在 Windows 环境中结合使用 Protégé、Jupyter Notebook 中的 spaCy 和 Neo4j Desktop,可以高效地实现从自然语言处理(NLP)到知识图谱构建的全过程。本案例将详细论述环境配置、步骤实现以及一些扩展和不足之处。
源文件已上传我的资源区。
文章目录
- 1. 环境准备
- 1.1 Neo4j Desktop 安装和配置
- 1.2 安装并启动 Protégé
- 1.3 配置 spaCy 环境(Jupyter Notebook)
- 1.3.1 安装 spaCy
- 1.3.2 安装 Jupyter 和 ipykernel
- 1.4 启动 Jupyter Notebook
- 2. 案例实现步骤
- 2.1 数据示例
- 2.2 使用 spaCy 进行实体识别和关系抽取
- 2.3 将抽取的实体和关系导入 Neo4j
- 2.4 在 Neo4j Desktop 中查看数据
- 3. Neo4j导出数据
- 3.1 在 Neo4j 中准备数据
- 3.2. 导出 Neo4j 数据
- 3.2.1 导出实体(如运动员和地点)
- 3.2.2 导出关系(如 BORN_IN)
- 4. 转换为 OWL 格式
- 4.1 使用 Python 编程库
- a. **`owlready2`**
- b. **`RDFLib`**
- 环境准备
- 案例代码
- 代码解释
- 注意事项
- 选择合适的方法
- 4.2 其他
- 5. 在 Protégé 中加载 OWL 文件和处理
- 4.1 打开 Protégé
- 4.2 创建或打开本体
- 4.3 导入 OWL 文件
- 4.4 验证数据
- 4.5 后续步骤
- 5. 案例总结
- 6. 不足与补充
- 相关阅读
1. 环境准备
1.1 Neo4j Desktop 安装和配置
- 安装 Neo4j Desktop:访问 Neo4j 官网 下载并安装 Neo4j Desktop。
- 启动本地数据库:创建一个新的数据库,并确保 Bolt 协议(默认端口:
7687)和 REST API(默认端口:7474)启用。
前置博客:
知识图谱入门——5:Neo4j Desktop安装和使用手册(小白向:Cypher 查询语言:逐步教程!Neo4j 优缺点分析)
1.2 安装并启动 Protégé
- 下载和安装 Protégé:访问 Protégé 官网 下载并安装最新版本。
- 启动 Protégé:运行应用程序并创建或打开本体项目。
前置博客:
知识图谱入门——4:Protégé 5.6.4安装和主要功能介绍、常用插件(2024年10月2日):知识图谱构建的利器
1.3 配置 spaCy 环境(Jupyter Notebook)
使用以下步骤在 Python 环境中配置 spaCy。
1.3.1 安装 spaCy
运行以下命令创建虚拟环境并安装 spaCy 和中文模型(因为有库冲突,建议新建环境):
# 创建虚拟环境
python -m venv spacy_env# 激活虚拟环境
spacy_env\Scripts\activate # Windows# 安装 spaCy
pip install spacy
python -m spacy download zh_core_web_sm # 中文模型
1.3.2 安装 Jupyter 和 ipykernel
确保可以在 Jupyter Notebook 中使用 spaCy 虚拟环境:
pip install jupyter ipykernel
python -m ipykernel install --name spacy_env --display-name "spacy_env"
1.4 启动 Jupyter Notebook
在虚拟环境中运行 Jupyter Notebook:
jupyter notebook
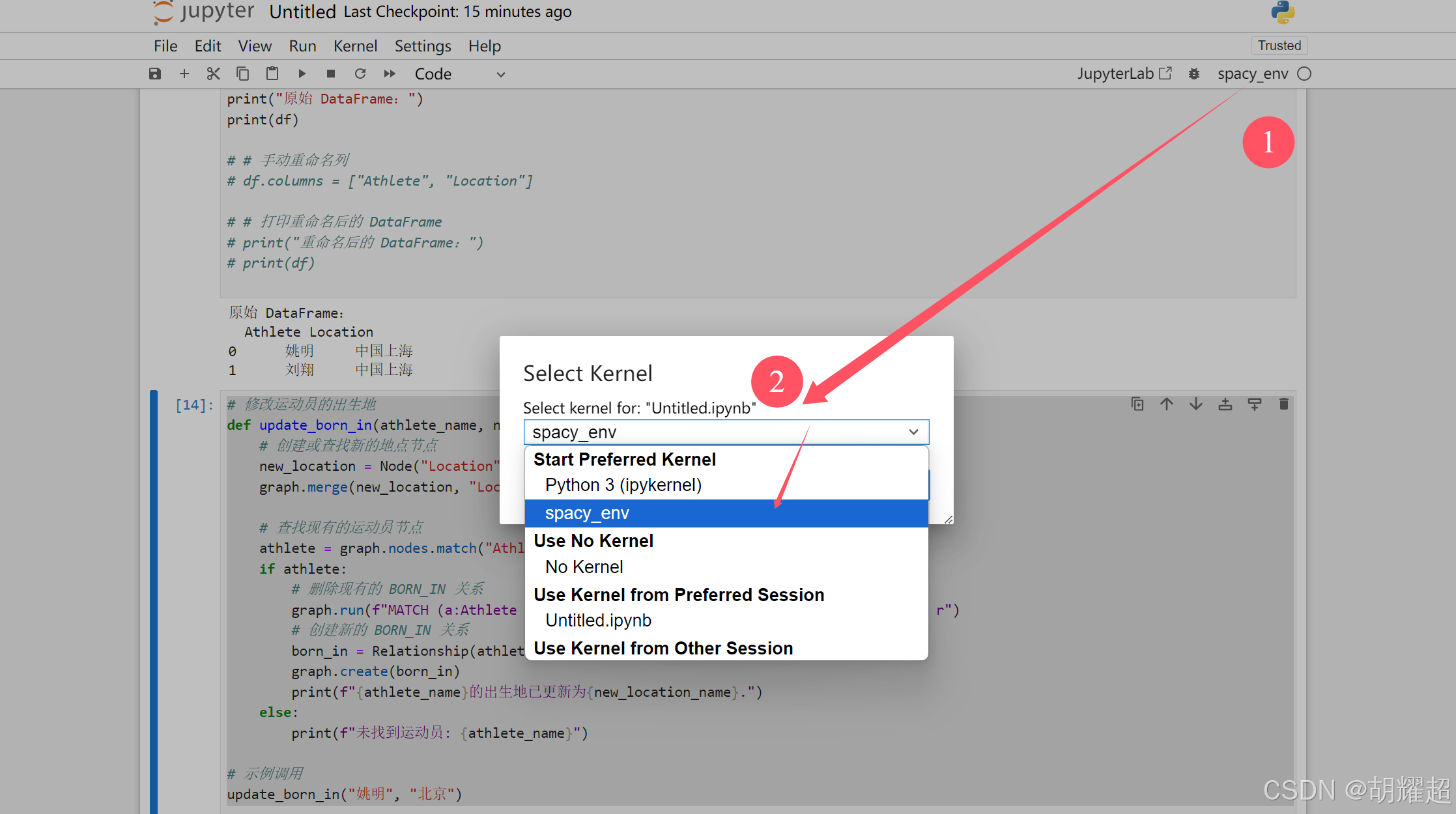
在新建的笔记本中选择内核为 “spaCy Environment”。
2. 案例实现步骤
2.1 数据示例
假设我们有如下文本数据,描述了一些运动员的信息:
姚明,出生于中国上海,前中国篮球运动员,曾效力于NBA休斯顿火箭队。
刘翔,出生于中国上海,前中国田径运动员,曾获得奥运会110米栏冠军。
