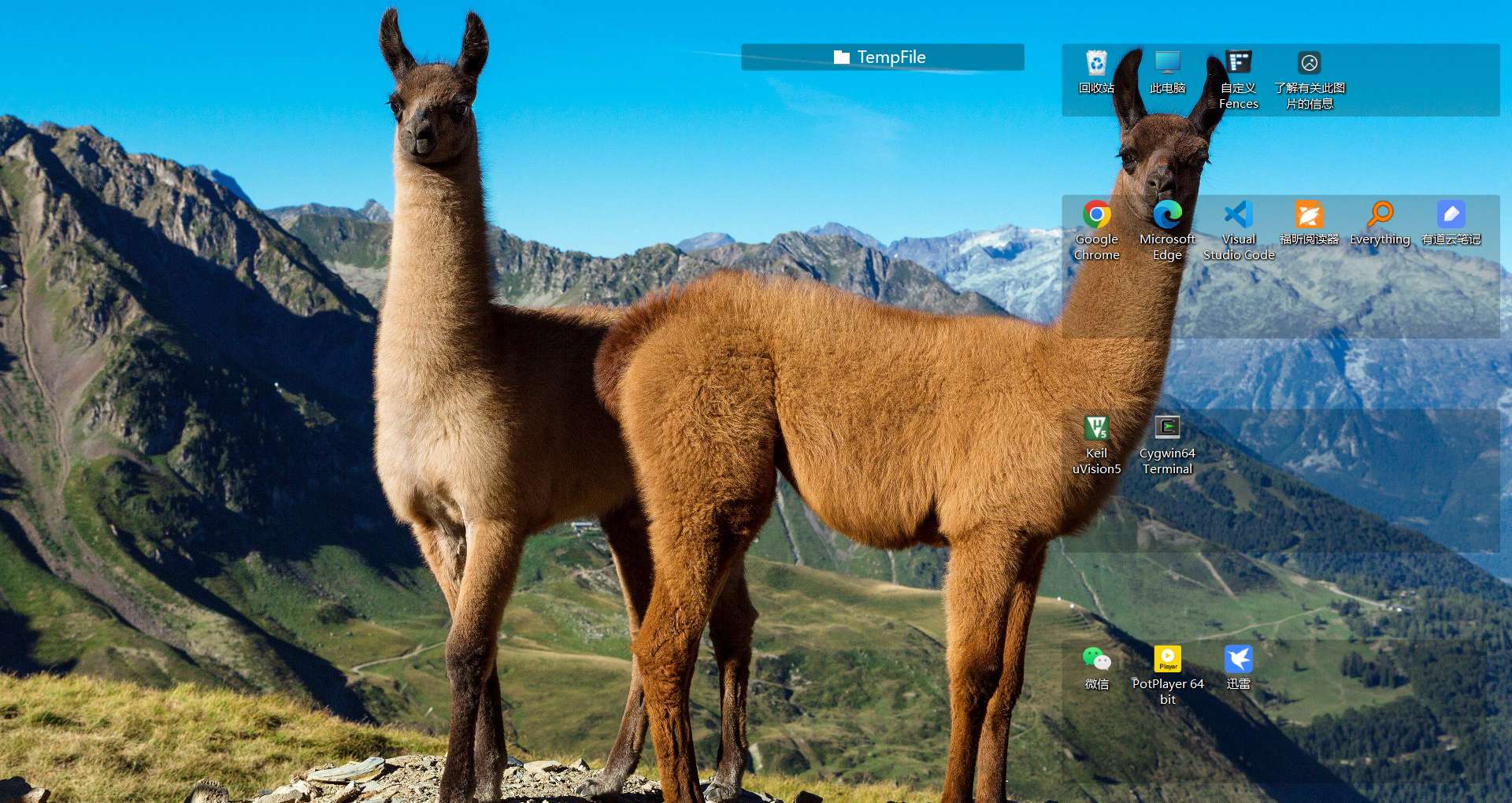
Collection 集合框架
各类集合
Set
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
HashSet
基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
List
ArrayList
基于动态数组实现,支持随机访问。
Vector
和 ArrayList 类似,但它是线程安全的。
LinkedList
基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
Queue
LinkedList
可以用它来实现双向队列。
PriorityQueue
基于堆结构实现,可以用它来实现优先队列。
Map
TreeMap
基于红黑树实现。
HashMap
基于哈希表实现。
HashTable
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
Collection 分析
ArrayList 解析
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。
自动扩容
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。
ArrayList 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[]存储,适用于频繁的查找工作,线程不安全 。Vector是List的古老实现类,底层使用Object[]存储,线程安全
LinkedList 解析
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
底层数据结构
LinkedList底层通过双向链表实现。自带头指针和尾指针指向第一个节点和最后一个节点。
LinkedList 插入和删除元素的时间复杂度?
- 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)
Map 分析
HashSet &HashMap 分析(重点)
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是线程不安全。
HashSet 通过 HashMap 的键来存储元素,而每个键的值则使用一个静态的私有对象(通常是 HashSet 的一个内部类实例),这个对象对于所有的键来说都是相同的。这样,HashSet 就可以通过 HashMap 的键来存储和查找元素。
HashSet的底层数据结构是HashMap
底层数据结构
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。 JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于等于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, HashMap 总是使用 2 的幂作为哈希表的大小。
TreeSet & TreeMap 分析
TreeSet底层数据结构是TreeMap。
TreeMap实现了SortedMap接口,也就是说会按照key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。
TreeMap的底层数据结构是红黑树实现。
红黑树介绍:
红黑树是一种近似平衡的二叉查找树,它能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍。具体来说,红黑树是满足如下条件的二叉查找树(binary search tree):
- 每个节点要么是红色,要么是黑色。
- 根节点必须是黑色
- 红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)。
- 对于每个节点,从该点至
null(树尾端)的任何路径,都含有相同个数的黑色节点。
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件3或条件4,需要通过调整使得查找树重新满足红黑树的约束条件
LinkedHashSet & LinkedHashMap 分析
LinkedHashSet 底层数据结构是LinkedHashMap。
LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。下图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。

除了可以保迭代历顺序,这种结构还有一个好处 : 迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
Queue 分析
Queue 解析
Queue接口继承自Collection接口,除了最基本的Collection的方法之外,它还支持额外的insertion, extraction和inspection操作。这里有两组格式,共6个方法,一组是抛出异常的实现;另外一组是返回值的实现(没有则返回null)。
| Throws exception | Returns special value | |
|---|---|---|
| Insert | add(e) | offer(e) |
| Remove | remove() | poll() |
| Examine | element() | peek() |
Deque 解析
Deque是"double ended queue", 表示双向的队列,英文读作"deck". Deque 继承自 Queue接口,除了支持Queue的方法之外,还支持insert, remove和examine操作,由于Deque是双向的,所以可以对队列的头和尾都进行操作,它同时也支持两组格式,一组是抛出异常的实现;另外一组是返回值的实现(没有则返回null)。
Deque既可以当做队列也可以当做栈
ArrayDeque 解析
ArrayDeque底层通过数组实现,为了满足可以同时在数组两端插入或删除元素的需求,该数组还必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点。ArrayDeque是非线程安全的(not thread-safe),当多个线程同时使用的时候,需要程序员手动同步;另外,该容器不允许放入null元素。
PriorityQueue 解析
PriorityQueue,即优先队列。优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,C++的优先队列每次取最大元素)。这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(*natural ordering*),也可以通过构造时传入的比较器(Comparator,类似于C++的仿函数)。
Java中PriorityQueue实现了Queue接口,不允许放入null元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。