在有限的数据资源下,为了训练出高性能的机器学习模型,我们常会考虑Transformer+小样本学习。
这是因为Transformer能从有限的数据中提取更多有用的信息,这样与小样本学习结合,可以更有效的帮助我们提高模型的性能,加速训练和推理,模型也能拥有更灵活的架构和更强的迁移学习能力。
因此Transformer+小样本学习也是当前机器学习领域的一个研究热点,有不少顶会成果,比如CVPR 2024的PriViLege框架以及AAAI 2023的SCAT网络。
目前这个方向正在快速发展中,建议想发顶会的同学围绕预训练策略、微调方法、数据增强技术等方面进行挖掘。当然为了方便各位,我这边也整理好了10篇Transformer+小样本学习新论文给大家参考,代码基本都有。
论文原文+开源代码需要的同学看文末
Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
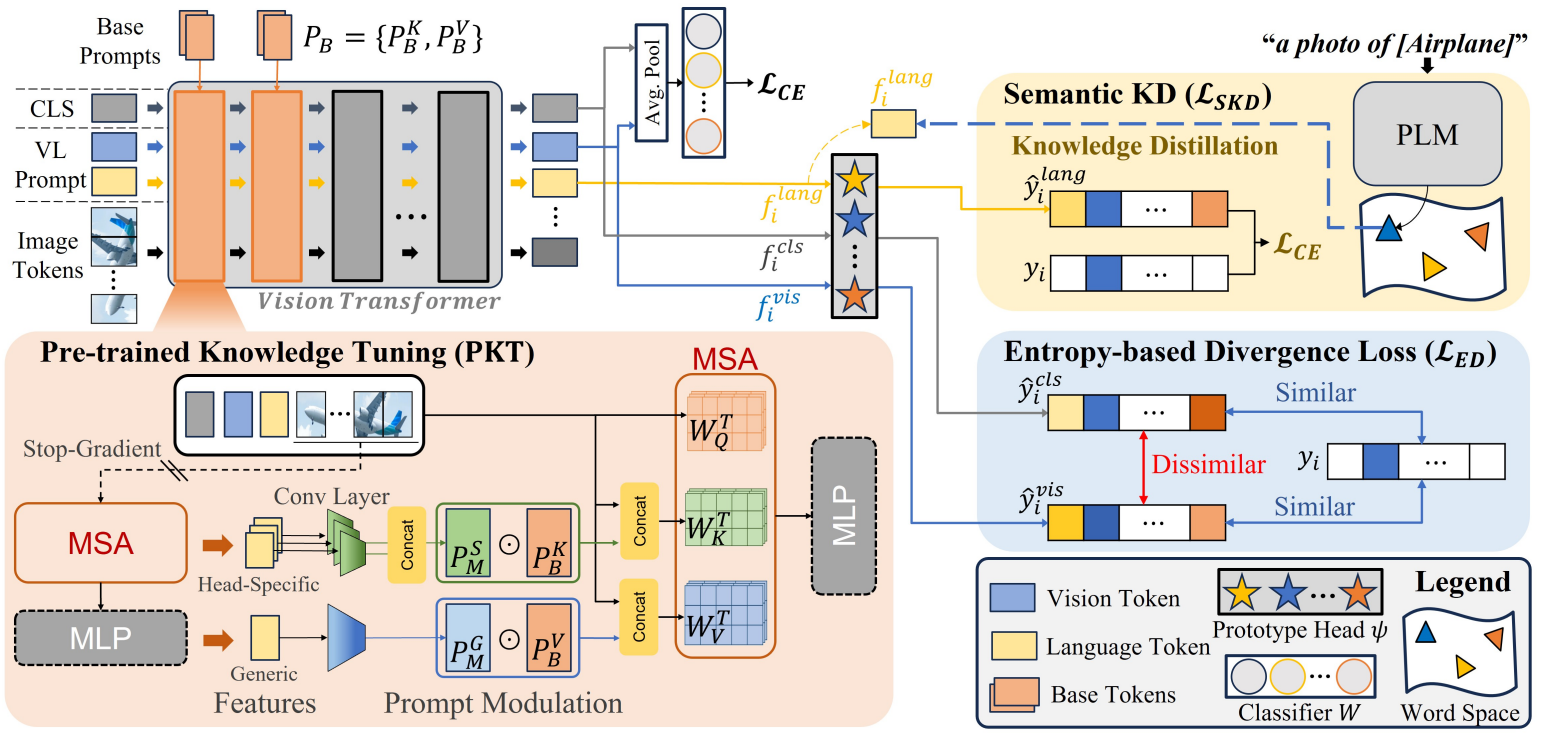
方法:论文提出了一个名为PriViLege的新型框架,用于处理小样本类增量学习任务。PriViLege框架利用在大型数据集上预训练的视觉和语言Transformer模型,通过一种新的预训练知识调整方法,以及两种新的损失函数:基于熵的散度损失和语义知识蒸馏损失,有效地解决了在大型模型中常见的灾难性遗忘问题。