2.2 使用 spaCy 进行实体识别和关系抽取
在 Jupyter Notebook 中,使用 spaCy 进行命名实体识别(NER):
import spacy# 加载中文模型
nlp = spacy.load("zh_core_web_sm")# 示例文本
texts = ["姚明,出生于中国上海,前中国篮球运动员,曾效力于NBA休斯顿火箭队。","刘翔,出生于中国上海,前中国田径运动员,曾获得奥运会110米栏冠军。"
]# 处理文本
for text in texts:doc = nlp(text)print(f"Processing text: {text}")for ent in doc.ents:print(f"Entity: {ent.text}, Label: {ent.label_}")

2.3 将抽取的实体和关系导入 Neo4j
我们使用 py2neo 将抽取的实体和关系导入到 Neo4j(使用前要启动!):
from py2neo import Graph, Node, Relationship# 连接到 Neo4j 本地数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password(12345678)"))# 创建节点和关系
for text in texts:doc = nlp(text)entities = [ent.text for ent in doc.ents]if len(entities) >= 2:athlete = Node("Athlete", name=entities[0])location = Node("Location", name=entities[1])# 创建节点graph.merge(athlete, "Athlete", "name")graph.merge(location, "Location", "name")# 创建关系born_in = Relationship(athlete, "BORN_IN", location)graph.merge(born_in)# 打印插入信息print(f"Added {entities[0]} born in {entities[1]} to Neo4j")


2.4 在 Neo4j Desktop 中查看数据
使用 Neo4j 的 Cypher 查询语言检查插入的数据:
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a, r, l
都可以点击*和查询语言:

3. Neo4j导出数据
将 Neo4j 中的数据加载到 Protégé 进行本体管理,通常通过导出 Neo4j 的数据并转换为 OWL(Web Ontology Language)格式,再在 Protégé 中导入。以下是详细步骤:
3.1 在 Neo4j 中准备数据
确保 Neo4j 数据库中包含所有希望导入到 Protégé 的实体和关系。使用 Cypher 查询检查数据,例如:
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a, r, l
整体导出:

效果如:

3.2. 导出 Neo4j 数据
利用 Neo4j 提供的工具或 Cypher 查询将数据导出为 CSV 格式,步骤如下:
3.2.1 导出实体(如运动员和地点)
使用以下 Cypher 查询导出 Athlete 和 Location 节点为 CSV 文件(导出同上,不在截图):
// 导出运动员数据
MATCH (a:Athlete)
RETURN a.name AS Name
// 导出地点数据
MATCH (l:Location)
RETURN l.name AS Name
在 Neo4j 浏览器中,点击结果表格右上角的导出按钮,选择 “CSV” 格式。
3.2.2 导出关系(如 BORN_IN)
使用以下查询导出运动员与出生地之间的关系:
// 导出关系数据
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a.name AS Athlete, l.name AS Location
同样,将结果导出为 CSV 文件。
