今天跟大家介绍的GIMDiffusion是一种新的Text-to-3D模型,利用几何图像(Geometry Images)来高效地表示3D形状,避免了复杂的3D架构。通过结合现有的Text-to-Image模型如Stable Diffusion的2D先验知识,GIMDiffusion能够在有限的3D数据下实现强大的泛化能力,生成包含语义意义和内部结构的3D对象,同时保持高效的速度。 一起来看下他的3D生成效果~
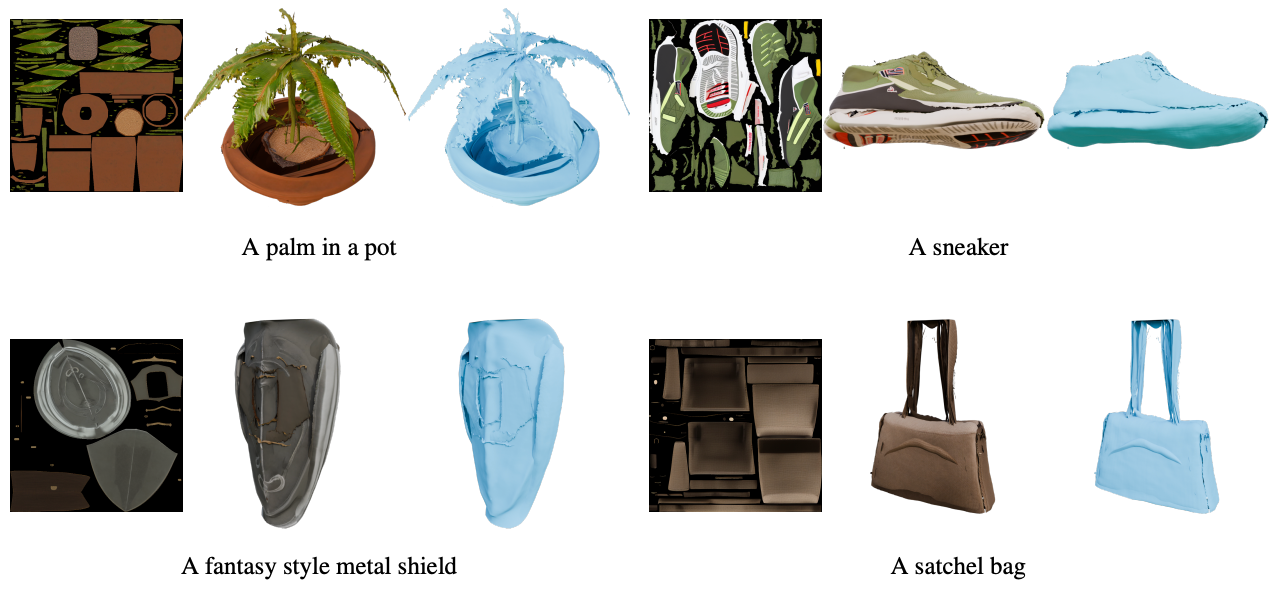

GIMDiffusion生成的网格。 对于每个对象显示生成的反照率纹理、纹理网格、无纹理网格和相应的文本提示。对象完全使用GIMDiffusion生成:UV 贴图的结构、纹理和布局都是完全从头生成的。
GIMDiffusion 的优势包括:
-
基于图像:通过利用现有基于图像的 2D 模型,简化了模型设计和训练。
-
快速生成:在每个对象 10 秒内生成定义明确的 3D 网格。
-
泛化:通过协作控制重复使用预先训练的文本到图像先验,能在有限训练数据之外进行泛化。
-
独立部分:GIMDiffusion 创建的资产由可分离部分组成,可以轻松地操作和编辑单个组件。
-
反照率纹理:GIMDiffusion 生成的 3D 资产没有内置的灯光效果,因此适用于各种环境。
-
简单的后期处理:3D资产不需要应用等值面提取算法或 UV 展开。
相关链接
论文链接:https://arxiv.org/pdf/2409.03718
代码链接:(即将开源)
论文阅读

