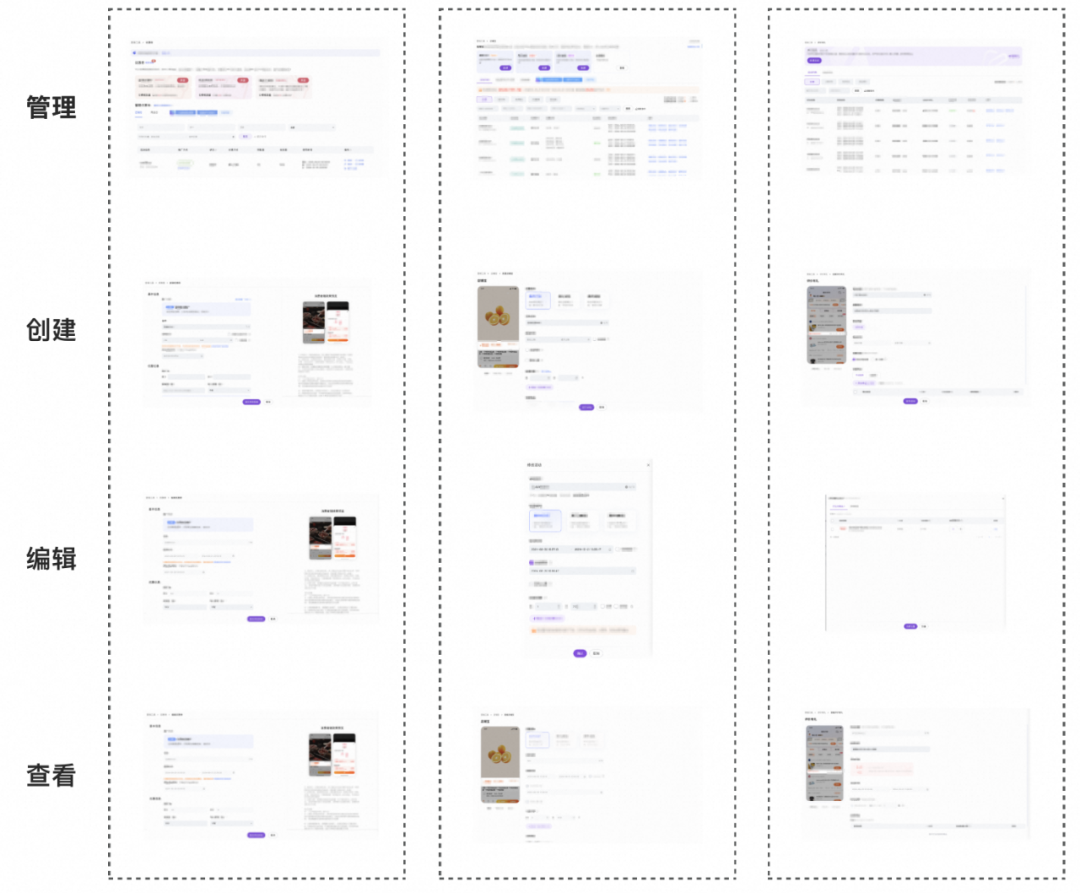
营销工具的产品形态特点鲜明:
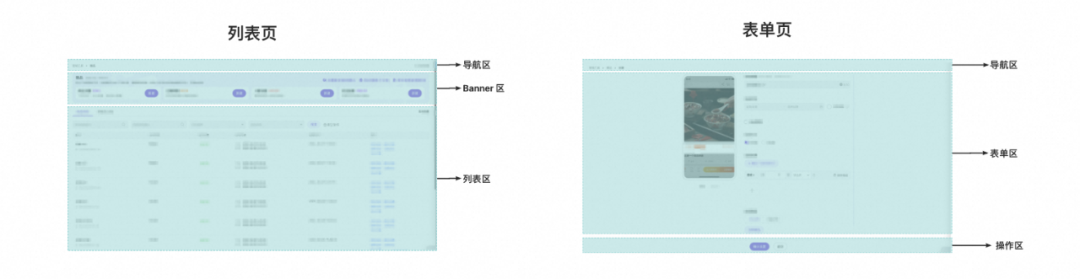
1. 大部分工具都有 管理、创建、编辑、查看 四种能力,主要通过 列表页 和 表单页 两个页面来承载。
2. 列表页、表单页各模块的样式和交互模式非常相近。比如列表页顶部的Banner区,创建页的图片预览区。
如果能统一部分模块甚至页面框架的交互模式和样式,那么根据这些场景沉淀的组件,可复用性是很高的。
因此我们对营销工具域内,可规范化的场景做了枚举。去推动产品和设计统一产品形态和设计规范。出乎意料的顺利,产品、设计、前端 三方很快达成了一致,最终我们确定了营销工具域产品&设计规范。
规范的种子其实早已种下,只是缺了一个浇水的人。
▐ 思考
当统一产品形态与设计规范这件事确定以后,技术上我们有了一些新的思路和要面对的问题:
接口的数据模型是否也能形成规范,我们可以将接口调用与数据处理也内置在组件内,做到更极致的提效。
不止于组件,我们是否可以将大的业务区块或者整个页面模版都沉淀下来?