创新点:
-
提出了一种新颖的少样本类增量学习(FSCIL)框架,称为PriViLege,利用大规模预训练的视觉和语言变换器,显著提高了性能。
-
PKT引入了一种简单而有效的方法,通过选择性训练特定层来保护大模型的预训练知识,同时有效学习领域特定的知识。
-
提出了新的熵基分歧损失,以增强基会话期间的判别能力,并将知识转移到增量会话中。
Few-shot 3d point cloud semantic segmentation via stratified class-specific attention based transformer network
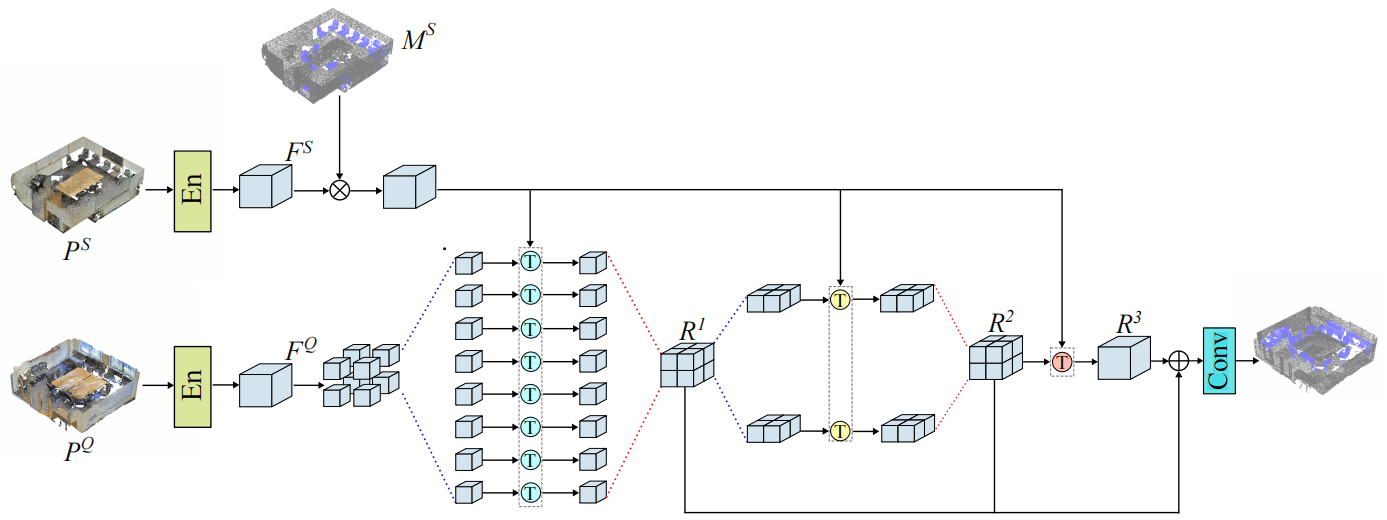
方法:论文提出了一种分层类特定注意力Transformer网络,用于少样本3D点云语义分割,通过引入层次化结构和多头注意力机制来优化支持和查询间的关系,显著提高了分割性能并减少推理时间,相较于现有方法如MPTI和AttMPTI,其在S3DIS和ScanNet数据集上实现了新的最先进性能,推理时间减少约15%。
创新点:
-
引入了一种新的分层类特定注意力Transformer网络,用于少样本3D点云语义分割。
