「OC」NSArray的底层逻辑和遍历方法
文章目录
- 「OC」NSArray的底层逻辑和遍历方法
- 前言
- NSArray的底层逻辑
- 占位符
- init后的空NSArray
- 只有单个元素的NSArray
- 大于一个元素的NSArray
- 可变数组NSMutableArray
- 总结图片
- 遍历NSArray
- 1. for循环
- 2. 枚举
- 3.for—in
- 4. 多线程
- 1.for 循环&for in
- 2.block循环
- 参考文章
前言
最近在看github上大佬写的关于NSArray的博客,正好最近在对NSArray的相关知识进行梳理,于是整理成博客。
NSArray的底层逻辑
我们提供一段代码作为开头
NSArray *placeholder = [NSArray alloc];NSArray *arr1 = [[NSArray alloc] init];NSArray *arr2 = [[NSArray alloc] initWithObjects:@0, nil];NSArray *arr3 = [[NSArray alloc] initWithObjects:@0, @1, nil];NSArray *arr4 = [[NSArray alloc] initWithObjects:@0, @1, @2, nil];NSLog(@"placeholder: %s", object_getClassName(placeholder));NSLog(@"arr1: %s", object_getClassName(arr1));NSLog(@"arr2: %s", object_getClassName(arr2));NSLog(@"arr3: %s", object_getClassName(arr3));NSLog(@"arr4: %s", object_getClassName(arr4));NSMutableArray *mPlaceholder = [NSMutableArray alloc];NSMutableArray *mArr1 = [[NSMutableArray alloc] init];NSMutableArray *mArr2 = [[NSMutableArray alloc] initWithObjects:@0, nil];NSMutableArray *mArr3 = [[NSMutableArray alloc] initWithObjects:@0, @1, nil];NSLog(@"mPlaceholder: %s", object_getClassName(mPlaceholder));NSLog(@"mArr1: %s", object_getClassName(mArr1));NSLog(@"mArr2: %s", object_getClassName(mArr2));NSLog(@"mArr3: %s", object_getClassName(mArr3));
我们可以得到以下结果:
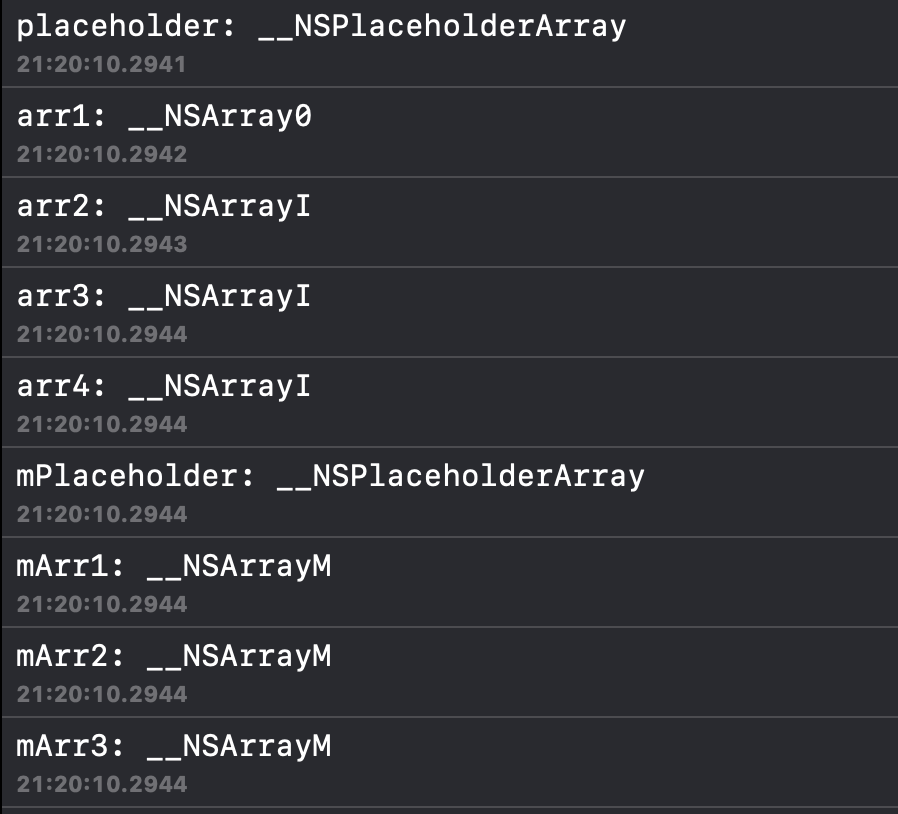
了解了上面得出的结果,我们就可以开始进行相关的分析了。
占位符
我们先从第一个开始分析,不论是可变数组还是不可变数组,我们对其只进行alloc的结果得到的都是一个名为 __NSPlaceholderArray的类,顾名思义这个类就是用来进行占位的,我们对其进行再进一步的探究
NSArray *placeholder1 = [NSArray alloc];
NSArray *placeholder2 = [NSArray alloc];
NSLog(@"placeholder1: %p", placeholder1);
NSLog(@"placeholder2: %p", placeholder2);
我们可以看到
NSArray *placeholder1 = [NSArray alloc];
NSArray *placeholder2 = [NSMutableArray alloc];
NSLog(@"placeholder1: %p", placeholder1);
NSLog(@"placeholder2: %p", placeholder2);
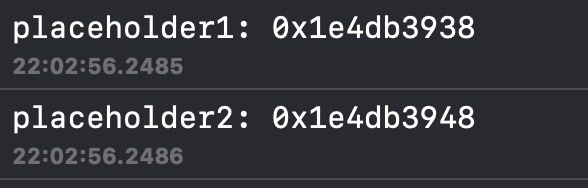
我们可以看到生成的占位符地址是一样的
这里我直接引用大佬的结论
可以猜测,这里是生成了一个单例,在执行