一些数据源会频繁变更,业务逻辑又非常简单的模块,是否可以完全交由PD自行配置,免去迭代的开发工作量?
过去其实也有约定过一些产品&设计的规范,但都由于 规范粒度不够细、实践过程中产品&设计没有严格遵守规范、一遇到特殊定制逻辑就选择跳出规范等问题,导致最终各工具之间又逐渐趋于差异化,如何避免这种问题?

架构设计
基于上述的思考,我们针对商家营销工具场景,设计了一套技术架构,划分为以下几层:
页面容器层:这一层,我们用来收敛不同工具之间的共性部分。
-
如:页面UI框架、可配置化的模块(如列表页顶部Banner区)、请求方法、工具方法、公共依赖等。
场景模版层:这一层,我们用来收敛一些 共性 > 差异 的业务模块中的共性部分。它是可选的,当页面中没有 共性 > 差异 的模块时,那也就无需拆分出这一层。
-
如:首页的列表区块(包含:Tab区、筛选表单、列表、分页器),其中Tab切换、分页、筛选、样式布局等在不同工具下都是一致的,将这些逻辑固定下来,同时在模块中预留一些拓展点,支持不同工具定制,它就成为了列表场景的模版。
业务定制层:这一层,用来实现不同工具之间的差异部分。
-
如:在列表页,基于列表模版预留的拓展点进行定制;在表单页,实现单工具创建、编辑、查看态表单。
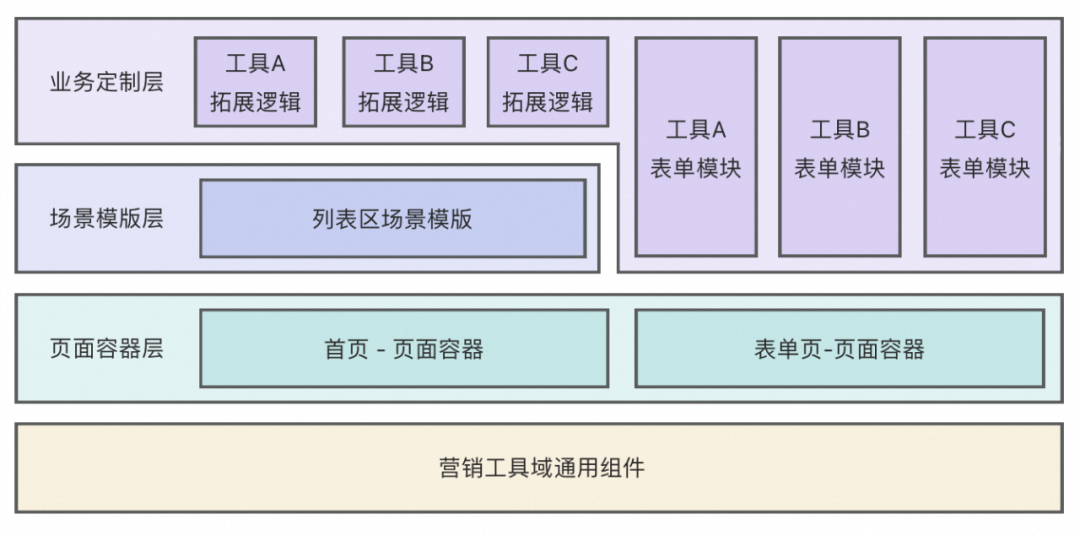
这样的架构设计:
1. 实现了我们最初的提高代码复用率的目标,提升开发效率,保障质量和体验下限。
2. 实现了一些共性需求或规范的更新,一次开发,整个业务域生效。
3. 会导致代码变更的影响范围被放大,页面容器层、场景模版层的变更,会一次影响到多个工具。但这是一把双刃剑:
对开发在变更代码时提出了更高的要求。
也让产品设计变得更加谨慎,因为越规范的部分越底层,越底层的部分影响范围越大,增强了规范的约束力。

架构串联
我们首先要面对的问题,是如何串联实现上述的三层架构。
参考微前端架构,我们可以先简单地将工具的共性部分放到一起作为主应用;而每个工具的定制部分作为微模块。
在主应用中,我们通过路由区分不同工具,以加载不同工具的微模块。同时我们会维护一个页面上下文,在微模块加载后注入进去,用来实现模块与主应用之间的数据通信。

我们可以快速的搭建出一个示例:
主应用:
import { MicroModule } from '@ice/stark-module';// 路由与为模块的映射
const MPathToModuleBaseInfo = {'/工具A/home': { name: '工具A-home-module', url: 'https://xxx.xxx.xxx' },'/工具A/create': { name: '工具A-create-module', url: 'https://xxx.xxx.xxx' },...
