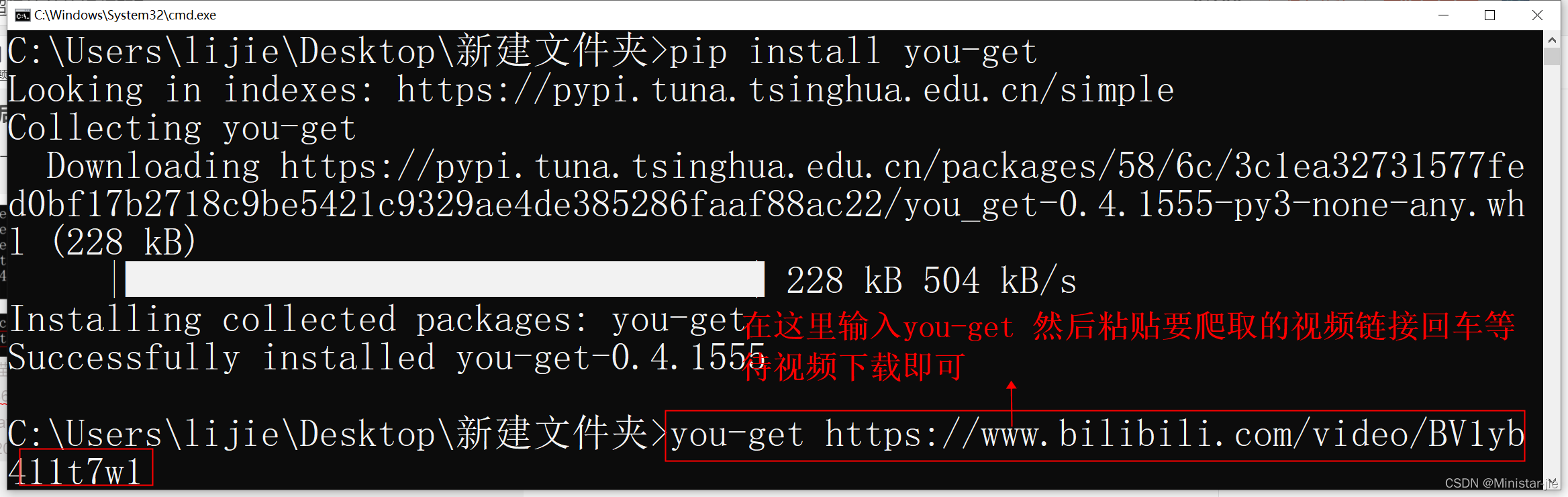
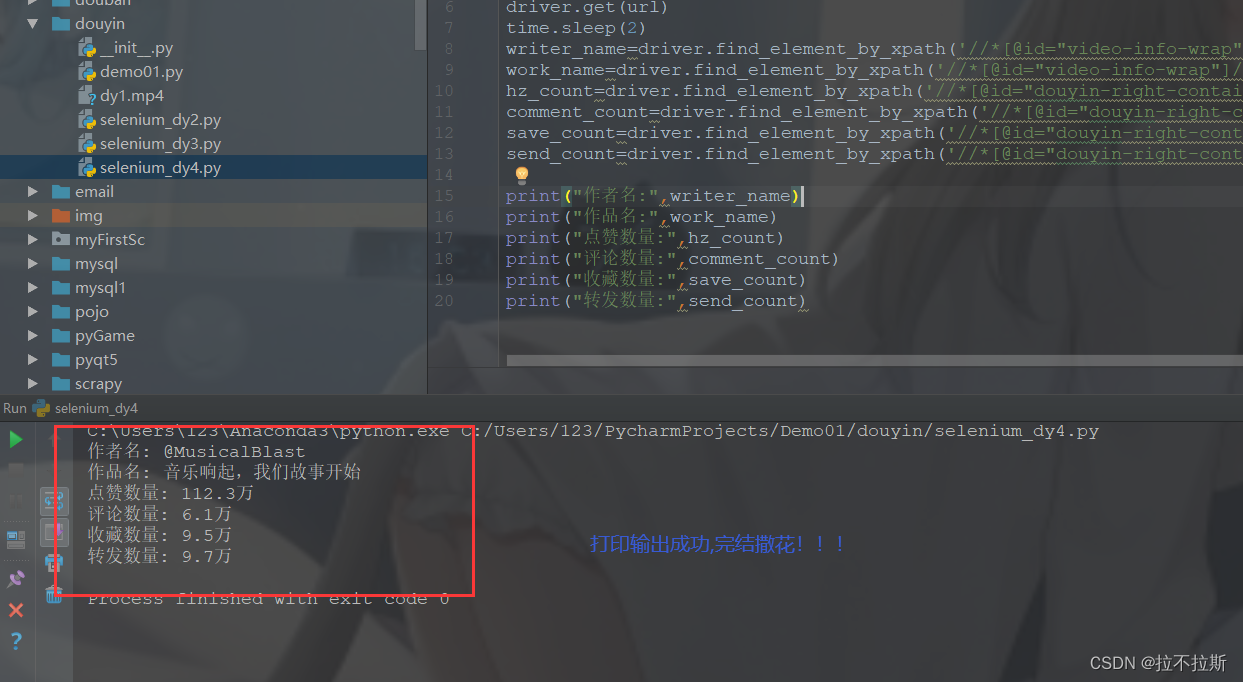
1、进入此次爬取的页面点这里。
2、按F12—> network
3、ctrl+r 刷新 如图搜索一个电影名,找到数据位置,然后查看

