作者 | 张超
“除非你的广告建立在伟大的创意之上,否则它就像夜航的船,不为人所注意。”
—— 大卫·奥格威,现代广告业奠基人
01 引子
创意作为一种信息载体,将广告主的营销内容呈现给用户,辅助用户消费决策,乃至激发潜在需求。通常,创意可表现为文本、图片及视频物料的单一或组合形式,而创意优化旨在提升创意物料的业务价值,本文简要聊聊针对创意文案自动撰写的一些探索与实践,整体分五部分:第一部分简述广告文案优化的必要性;第二部分介绍文本生成相关概念及主流方法;第三部分介绍在文案生成方面的探索实践;第四部分借鉴业界研究成果,探讨文案自动生成未来的一些工作思路;最后做下小结。
广告文案优化的必要性
广告创意是连接用户和客户服务的桥梁,是信息传递最重要、最直接的方式,因此创意的质量很大程度决定了用户需求满足度和客户推广效果。
面对海量的用户需求,客户推广创意的人工运营+维护成本较高,尤其对于中小客户更难以承担,导致质量参差不齐,千篇一律,无法实现精细化的业务表达,更无法做到链路的闭环优化。
02 文本生成任务
2.1 生成框架及任务分级
文本生成在学术界称为 NLG(Nature Language Generation),广义上讲,只要输出为自然语言文本的任务均可划入文本生成的范畴。尽管 NLG 领域起源较早,但很长一段时间处于停滞状态,主要原因在于 NLG是一个简单输入到复杂输出的任务,问题复杂度太大,很难有准确高且泛化强的方法,许多场景下甚至低于人工规则。近年来,随着深度学习理论技术的成熟,NLG 领域特别是机器翻译、文档摘要等有了突破性进展。
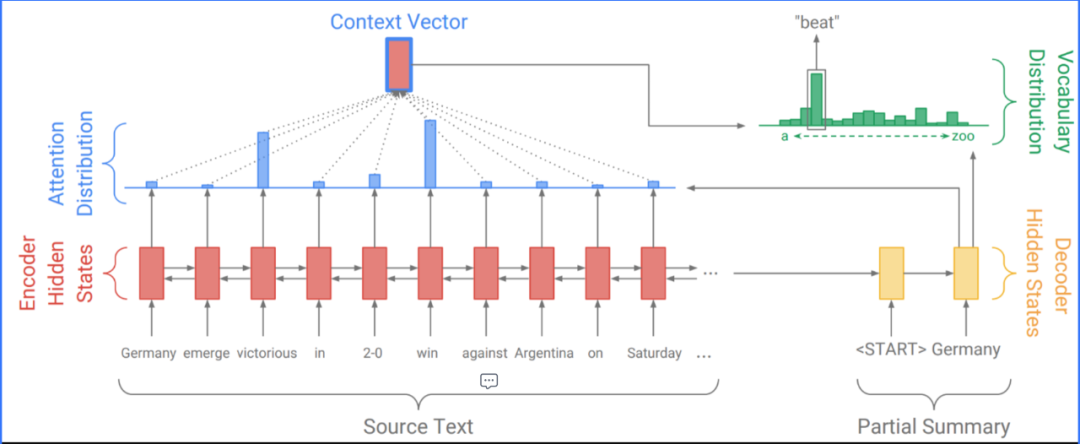
根据输入数据的形式,文本生成可细分为文本到文本(Text2Text)、数据到文本(Data2Text)以及图到文本(Image2Text)的生成。本文重点讨论Text2Text,当前业界最主流的解决方案是 Seq2Seq+Attension的序列式生成框架(如下图)。
其中:
-
编码端(Encoder):将输入序列的词(Token)映射成Embedding向量,借助深度神经网络学习到整个句子的语境表示(Contextual Representation);
-
解码端(Decoder):基于输入序列的语境表示以及已生成的词,预测当前时间步最可能的词,最终得到完整的语句;
-
注意力机制(Attention):相比固定编码端的语境表示,注意力机制通过动态调整不同输入词在每一步生成时的贡献权重,使得解码器能够抽取更关键有效的信息,进而作出更准确的决策。
Seq2Seq+Attention很好地解决了不定长输入到序列式输出的问题,是十分通用的生成方案,被广泛应用于机器翻译、摘要生成、自动对话、阅读理解等主流任务,各项核心指标取得显著提升。
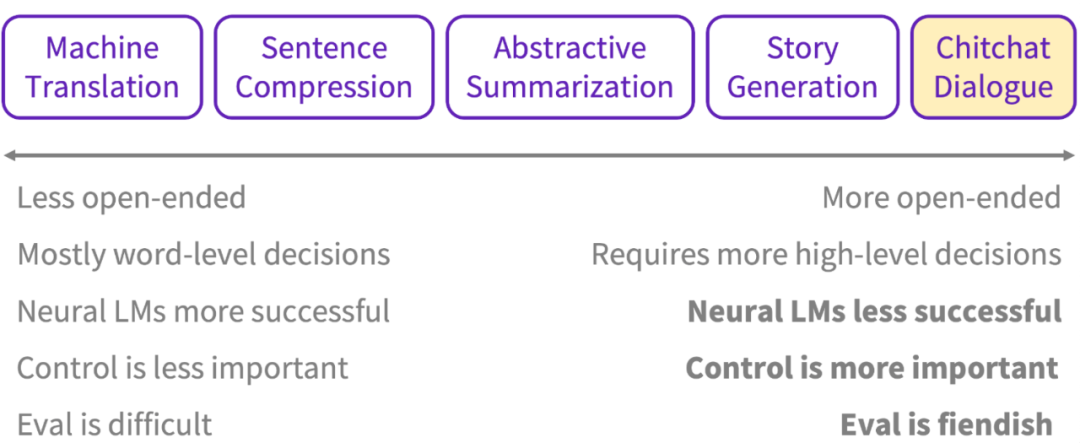
