在图像处理的前沿领域,多模态图像融合技术正成为研究的热点,它通过整合来自不同来源的图像数据,为我们提供了更丰富的信息维度,从而显著提升图像处理的精确度和效率。
这项技术的核心优势在于能够捕捉并融合各种图像数据中的互补信息,它不仅能够提升图像质量,还能在实际应用中解决复杂问题,适应多样化的场景需求。
目前,多模态图像融合技术已经在多个关键性能指标上达到了最先进的水平(SOTA),并在顶级会议和期刊上发表了众多论文,如2024年的TPAMI期刊上的DeepMCDL研究。
为了帮助那些需要撰写论文的同学们紧跟这一领域的最新进展,我特别整理了10个今年最新的多模态图像融合创新方案,这些方案不仅理念新颖,而且还提供了相应的代码实现。

三篇论文详解
1、SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
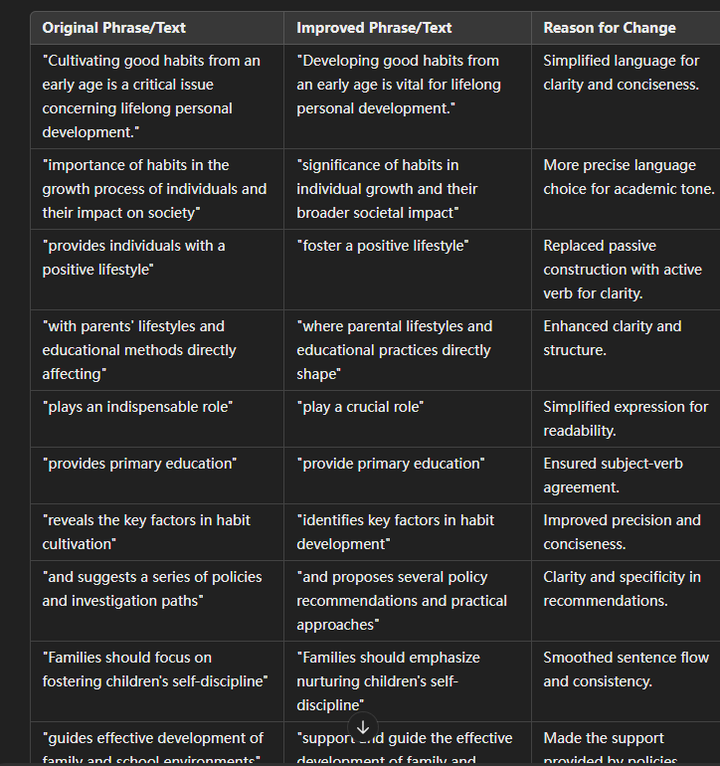
这篇文章提出了一个名为SimVG的简单而强大的视觉定位框架,用于解决视觉定位任务,即将描述性句子定位到图像的对应区域。该任务要求模型综合理解图像和文本两种模态,并建立它们之间的一致性。
研究方法:
文章首先分析了现有的视觉定位方法,发现这些方法在处理复杂的文本表达时性能显著下降。这是因为现有方法只利用有限的下游数据来适配多模态特征融合,当文本表达相对简单时才有效。因此,文章提出了一种新的方法,通过利用现有的多模态预训练模型,将视觉-语言特征融合从下游任务中解耦出来,并引入额外的对象标记来促进下游任务和预训练任务的深度整合。
创新点:
-
解耦多模态融合:文章提出了一种新颖的多模态融合方法,通过解耦视觉-语言特征融合和下游任务,使得模型能够更有效地处理复杂的文本表达。
-
动态权重平衡蒸馏(DWBD):为了在保持性能的同时简化结构并提高推理速度,文章设计了一种动态权重平衡蒸馏方法,通过在多分支同步学习过程中动态分配权重,增强了简单分支的表示能力。
-
文本引导查询生成(TQG)模块:文章引入了一个文本引导查询生成模块,将文本信息整合到查询中,使得模型能够适应文本的先验知识,并扩展其在GREC(Generalized Referring Expression Comprehension)任务中的应用。
实验验证方面:
文章在六个广泛使用的视觉定位(VG)数据集上进行了实验,包括RefCOCO/+/g、ReferIt、Flickr30K和GRefCOCO。实验结果表明,SimVG在大多数情况下都取得了最佳性能,并且在效率和收敛速度方面也有显著提升。
结论:
文章通过实验验证了SimVG框架的有效性,并得出结论,与现有的基线方法相比,无论是在性能、集成度、速度还是可解释性方面,KAN在时间序列预测中都是有效的。