4. 转换为 OWL 格式
下面是几种常用的方法,将数据转换为 OWL 格式的综述,包括编程库、图形化工具和在线服务:
4.1 使用 Python 编程库
a. owlready2
- 功能: 提供一个简单的 API 来创建和管理 OWL 本体。
- 优点: 灵活、强大,适合需要编程的用户。
- 示例代码:
import pandas as pd from owlready2 import *# 创建 OWL 本体 onto = get_ontology("http://example.com/ontology.owl")# 定义类和属性 with onto:class Athlete(Thing): passclass Location(Thing): passclass BORN_IN(ObjectProperty):domain = [Athlete]range = [Location]# 读取 CSV 数据并转换 data_df = pd.read_csv('data.csv') for _, row in data_df.iterrows():athlete_instance = Athlete(row['a'].split("{name: ")[1].rstrip("}").strip('"'))location_instance = Location(row['l'].split("{name: ")[1].rstrip("}").strip('"'))athlete_instance.BORN_IN.append(location_instance)# 保存为 OWL 文件 onto.save("output.owl")
b. RDFLib
- 功能: 一个用于处理 RDF 数据的 Python 库,支持多种数据格式的转换。
- 优点: 灵活,可用于批量处理和自动化任务。
- 操作示例:
- 读取 CSV 文件并构建 RDF 图,然后使用 RDFLib 保存为 OWL 格式。
以下是一个使用 RDFLib 的简单案例,演示如何使用 Python 创建一个 RDF 图,添加一些三元组,并将其导出为 OWL 格式。
- 读取 CSV 文件并构建 RDF 图,然后使用 RDFLib 保存为 OWL 格式。
环境准备
确保你已经安装了 RDFLib。如果还没有安装,可以使用 pip 安装:
pip install rdflib
案例代码
以下代码示例演示了如何创建一个简单的 RDF 图,添加一些数据,然后将其导出为 OWL 文件。
from rdflib import Graph, URIRef, Literal, RDF, RDFS# 创建一个 RDF 图
g = Graph()# 定义命名空间
EX = URIRef("http://example.com/")# 添加类
g.add((EX.Athlete, RDF.type, RDFS.Class))
g.add((EX.Location, RDF.type, RDFS.Class))# 添加属性
g.add((EX.BORN_IN, RDF.type, RDF.Property))
g.add((EX.BORN_IN, RDFS.domain, EX.Athlete))
g.add((EX.BORN_IN, RDFS.range, EX.Location))# 添加个体
g.add((EX.LiuXiang, RDF.type, EX.Athlete))
g.add((EX.LiuXiang, RDFS.label, Literal("刘翔")))
g.add((EX.YaoMing, RDF.type, EX.Athlete))
g.add((EX.YaoMing, RDFS.label, Literal("姚明")))g.add((EX.LiuXiang, EX.BORN_IN, EX.ChinaShanghai))
g.add((EX.ChinaShanghai, RDF.type, EX.Location))
g.add((EX.ChinaShanghai, RDFS.label, Literal("中国上海")))g.add((EX.YaoMing, EX.BORN_IN, EX.Beijing))