init之后就被新的实例给更换掉了。该类内部只有一个isa指针,除此之外没有别的东西。 由于苹果没有公开此处的源码,我查阅了别的类似的开源以及资料,得到如下的结论:当元素为空时,返回的是__NSArray0的单例;
为了区别可变和不可变的情况,在init的时候,会根据是NSArray还是NSMutableArray来创建
immutablePlaceholder和mutablePlaceholder,它们都是__NSPlaceholderArray类型的。
init后的空NSArray
对于空的NSArray的来说,因为NSArray是不可变的,也就是说,就是空的NSArray有且只有一种,那我们想到可以使用单例来进行实现。我们可以打印出来的类名__NSArray0
关于这个__NSArray0是否为单例我们可以以下程序进行验证
#import <Foundation/Foundation.h>int main(int argc, const char * argv[]) {@autoreleasepool {NSArray *array = [NSArray array];NSUInteger rc = [array retainCount];NSLog(@"%lu", rc);}return 0;
}
我们通过打印出来的数字,是一个很大的数字,就足以说呢我们创建的是一个单例了
只有单个元素的NSArray
接下来我们看到只有一个元素的NSArray,由于NSArray是不可变数组,我们可以看到打印出来的类名叫做__NSSingleObjectArrayI
结构定义如下
@interface __NSSingleObjectArrayI : NSArray
{id object;
}
@end
大于一个元素的NSArray
我们可以看到大于一个元素的NSArray,程序打印的是__NSArrayI
__NSArrayI的结构如下
@interface __NSArrayI : NSArray
{NSUInteger _used;id _list[0];
}
@end
_used是数组的元素个数,调用[array count]时,返回的就是_used的值。 这里我们可以把id _list[0]当作id *_list来用,这个id _list[0]其实被叫做柔性数组
当你定义一个结构体并在结构体的末尾放置一个大小为 0 的数组时,编译器会将这个数组成员视为柔性数组。这个柔性数组的大小是在运行时根据需要动态分配内存来确定的。因此,通过访问结构体的柔性数组成员,你实际上可以访问在结构体后面额外分配的内存空间,这样就能实现动态长度的数组。
可变数组NSMutableArray
在程序之中我们可以知道,无论是什么情况,我们创建的NSMutableArray类名都是__NSArrayM,由于可变数组是可以随意添加和删除元素的,其对应的结构如下:
@interface __NSArrayM : NSMutableArray
{NSUInteger _used;NSUInteger _offset;int _size:28;int _unused:4;uint32_t _mutations;id *_list;
}
@end__NSArrayM稍微复杂一些,但是同样的,它的内部对象数组也是一块连续内存id* _list,正如__NSArrayI的id _list[0]一样 _used:当前对象数目 _offset:实际对象数组的起始偏移,这个字段的用处稍后会讨论 _size:已分配的_list大小(能存储的对象个数,不是字节数) _mutations:修改标记,每次对__NSArrayM的修改操作都会使_mutations加1 id *_list是个循环数组.并且在增删操作时会动态地重新分配以符合当前的存储需求。
注:关于
int _size:28;之中的28是位域,表示的是在内存之中占28个比特位,28 + 4 = 32 正好是一个int类型的字节大小
简单介绍之后,我们再来着重的讲一下刚刚介绍的offset和unused
__NSArrayM内存存储方式是使用环形缓存区的策略进行存储的,环形缓存区其实就像是一个环形队列,在我们进行增删操作的时候,程序会对这个_size进行动态的修正。
现在我用一个例子来解释__NSArrayM的工作原理,我们现在有一个包含5个对象,总大小_size为6的_list为,初始化完成之后 _offset = 0,_used = 5,_size=6