总的来说,这篇文章通过提出一种新的解耦多模态融合方法和动态权重平衡蒸馏技术,有效地提高了视觉定位任务的性能,特别是在处理复杂文本表达时。此外,通过引入文本引导查询生成模块,模型能够更好地理解和定位图像中的多个目标或无目标,展示了在视觉定位任务中的新思路和方法。
2、FusionRF: High-Fidelity Satellite Neural Radiance Fields from Multispectral and Panchromatic Acquisitions
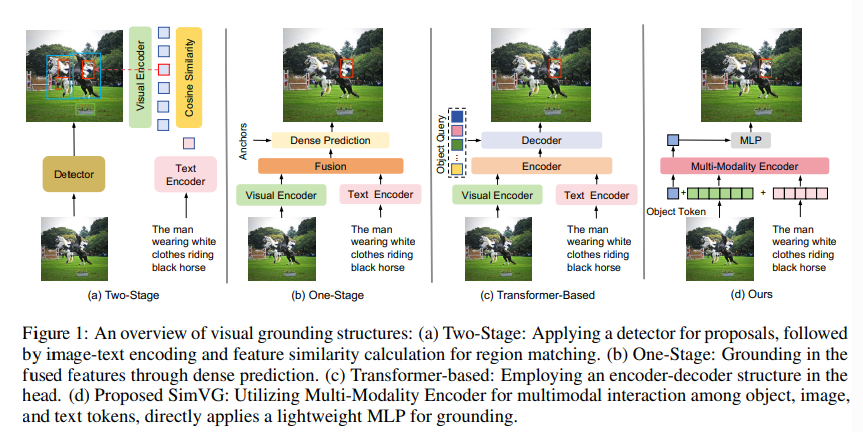
这篇文章介绍了一种名为FusionRF的新方法,用于从卫星图像中重建高保真的神经辐射场(Neural Radiance Fields)。该方法能够直接处理未经光学处理的多光谱和全色卫星图像,无需依赖外部的融合方法(如pansharpening)来结合低分辨率的多光谱图像和高分辨率的全色图像。
研究方法:
FusionRF的核心是通过引入一个锐化核来模拟多光谱图像中的分辨率损失,从而在不依赖外部预处理步骤的情况下,直接从原始图像中重建场景。此外,该方法利用了一种新颖的模态嵌入,使得模型能够将图像融合作为新视角合成的瓶颈。
创新点:
-
内置锐化核: FusionRF通过在神经网络中引入一个锐化核,模拟多光谱图像的分辨率损失,从而在模型内部实现图像的锐化处理。
-
模态嵌入: 为了处理多光谱和全色图像的融合,FusionRF引入了模态嵌入,这允许模型在保持图像光谱信息的同时,提高新视角合成的质量和清晰度。
-
无外部预处理: FusionRF不依赖于外部的图像预处理步骤,如pansharpening或颜色校正,这减少了对复杂预处理流程的依赖,并可能提高处理效率。
文章通过在WorldView-3卫星的多光谱和全色卫星图像上进行评估,展示了FusionRF在未处理图像的深度重建、新视角渲染和多光谱信息保留方面的优势。
实验验证方面:
文章进行了多个实验来验证FusionRF的性能,包括:
-
与现有技术的比较: FusionRF与现有的深度学习方法进行了比较,包括在pansharpening任务中的性能评估,以及在生成新视角图像的清晰度和深度重建准确性方面的评估。
-
消融实验: 文章通过禁用锐化核来进行消融实验,证明了锐化核对提高图像清晰度的重要性。
-
新视角合成: 文章展示了FusionRF在新视角合成任务中的性能,证明了其在保持输入图像信息方面的优势。
结论:
FusionRF通过直接处理原始卫星图像,无需外部预处理步骤,即可实现高质量的3D场景重建和新视角合成。该方法在多个评估指标上均优于现有的技术,包括在未处理图像的深度重建和新视角渲染方面的性能。
总的来说,这篇文章提出了一种新颖的方法,通过内置的锐化核和模态嵌入,实现了从未经处理的多光谱和全色卫星图像中直接重建高保真的神经辐射场。这种方法在减少对外部预处理步骤的依赖的同时,提供了一种有效的手段来提高从卫星图像中重建场景的质量和清晰度。