-
通过保留更多支持类别信息,改善了对查询点云特征的处理。
-
设计了一种网络,将查询点云的多尺度特征与标记的支持样本条件聚合,以更好地探索它们之间的关系。

Supervised masked knowledge distillation for few-shot transformers
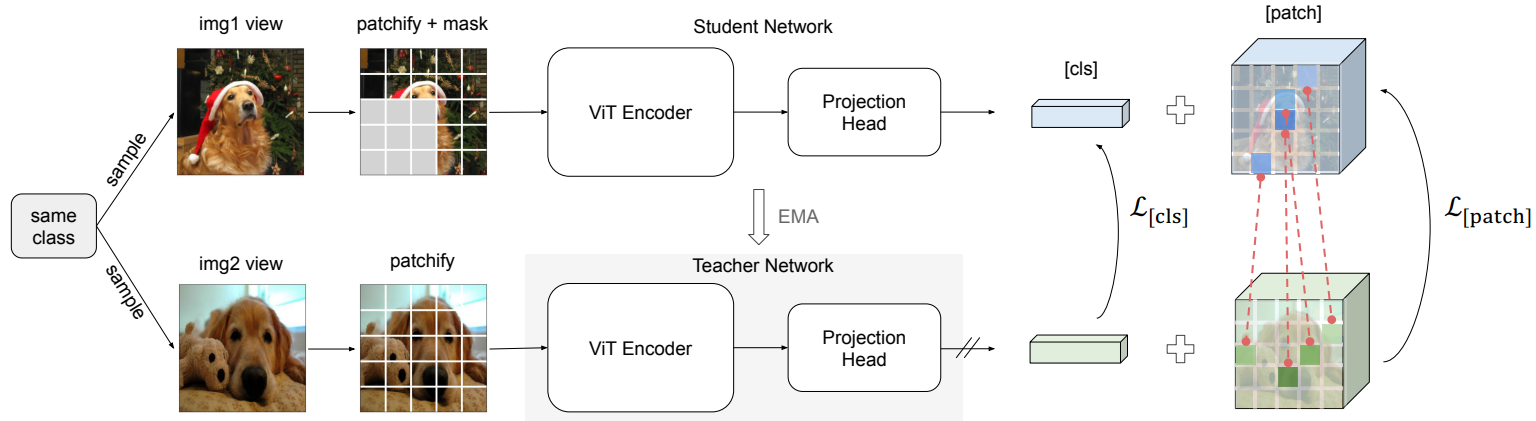
方法:论文提出一种在小样本学习(FSL)中表现优异的知识蒸馏框架,以解决视觉Transformer在小数据集上的泛化问题,通过引入掩码图像建模(MIM)和改进的损失函数,实现更具语义意义的特征嵌入,从而在无需大批量和负样本的情况下提高模型的泛化能力。
创新点:
-
提出了一种新的监督知识蒸馏框架,将类标签信息融入自我蒸馏中,弥合了自监督知识蒸馏与传统监督学习之间的差距。
-
通过使用加权平均池化而非[cls]标记,提升了小样本学习的性能。
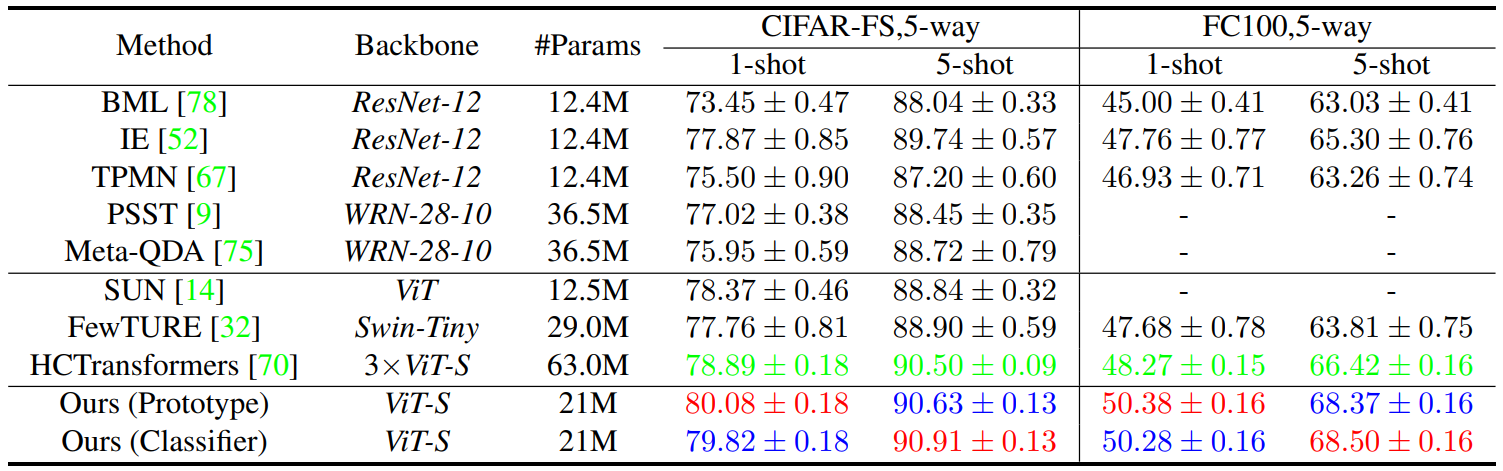
Linknet-spectral-spatial-temporal transformer based on few-shot learning for mangrove loss detection with small dataset