在末端追加3个对象后: _offset = 0,_used = 8,_size=8 _list已重新分配

删除对象A: _offset = 1,_used = 7,_size=8

删除对象E: _offset = 2,_used = 6,_size=8 B,C往后移动了,E的空缺被填补

在末端追加两个对象: _offset = 2,_used = 8,_size=8 _list足够存储新加入的两个对象,因此没有重新分配,而是将两个新对象存储到了_list起始端

对于我们环形缓存区来说,如果我们需要从两端任意一端进行增删操作,就不需要我们进行对数组内存进行的移动,如果是需要我们对中间进行操作,那么其实程序只会对操作当前位置元素最少的一端。
总结图片

遍历NSArray
前面的内容介绍完了NSArray的相关的底层逻辑了,现在开始我们对于NSArray的遍历进行探究了,下面介绍一下遍历的相关方式
1. for循环
for (int i = 0; i < array.count; ++i) {id object = array[i];}
2. 枚举
关于枚举,我们就是使用NSEnumerator进行相关操作
NSEnumerator *enumerator = [array objectEnumerator];
id object;
while((object = [enumerator nextObject])!= nil){}
3.for—in
for (id object in anArray) {}
4. 多线程
通过block回调,在子线程中遍历,对象的回调次序是乱序的,而且调用线程会等待该遍历过程完成:
[array enumerateObjectsWithOptions:NSEnumerationConcurrent usingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {xxx}];
其实关于遍历其实绕来绕去离不开性能二字,下图就是各种遍历方式的性能
[
横轴为遍历的对象数目,纵轴为耗时,单位us. 从图中看出,在对象数目很小的时候,各种方式的性能差别微乎其微。随着对象数目的增大, 性能差异才体现出来. 其中for in的耗时一直都是最低的,当对象数高达100万的时候,for in耗时也没有超过5ms. 其次是for循环耗时较低. 反而,直觉上应该非常快速的多线程遍历方式却是性能最差的。
其中关于他们之间的性能差异产生的原因,我找到了这篇文章 Objective-C 数组遍历的性能及原理,有兴趣的读者可以自行阅读,由于笔者能力还有所欠缺,还无法完整的内容学完,这里就直接引用作者得到的结论:
1.for 循环&for in
以for—in为例。forin遵从了NSFastEnumeration协议,它只有一个方法:
- (NSUInteger)countByEnumeratingWithState:(NSFastEnumerationState *)stateobjects:(id *)stackbuffer count:(NSUInteger)len;
它直接从C数组中取对象。对于可变数组来说,它最多只需要两次就可以获取全部全速。如果数组还没有构成循环,那么第一次就获得了全部元素,跟不可变数组一样。但是如果数组构成了循环,那么就需要两次,第一次获取对象数组的起始偏移到循环数组末端的元素,第二次获取存放在循环数组起始处的剩余元素。 而for循环之所以慢一点,是因为for循环的时候每次都要调用objectAtIndex: 假如我们遍历的时候不需要获取当前遍历操作所针对的下标,我们就可以选择forin。
2.block循环
这种循环虽然是最慢的,但是我们在遍历的时候可以直接从block中获取更多的信息,并且可以修改块的方法签名,以免进行类型转换操作。
for(NSString *key in aDictionary){NSString *object = (NSString *)aDictionary[key];
}
NSDictionary *aDictionary = /*...*/;
[aDictionary enumerateKeysAndObjectsUsingBlock:^(NSString *key,NSString *obj,BOOL *stop){}];
而NSEnumerationConcurrent+Block的方式耗时最大,我认为是因为它采用了多线程,就这个方法来讲,多线程的优势并不在于遍历有多快,而是在于它的回调在各个子线程,如果有遍历+分别耗时计算的场景,这个方法应该是最适合的,只是此处只测遍历速度,它光启动分发管理线程就耗时不少,所以性能落后了.
并且如果需要需要并发的时候,也可以方便的使用dispatch_group/dispatch_apply。
另外还有一点:如果数组的数量过多,除了block遍历,其他的遍历方法都需要添加autoreleasePool方法来优化。block遍历就不需要,因为系统在实现它的时候就已经实现了相关处理。
参考文章
NSArray原理及遍历方法探究
Exposing NSMutableArray




![Centos7安装RocketMQ[图文教程]](https://i-blog.csdnimg.cn/direct/0415f27f93f54f07926753eb6c4322ac.png)