GIMDiffusion:基于图像的表面表示的快速且数据高效的文本到 3D 转换
摘要
由于计算成本、3D 数据稀缺性和复杂的 3D 表示,从文本描述生成高质量 3D 对象仍然是一个具有挑战性的问题。我们引入了几何图像扩散 (GIMDiffusion),这是一种新颖的文本到 3D 模型,它利用几何图像有效地使用 2D 图像表示 3D 形状,从而避免了对复杂的 3D 感知架构的需求。通过集成协作控制机制,我们利用了现有文本到图像模型(如稳定扩散)的丰富 2D 先验。这即使在有限的 3D 训练数据(允许我们仅使用高质量的训练数据)的情况下也能实现强大的泛化,并保持与 IPAdapter 等引导技术的兼容性。简而言之,GIMDiffusion 能够以与当前文本到图像模型相当的速度生成 3D 资产。生成的对象由语义上有意义的、独立的部分组成,并包含内部结构,从而增强了可用性和多功能性。
方法
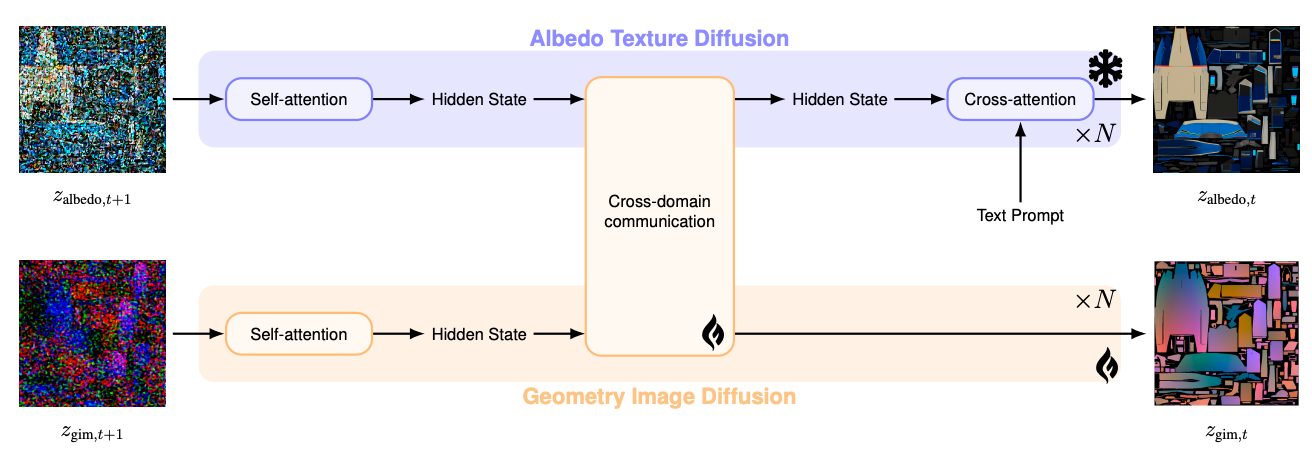
协同控制方案应用于GIMDiffusion,其中分别产生两个独立的扩散模型反照率纹理和几何图像。前者是一个冻结的预训练模型,而后者是一个从头开始训练的架构克隆。
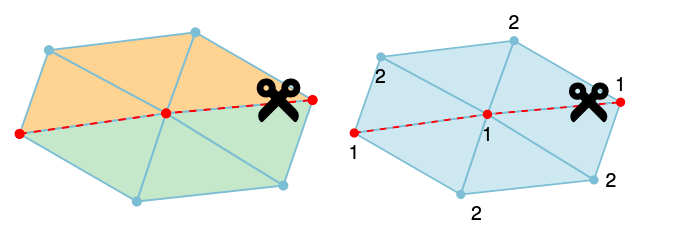
在多图表几何图像创建过程中使用接缝检测来隔离 UV 映射的局部可逆区域。(左)如果两个相邻的网格区域对应于 UV 映射中的两个不同图表,则边界上的顶点将重复并具有不同的 UV 坐标。(右)如果 UV 映射循环回到自身,则 UV 访问热图中将出现局部最小值,我们将接缝沿着 UV 度最小的线放置,以有效地分离这些区域。
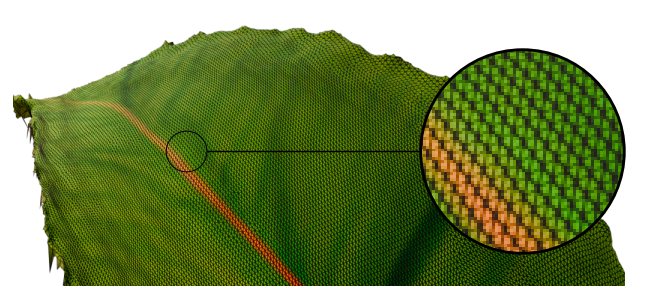
由于训练数据集中几何图像的面积保留特性,我们生成的对象的三角剖分结果在表面上几乎是均匀的。
实验
数据集
在 Objaverse 数据集上训练模型。通过过滤掉 3D 扫描和低多边形模型来整理此数据集,使其仅包含具有高质量结构和语义上有意义的 UV 图的对象。最终数据集包含大约 100,000 个对象。每个数据条目都附有 Cap3D 和 Hong 等人提供的标题。在训练期间,从这些标题中随机抽样,并对提取的纹理图集应用 90、180 或 270 度的随机旋转。现在讨论如何将这些网格转换为几何图像并转回:整个预处理是在消费级 PC 硬件(AMD Ryzen 9 7950X、GeForce RTX 3090、64 GB RAM)上执行的,大约需要 20 个小时。
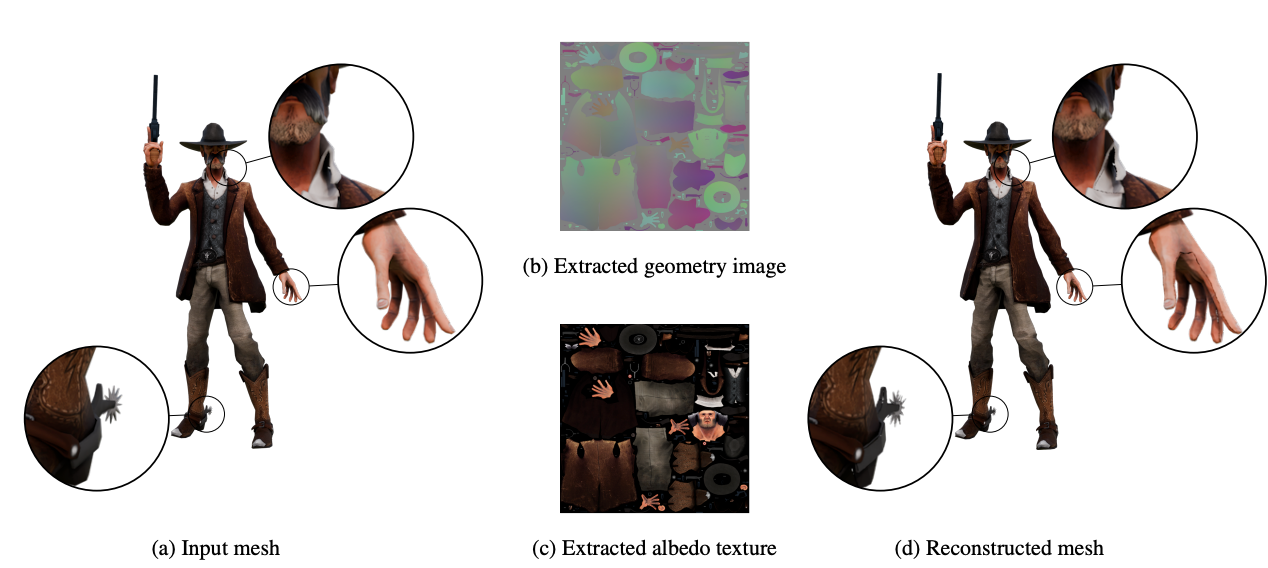
(a)真实几何图形、(b)几何图像、(c)来自数据预处理的反照率、(d)使用专用的 VAE 进行的重建。真实对象的高度可分离性,它被分成小部分。