序列式文本生成框架下,根据编解码两侧的数据组织形式,分为抽取式和抽象式两种,结合实践经验,总结出各自的优劣势如下:
-
抽取式(Less open-ended):从原文抽取出关键信息,再通过编码表征和解码表达完成文本输出。其优势在于,降低任务复杂度,可解释性好,保证与原文较高的相关性;劣势在于,依赖关键信息的提取质量,同时受限于原文,泛化性不足;
-
抽象式(More open-ended):脱离原文的限制,实现完全端到端的生成,泛化能力上具有压倒式优势,但建模复杂度高,可解释性不足,控制难度较大。
2.1 文本表示的常见方法
前面提到,编码端Encoder 通过对源端输入进行建模获取语义表示。实际上解码端Decoder 生成时,同样需要获取已生成序列的语义表示。因此,如何设计模型学习文本的深层语义表示,对于最终任务的效果极为重要。
最初,词袋模型(BOW)是最常用的文本表示方法。随着深度神经网络的兴起,人们提出了一种获得词向量的词嵌入(Word Embedding)方法,以解决词汇表过大带来的“维度爆炸”问题。词/句嵌入思想已成为所有基于深度学习的NLP系统的重要组成部分,通过在固定长度的稠密向量中编码词和句子,大幅度提高神经网络处理语句乃至文档级数据的能力。
词向量的获取方式可以大体分为基于统计的方法(如共现矩阵、SVD)和基于语言模型的方法两类。2013 年Google发布基于语言模型获取词向量的word2vec框架,其核心思想是通过词的上下文学习该词的向量化表示,包括CBOW(通过附近词预测中心词)和Skip-gram(通过中心词预测附近词)两种方法,结合负采样/层级softmax的高效训练。word2vec词向量可以较好地表达不同词之间的相似和类比关系,被广泛应用于NLP任务中。

语境表示学习(Contextual Embedding Learning)解决的核心问题是,利用大量未标注的文本语料作预训练(Pre-training),学习文本的深层语境表达,进而在微调阶段(Fine-tuning)辅助监督任务更好地完成目标。
目前,语境表示学习领域代表性的工作包括 ELMO(Embeddings from Language Models)、GPT(Generative Pre-Training)和BERT(Bidirectional Encoder Representations from Transformers)。其中,ELMO模型提出根据上下文动态变化词向量,通过深层双向 LSTM 模型学习词的表示,能够处理单词用法中的复杂特性,以及这些用法在不同的语言上下文中的变化,有效解决一词多义的问题。GPT模型采用Transformer抽取文本特征,首次将Transformer应用于预训练语言模型,并在监督任务上引入语言模型(LM)辅助目标,从而解决微调阶段的灾难性遗忘问题(Catastrophic Forgetting)。相比GPT的单向LM,BERT引入双向 LM以及新的预训练目标NSP(Next Sentence Prediction),借助更大更深的模型结构,显著提升对文本的语境表示能力。业务开展过程中,我们的文本表示方法也经历了从传统RNN到全面拥抱Transformer的转变。