g.add((EX.Beijing, RDF.type, EX.Location))
g.add((EX.Beijing, RDFS.label, Literal("北京")))# 保存为 OWL 文件
g.serialize(destination="output.owl", format="xml")print("RDF 图已保存为 output.owl 文件。")
代码解释
- 创建图:首先,我们创建一个新的 RDF 图。
- 定义命名空间:使用
URIRef定义一个基础的命名空间,方便后续引用。 - 添加类和属性:通过
g.add()方法添加Athlete和Location类,以及BORN_IN属性。 - 添加个体:为每个运动员和地点创建个体,并定义其标签和类型。
- 导出为 OWL:最后,将构建好的 RDF 图导出为 OWL 格式的 XML 文件。
注意事项
- 确保 RDFLib 已正确安装,并与 Python 版本兼容。
- 如果需要自定义更多复杂的关系和属性,可以在此基础上扩展代码。
选择合适的方法
- 编程用户: 使用
owlready2或RDFLib,适合需要自定义处理逻辑的场景。 - 非编程用户: 使用 Protégé 或在线工具,适合需要直观操作的用户。
- 临时处理: 在线工具提供快速解决方案,但功能可能有限。
根据你的具体需求和技术背景,可以选择最适合的方法来完成数据到 OWL 格式的转换。
4.2 其他
- Protégé插件:在 Protégé 中导入 CSV 数据通常需要使用插件,因为 Protégé 默认并不直接支持 CSV
格式的导入。这里就不在介绍。 - 使用在线工具:查找网站
5. 在 Protégé 中加载 OWL 文件和处理
4.1 打开 Protégé
启动 Protégé 应用程序。
4.2 创建或打开本体
- 新项目:点击 “File” > “New Project” 创建新本体。
- 现有项目:点击 “File” > “Open Project” 打开已有本体。

4.3 导入 OWL 文件
- 在 Protégé 菜单中,选择 File > Import…。
- 选择刚创建的 OWL 文件并点击 Next。
- 根据需要选择“完全导入”或“部分导入”。
- 点击 Finish 完成导入。
4.4 验证数据
在 Protégé 中浏览导入的类、个体和关系,确保数据正确显示并可管理。
4.5 后续步骤
- 在 Protégé 中进一步修改本体结构、添加注释、定义属性等。
- 根据需求设计新关系和类,增强本体语义。
通过这些步骤,你可以将 Neo4j 中的数据成功加载到 Protégé 中进行本体管理。
5. 案例总结
通过以上步骤,我们成功将 spaCy、Neo4j 和 Protégé 结合起来,构建了一个从文本处理到知识图谱的完整工作流。这种方法不仅提高了知识图谱构建的效率,还能够通过 Protégé 进行更加灵活的本体管理。
6. 不足与补充
- 数据质量:依赖于输入文本的质量,错误或模糊的信息可能导致不准确的实体识别。
- 扩展性:在处理复杂关系时,可能需要定义更多的关系和属性。
- 性能:在大规模数据集上运行可能会影响性能,需优化数据处理逻辑。
| 问题 | 解决方案 |
|---|---|
| 实体识别错误 | 提高模型训练数据的质量 |
| 关系定义不足 | 增加更多的关系定义和处理逻辑 |
| 性能问题 | 使用异步处理或批量操作 |
这种集成流程为从自然语言处理到知识图谱构建提供了高效的工具链,使得信息的存储和检索变得更加方便。随着项目的发展,你可以根据实际需求扩展这个流程,处理更多复杂的数据和关系。
相关阅读
- 专栏:知识图谱:从0到 ∞
- 知识图谱入门——1:基本概念、为什么要用?核心步骤、常用工具与技术、应用场景
- 知识图谱入门——2:技术体系基本概念:知识表示与建模、知识抽取与挖掘、知识存储与融合、知识推理与检索
- 知识图谱入门——3:工具分类与对比(知识建模工具:Protégé、 知识抽取工具:DeepDive、知识存储工具:Neo4j)
- 知识图谱入门——6:Cypher 查询语言高级组合用法(查询链式操作、复杂路径匹配、条件逻辑、动态模式创建,以及通过事务控制和性能优化处理大规模数据。


