GIMDiffusion 的样本多样性用于对提示进行微小更改或对初始高斯噪声使用不同的随机种子。 很明显,生成的变化不仅在外观和结构上存在很大差异,而且在纹理的图集布局上也存在很大差异。这在实际应用中非常有价值,因为用户通常会生成多个选项并选择最佳选项。

GIMDiffusion 得益于基础模型强大的自然图像先验与协同控制方案的结合,能够很好地超越 Objaverse 训练数据的“原始”性质。

可以通过将预先训练的 IPAdapter 应用于冻结的基础模型生成反照率纹理,以风格化的方式指导逆向过程。这在资产需要与现有“感觉”相匹配的应用中非常有价值。

生成的图像保留了纹理图集中图表的语义上有意义的分离。我们在这里通过展示生成的“毒蝇伞蘑菇”的分解图来说明这一点。很明显,蘑菇的各个部分像人类一样被分开,而且该方法甚至能够模拟形状的内部部分。
结论
在本文跟大家介绍了几何图像扩散(GIMDiffusion),这是一种新颖的文本到 3D 生成范例,它利用几何图像作为其核心 3D 表示,并结合预先训练的扩散模型形式的强大自然图像先验。
GIMDiffusion 可以像现有的文本到图像方法生成普通图像一样高效地生成可重新点亮的 3D 资产,同时避免了对复杂的自定义 3Daware 架构的需求。该研究为文本到 3D 生成的新方向奠定了基础。进一步的质量改进包括解决图表间对齐和消除可见裂缝等问题。此外,结合拓扑预测和对特定多边形预算的调节将增强对生成的 3D 对象的控制,使其更适合用于游戏和其他图形管道。GIMDiffusion 在动画或文本到视频生成等相关领域的潜力同样有希望。
局限性。 最常见的问题是生成的网格中出现可见的裂缝。虽然目前没有将图表的接缝缝合在一起,这可以提高生成的网格的视觉质量,但 VAE 的潜在压缩进一步加剧了这个问题。小于 8×8 像素的区域基本上低于 VAE 的潜在分辨率,从而导致视觉问题。