}// 页面主应用页面
export default function App() {const [state, setState] = useState(1);// 页面上下文const pageContext = useMemo(() => ({ setState }), []);return (...// 渲染微模块<MicroModulemoduleInfo={MPathToModuleBaseInfo[location.pathname]}// 将上下文作为 prop 注入进微模块pageContext={pageContext}/>;... )
}微模块:
export default function Module(props) {// 获取上下文const { pageContext } = props || {};const handleClick = () => {// 与页面容器做数据通信pageContext.setState((preState: number) => preState + 1);}// 渲染业务定制模块return (<button onClick={handleClick}>state + 1</button>);
}到这里,我们实现了页面容器层和业务定制层的串联。但场景模版层,有些无处安放。
将它放进主应用中?不太合适,因为场景模版的迭代频率是高于页面容器的,将这两层耦合在一起,会扩大场景模版的影响范围,增大维护压力。
将它放进微模块中?也不合适,这样每个工具都会单独维护一份场景模版,失去了这一层抽象的意义。
有个简单的方式能解决上述问题,将场景模版封装成一个 npm 包,在每个微模块中引入。但这个方案的缺陷在于,每次场景模版迭代,需要到各个工具中去升级npm版本。发布工作量让人头疼;同时还很难管控版本统一,很容易出现多个版本同时在线上运行的情况。
我们在微内核架构中,找到了灵感。这个名字可能会有点陌生,但如果叫它插件系统,大家应该就很熟悉了。像我们工作中经常接触的 Chrome、VS Code,就拥有强大的插件系统。
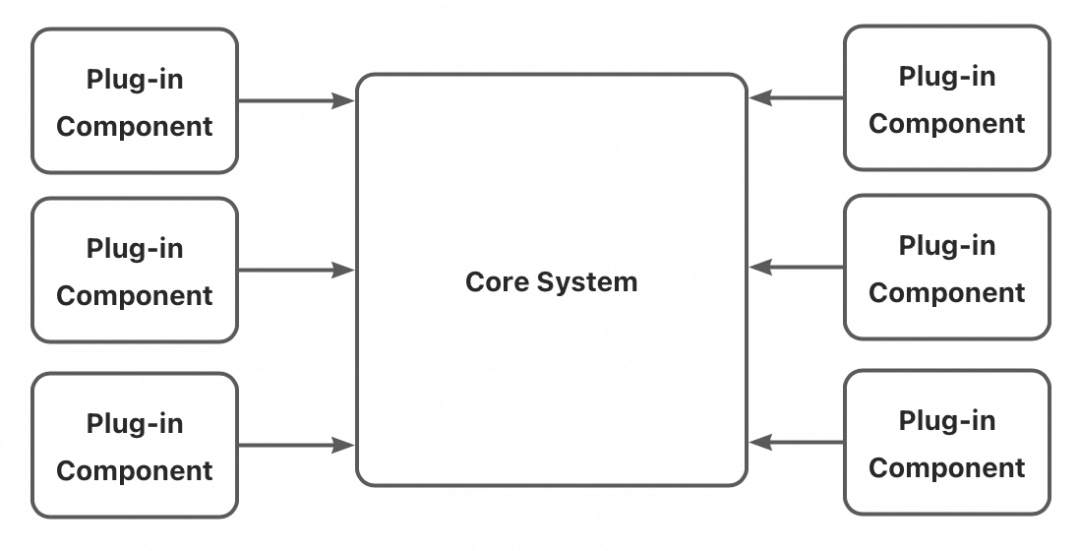
在微内核架构下,应用被分割为独立的插件模块和核心系统。在我们的设计中,场景模版就可以被看作是一个业务场景下的核心系统;而每个工具对场景模版的定制拓展,就是一个个插件。下边是一段示例:
插件基座:
// 路由与为插件资源的映射
const MPathToPluginInfo = {'/工具A/home': { url: 'https://xxx.xxx.xxx' },...