3、multiPI-TransBTS: A Multi-Path Learning Framework for Brain Tumor Image Segmentation Based on Multi-Physical Information
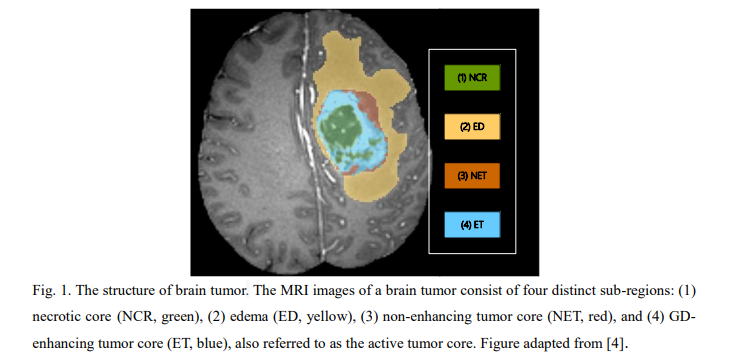
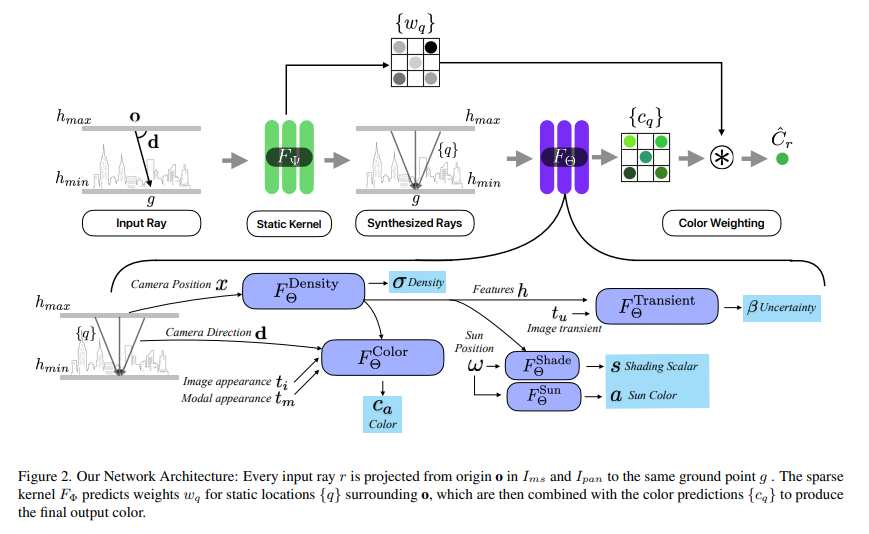
这篇文章介绍了一个名为multiPI-TransBTS的新型Transformer基础框架,旨在提高脑肿瘤图像分割的准确性。该框架通过整合多物理信息,包括空间信息、语义信息以及多模态成像数据,来解决脑肿瘤分割中的异质性问题。
研究方法:
核心在于三个主要组件:编码器、自适应特征融合(AFF)模块和多源多尺度特征解码器。编码器采用多分支架构,分别从不同的MRI序列中提取模态特定的特征。AFF模块利用通道和元素级注意力机制从多源融合信息,确保有效的特征重新校准。解码器则结合了通用和任务特定特征,通过任务特定特征引入(TSFI)策略,为全肿瘤(WT)、肿瘤核心(TC)和增强肿瘤(ET)区域产生准确的分割输出。
文章的创新点:
-
提出了基于Transformer的框架,整合多物理信息,以减少模型表示中的不确定性,从而提高分割精度。
-
构建了一个多分支网络架构,分别提取不同MRI模态的模态特定特征,避免了在特定BraTS任务中不相关模态的干扰。
-
设计了一个自适应特征融合(AFF)模块,用于融合不同MRI模态的信息,形成跨任务共享的多尺度特征。
-
开发了一个多源和多尺度特征解码器,尊重分割任务之间的差异,并充分利用了通用和个体特征。
在实验设置方面,研究使用了BraTS2019和BraTS2020数据集进行综合评估。这些数据集包括了多机构的术前MRI扫描,主要关注脑肿瘤的分割。数据集通过标准化的注释协议手动分割,并由经验丰富的神经放射科医生验证。
评估指标包括Dice系数、Hausdorff距离和敏感性。实验结果表明,multiPI-TransBTS在WT、TC和ET区域的分割任务中均优于现有的最先进方法。模型在Dice系数、Hausdorff距离和敏感性方面均取得了更好的成绩,突出了其在解决BraTS挑战中的有效性。
此外,文章还进行了消融研究,以评估multiPI-TransBTS框架中每个组件的贡献。通过与原始multiPI-TransBTS模型的比较,消融研究的结果进一步证实了该框架中每个集成组件的重要性和有效性。
总体而言,这篇文章提出的multiPI-TransBTS框架通过引入多物理信息到基于Transformer的框架中,显著提高了脑肿瘤分割任务的性能,为改善脑肿瘤患者的临床结果提供了可能性。