4、找到请求的url ‘?’后边的是参数,不要带上
 5、参数单独拿出来
5、参数单独拿出来

start:0 代表的是排行榜的第一部电影
limit:20 代表的是一次返回20条数据(20部电影)
start和limit都可以更改
param={'type': '24','interval_id': '100:90','action':'' ,'start': start,'limit': limit}
6、大致先看一看拿到的数据类型,然后解析,从其中拿到自己想要的数据

7、开始编写代码:
import csv
import pprint
import requestsurl='https://movie.douban.com/j/chart/top_list'
start=input('从库中第几部电影取:')
limit=input('取几部:')
param={'type': '24','interval_id': '100:90','action':'' ,'start': start,'limit': limit}
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62'}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()
pprint.pprint(list_data)运行代码,查看结果:

拿到的的确是两条数据,然后从其中选择自己想要的数据出来,进行可视化处理,保存为csv格式
f=open('./豆瓣.csv','w',encoding='utf-8-sig',newline='')#a 是追加保存
csv_write=csv.DictWriter(f, fieldnames=['电影名','主演人数','主演','评分','上映时间','类型','评论数','拍摄国家',
])
csv_write.writeheader()for i in list_data:dic={'电影名':i['title'],'主演人数':i['actor_count'],'主演':i['actors'],'评分':i['score'],'上映时间':i['release_date'],'类型': i['types'],'评论数': i['vote_count'],'拍摄国家':i['regions']}print(dic)csv_write.writerow(dic)
运行:


8.完整代码:
import csv
import requestsurl='https://movie.douban.com/j/chart/top_list'
start=input('从库中第几部电影取:')
limit=input('取几部:')
param={'type': '24','interval_id': '100:90','action':'' ,'start': start,'limit': limit}
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62'}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()f=open('./豆瓣.csv','w',encoding='utf-8-sig',newline='')#a 是追加保存
csv_write=csv.DictWriter(f, fieldnames=['电影名','主演人数','主演','评分','上映时间','类型','评论数','拍摄国家',
])
csv_write.writeheader()for i in list_data:dic={'电影名':i['title'],'主演人数':i['actor_count'],'主演':i['actors'],'评分':i['score'],'上映时间':i['release_date'],'类型': i['types'],'评论数': i['vote_count'],'拍摄国家':i['regions']}print(dic)csv_write.writerow(dic)