}
// 核心系统
export default function CoreApp() {const [tabList, setTabList] = useState([]);// 插件API生成const pluginApi = useMemo(() => {return {tabs: {add: setTabList;},}}, []);// 加载并运行插件const pluginResult = useMemo(() => {const plugin = registerPlugin(MPathToPluginInfo[location.pathname]);plugin(pluginApi);}, []);// 核心系统内部渲染 Tab List 的逻辑return (<Tab>{tabList.map((tab) => (<Tab.Item key={tab.key} title={tab.title}>{tab.content}</Tab.Item>))}</Tab>)
}插件模块:
function Content() {return <div>content</div>
}export default function plugin(api) {// 使用 api 对核心系统进行定制api.tabs.add((preState) => ([...preState, { key: 'demo', title: '标题', content: <Content /> }]))
}为了和上述微前端的实现结合,我们可以将核心系统作为一个常驻微模块由主应用加载。而加载插件的逻辑可以放在核心系统内部。
▐ 总结
到这里,架构的实现思路基本清晰了。
在表单页,我们可以直接通过 主应用 加载 微模块 的方式就能实现。
在列表页,我们针对列表场景,多做了一层抽象,将列表场景的共性逻辑封装成一个核心系统,各工具的差异逻辑则作为插件,对核心系统进行定制。通过 主应用 加载 核心系统,核心系统 加载 插件 的方式实现。
思路到最终实现,还有很多很多问题要解决。工程链路,渲染链路,发布链路,性能优化 等等。这也非一人之功,其中饱含了团队成员们的巧思,内容足以单开数篇文章,在本篇中就不做展开了。

分层实现
在上述架构下,开发业务定制层跟我们平常开发业务代码没什么区别,因此下边主要介绍 页面容器 和 场景模版 两层的一些实现思路。
▐ 页面容器层
UI框架
通常最底层的容器,是不耦合UI的。相比于页面逻辑,UI 的变化频率要高得多。耦合UI后,会导致容器要频繁迭代,影响健壮性。
但在统一了产品形态和设计规范以后,有很多页面框架层面的 UI 被固化下来,因此我们决定把整个页面框架的逻辑和UI都放进容器里。里边包含了:页面布局、骨架屏、Error兜底、权限校验 等等。

配置化
页面中同样存在一些UI一致,但是内容会频繁变化的模块,比如列表页顶部的Banner、公告、工具介绍、新人引导弹窗 等等。这些模块的变更,一般都是数据源的更新,因此我们决定把这些模块配置化,支持数据源远程下发;同时将配置产品化,将数据模型以表单形式表达,让PD能够自行修改,独立发布。
因已有配置产品化平台,接下来的工作就是对数据模型进行设计,并在项目中完成接入。
模块加载
在产品&设计规范统一后,我们可以,也应该把页面的UI框架固定下来。但出于对未来不确定性的担忧,我们在容器的实现上,给自己留了一些后路。
参考了一些C端搭建场景的容器设计,我们将页面按照垂直方向划分为一个个区块,通过一份配置进行渲染。区块与区块通常彼此独立,但也可以通过页面上下文或自建事件通信来实现交互。
import Entry from './components/Entry';
import Header from './components/Header';// 预设的本地区块
const MPresetNameToComponent = {'home-entry': Entry,'home-header': Header,
}const pageConfigs = [{ name: 'home-header', type: 'preSetComponent' },{ name: 'home-entry', type: 'preSetComponent' },{name: 'home-table-layout',type: 'microModule',moduleInfo: {...},},
]export default function App() {const pageContext = useMemo(() => {}, []);// 解析协议,渲染模块const renderModule = (config) => {const { name, type, moduleInfo } = config || {};if (type === 'preSetComponent') {const Component = MPresetNameToComponent[name];if (Component) {return <Component pageContext={pageContext} />}}if (type === 'microModule') {return (<MicroModule {...moduleInfo} pageContext={pageContext} />)}return null;}return pageConfigs.map((config) => renderModule(config));
