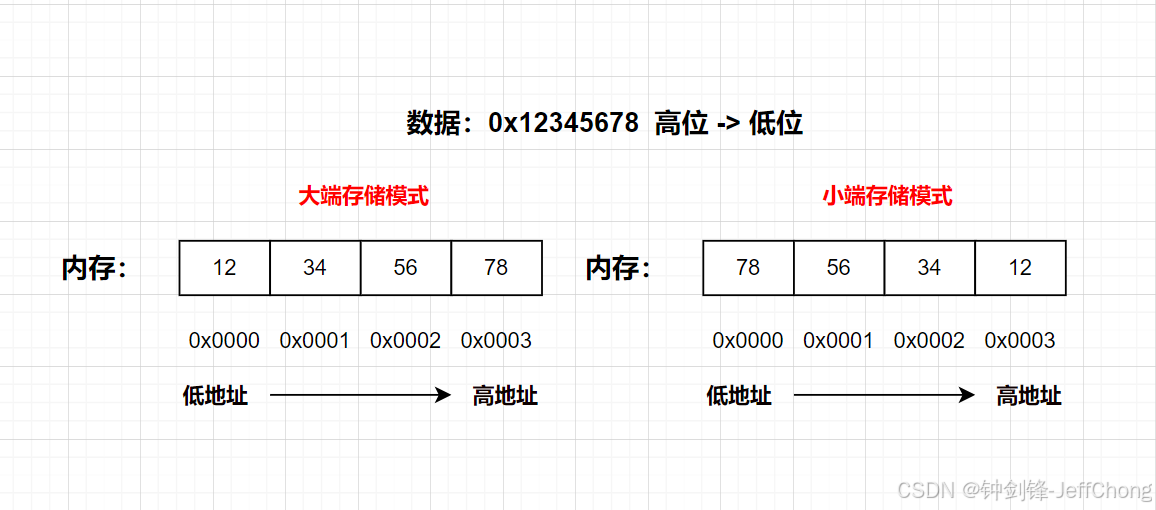
2.前言与导学
从关注算法的分类与特性到关注算法适合解决哪类问题
很多经典算法不再有效,但特征工程、集成学习越来越有效,和深度学习分别适合于不同领域
3、基本概念
如果预测目标是离散的,则是分类问题,否则回归
机器学习相比统计学算法计算效率更高、对数据质量要求更低
损失函数和模型评估函数:一般不是一个,后续会讲两个不同形式的函数间的关联
9.变量相关性基础
变量相关性数值与强弱关系:
0-0.1不相关
0.1-0.3弱相关
0.3-0.5中等相关
0.5-1.0强相关
plt.subplot() /括号内填一个三位数,前两位表示几行几列,第三位表示这是这些图里的第几个
以下代码验证自己建立的数据集,当线性相关性越弱的时候,是否计算出的相关值也越差,同时画图观察
# In[1]:
import numpy as np
# In[16]:
a=np.array([[1,2,3],[4,5,10]]).T
# In[17]:
np.corrcoef(a[:,0],a[:,1])
# In[20]:
import matplotlib.pyplot as plt
# In[21]:
plt.plot(a[:,0],a[:,1])
# In[22]:
import pandas as pd
# In[23]:
x=np.random.randn(20)
# In[24]:
y=x+1
# In[25]:
np.corrcoef(x,y)
# In[26]:
plt.plot(x,y,'o')
# In[27]:
#再加一个扰动项
a=y.shape
# In[29]:
np.random.normal(size=a)
# In[30]:
ran=np.random.normal(size=y.shape)
# In[31]:
#创建控制扰动项大小的变量
delta=0.5
# In[32]:
r=ran*delta
# In[33]:
r
# In[34]:
y1=y+r
# In[36]:
plt.subplot(121)
plt.plot(x,y,'o')
plt.title('y=x+1')
plt.subplot(122)
plt.plot(x,y1,'o')
plt.title('y=x+1+r')
# In[37]:
#由此可见,加入扰动项后模型线性相关性变弱了
#修改不同参数
d1=[0.5,0.7,1,1.5,2,5]
# In[38]:
y1=[]
c1=[]
# In[39]:
for i in d1:
yn=x+1+(ran*i)
c1.append(np.corrcoef(x,yn))
y1.append(yn)
# In[40]:
c1
# In[41]:
plt.plot(x,y1[0],'o')
# In[43]:
plt.subplot(231)
plt.plot(x,y1[0],'o')
plt.plot(x,y,'r-')
plt.subplot(232)
plt.plot(x,y1[1],'o')
plt.plot(x,y,'r-')
plt.subplot(233)
plt.plot(x,y1[2],'o')
plt.plot(x,y,'r-')
plt.subplot(234)
plt.plot(x,y1[3],'o')
plt.plot(x,y,'r-')
plt.subplot(235)
plt.plot(x,y1[4],'o')
plt.plot(x,y,'r-')
plt.subplot(236)
plt.plot(x,y1[5],'o')
plt.plot(x,y,'r-')

#能够看出,随着delta变大,数据相关性越来越弱