方法:作者提出了一个名为LSST-Former的模型,该模型结合了全卷积网络(FCN)和Transformer基础结构,并融入了小样本学习算法,用于从Sentinel-2图像中提取光谱-空间-时间信息,以有限的标签数据检测红树林损失。该模型在红树林损失检测任务中实现了99.59%的整体准确率。
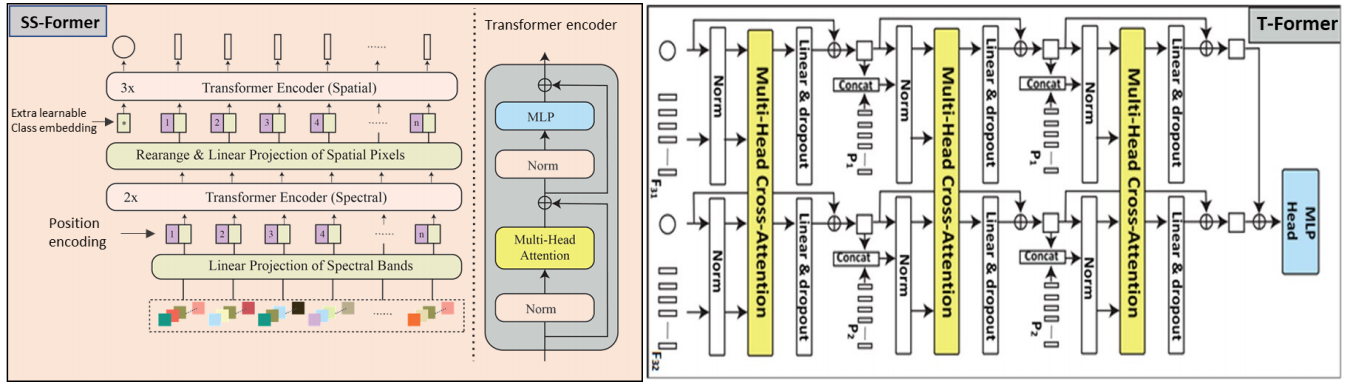
创新点:
-
LSST-Former模型创新性地将全卷积网络与Transformer架构相结合,利用FCN进行空间-光谱特征提取,再通过Transformer进行时空特征的进一步分析,以处理小样本学习任务。
-
该模型针对标记样本数量有限的情况,通过少量样本学习算法有效地提高了红树林损失检测的准确性。
-
LSST-Former模型能够综合利用光谱、空间和时间信息,通过多层Transformer网络对不同尺度的查询点云特征进行聚合,提高了对红树林损失的检测性能。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“小样本T”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏



