}这份配置目前直接写死在容器中,但在需要时,我们可以将其改造为远程下发。
这样的渲染模式给页面容器带来了一定的灵活性,它支持了一个工具对页面框架层面的定制诉求。比如工具A想在页面Banner区上方,添加策略推荐模块。按照固定框架的方式实现容器,我们想要支持这样的诉求则需要迭代容器,同时对工具A做特判,来渲染策略推荐模块,这会使得容器越来越臃肿。但通过协议渲染,则不会有这样的问题。
▐ 场景模版层
目前,我们仅在列表页做了这一层抽象。在规范中,列表区被固定为四个部分:Tab 区、筛选表单、列表、分页器。

基础逻辑
Tab区包含的逻辑很少,我们在核心系统中定义好Tab区的数据源,并在插件中通过API对数据源进行定制即可。
最终方案中,在插件里定制数据源:
// 添加Tab1
api.appendItem({ extensionId: EExtensionId.xx, title: 'xxx', type: 'table' });
// 添加Tab2
api.appendItem({ extensionId: EExtensionId.xx, title: 'xxx', type: 'table' });筛选表单本质是列表接口入参的表达,因此逻辑上相对简单,很少有联动,且表单项的类型都很固定,最常用的就是 Input、Select、DatePicker、Radio 这几种,很适合通过 JSON Schema 的方式渲染,而这种渲染方式,已经有很成熟的解决方案了,比如 formily。我们也是基于它实现的。在核心系统中,我们完成表单实例的创建和提交的监听,插件只需要专注于声明表单项。
最终方案中,在插件里声明筛选表单项:
ExtensibleTable.modifyFilter(() => {return (form) => {// form 为核心系统中注入的表单实例return {// 表单项1A: {type: 'string','x-decorator': 'FormItem','x-component': 'Input','x-component-props': {placeholder: 'A',}},// 表单项2B: {type: 'number','x-decorator': 'FormItem','x-component': 'Select',enum: [{ label: 'xxxx', value: 0 },],'x-component-props': {placeholder: 'B',hasClear: true,}},}}
})列表最核心的逻辑其实就是分页、筛选。我们已经完成了筛选表单的定制并能获取到表单值,剩余只需要串联搜索、分页的交互,管理列表、分页器的状态即可。ahooks 的 useFusionTable 已经为我们封装的很完整了,我们在核心系统中将他集成了进来,而在开发插件时,我们只用声明列表接口。
最终方案中,在插件里声明请求方法:
const listXXX = () => {return fetch('https://xxx.xxx.xxx')
}ExtensibleTable.modifyActions((columns, ctx) => {return {search: {// 声明列表接口request: ({ current, pageSize, filterValue }) => {// filterValue 中每个 key 和声明的表单项一一对应return listXXX({ current, pageSize, filterValue });}}
});数据模型
上述的基础逻辑内置在核心系统中,已经能相当程度上减少列表区的开发工作量,但我们仍想更进一步。
列表核心是对服务端数据模型的表达,而数据模型又是对业务模型的抽象。在商家营销工具域内,不同工具之间有很多相似的业务模型,比如活动模型,它包含:活动名称、ID、时间、状态、绑定的商品等等字段信息。
在统一了产品形态和设计规范以后,我们顺其自然的想要推动服务端数据字段的统一。因此我们同样对可规范数据字段的场景进行了枚举,并以此去推动服务端统一数据字段与一些常用的功能型接口。最终我们达成了一致。
基于统一的数据,我们将部分列表单元格的渲染也内置到了核心系统中,根据插件中声明的单元格类型,核心系统自动去接口返回中找对应字段,并使用对应组件进行渲染。
最终方案中,在插件里声明列表列:
ExtensibleTable.modifyColumns((columns, ctx) => {return [// 活动信息模型 AA,对应字段 A、B、C{ title: '活动', 'x-component': 'AA', width: 180 },// 活动状态模型 BB,对应字段 D{ title: '活动状态', 'x-component': 'BB', width: 90 },// 活动时间模型 CC,对应字段 E、F、G{ title: '活动时间', 'x-component': 'CC', width: 180 },{title: 'xx',dataIndex: 'xx',cell: (value, index, record) => {// 该工具独有的单元格,自定义渲染},width: 240,},// 操作列数据模型 TT,对应字段 H{title: '操作',width: 150,'x-component': 'TT','x-component-props': { maxCol: 3, maxRow: 5 },},];});交互模型
到这里,列表的主要逻辑中还剩余最后一块拼图,操作列交互。在中后台系统中,列表的操作是逻辑繁重的部分。我们在产品&设计规范中,对操作列的交互类型也做了统一。常见的交互类型有:二次确认、复制链接、导出文件、跳转 等。
我们将一个交互恒定的部分在核心系统中实现,在需要变化的部分预留好拓展点,由插件进行定制。
同时一些功能型接口,比如文件导出等,我们也推动了服务端统一,这样在插件中我们只需声明业务参数,甚至无需封装接口调用方法。
最终方案中,在插件里定义操作交互:
ExtensibleTable.modifyRowActions((columns, ctx) => {return {// 自定义交互custom: (option, rowData, tableContext) => {// 操作的业务类型为 A 时,对应的交互if (option.type === 'A') {// do things}// 操作类型为 B 时,对应的交互if (option.type === 'B') {// do things}},// 二次确认交互doubleCheck: (option, rowData) => {let message = '';// 不同业务类型对应不同的提示文案if (option?.type === 'C') { message = 'CCC'; };if (option?.type === 'D') { message = 'DDD'; };return {message,onConfirm: () => {// 操作类型为 E,点击确认时要调用的接口if (option.type === 'E') {return fetch(params).then(() => {Message.success('成功');});}if (option.type === 'F') {return fetch(params).then(() => {Message.success('成功');})}},}},// 导出文件交互export: (option, rowData) => {let type = '';if (option?.type === 'G') type = 'GGG';if (option?.type === 'H') type = 'HHH';// 声明导出文件的业务参数,无需封装接口调用方法return {params: {type,}}},}
});
结语
基于上述这套方案开发的增量页面进行了研发效能核算。以使用常规方案开发的排期耗时为基准,最终的提效收益是很明显的,都在 50% 以上。
除了研发提效外,这套方案还带来了一些额外的收益:
1. 一些在工具之间有共性的需求,比如资损校验等,在统一了设计规范之后,将其集成进 页面容器层 或 场景模版层 能做到一次开发,所有工具生效;
2. 部分模块可完全交给产品配置,变更无需排期;
3. 拔高了交付页面的质量和体验下限,视觉一致性也得到了保障。
同时也引入了一些问题:
1. 架构复杂度提升很多,对稳定性和页面性能是一个考验;
2. 同时也对线上问题的排查、变更影响范围的评估带来了一定影响。
因此,未来这套方案目前能想到的迭代方向有几个:
1. 降低由架构引入的问题带来的影响;
2. 探索表单场景是否也能做场景模版层的抽象;
3. 提升存量页面需求开发的研发效率。

团队介绍
我们是淘天集团-营销中后台前端团队,负责核心的淘宝&天猫营销业务,搭建千级运营小二、百万级商家和亿级消费者三方之间的连接通道,在这里将有机会参与到618、双十一等大型营销活动,与上下游伙伴协同作战,参与百万级流量后台场景的前端基础能力建设,通过标准化、归一化、模块化、低代码化的架构设计,保障商家与运营的经营体验和效率;参与面向亿级消费者的万级活动页面快速生产背后的架构设计、交付手段和协作方式。目前团队25届秋招进行中,对我们团队感兴趣的同学可以将简历发送至邮箱:wuzhiwei.wzw@taobao.com,欢迎加入!
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法








![24-10-4-读书笔记(二十四)-《一个孤独漫步者的遐想》下([法] 让·雅克·卢梭 [译]陈阳)](https://i-blog.csdnimg.cn/direct/d472ed32dd3a4af0971c18e041cf19a5.jpeg)