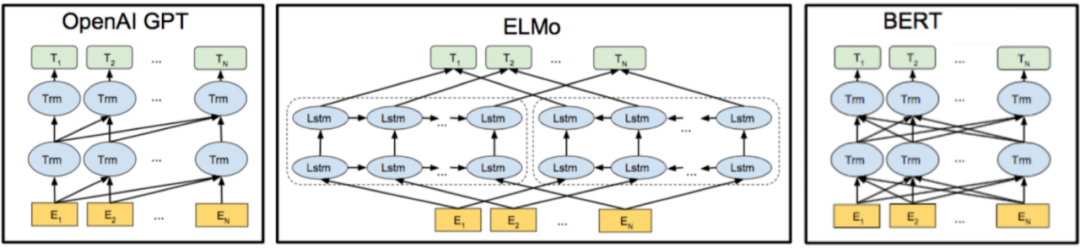
下面特别介绍同文本生成任务高度适配的MASS 预训练框架(Masked Sequence to Sequence pre-training)。我们知道,常规BERT只能用于文本理解(NLU)相关任务,如文本分类、情感识别、序列标注等,无法直接用在文本生成上,因为BERT 只预训练出一个编码器用于下游任务,而序列式文本生成框架包含编码器、解码器以及起连接作用的注意力机制。对此,微软团队提出将BERT升级至 MASS,非常适合生成任务的预训练。
MASS的整体结构如下,其训练方式仍属于无监督。对于一段文本,首先随机mask其中连续的 K 个词,然后把这些词放入Decoder的相同位置,而Encoder中只保留未被mask掉的词。借助这种学习方式,期望Decoder能综合利用Encoder的语义表达信息和Decoder前面的词,来预测这些被mask的词序列。
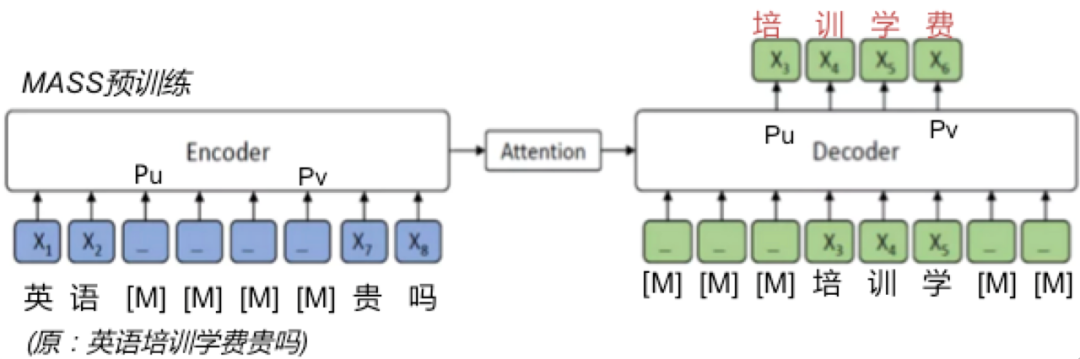
有意思的是,BERT和GPT都可视为MASS的特例。当 masked序列长度K=1时,MASS解码器端没有任何输入信息,相当于只用到编码器模块,此时MASS就退化成BERT;当 K=句子长度时,MASS编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,此时MASS便退化成GPT,或标准单向LM。

对于为什么MASS能取得比较好的效果?论文给出了以下解释:
-
Encoder中mask部分tokens,能够迫使它理解unmasked tokens,提升语义表示能力;
-
Decoder中需要预测masked的连续tokens,这同监督训练时的序列式解码相一致;
-
Decoder中只保留masked的tokens,而不是所有的tokens,促使Decoder尽量从Encoder中抽取关键信息, Attetion 机制也得到有效训练。
2.3 怎么评估生成文案的好坏
目前主流的评估方法主要基于机器指标[25]和人工评测。机器指标从不同角度自动衡量生成文本的质量,如基于模型输出概率判断是否表达通顺的perplexity,基于字符串重叠判断内容一致性的BLUE/ROUGE、判断内容多样性的Distinct-N/Self-Bleu等。基于数据的评测,在机器翻译、阅读理解等相对封闭、确定的场景下有很大意义,这也是对应领域最先突破的重要原因。对广告创意优化场景来说,除选取合适的基础机器指标作为参考,会更注重业务指向的目标优化,故多以线上实际效果为导向,辅以人工评测。
关于人工评测指标,主要看两方面:一是生成文案的基础质量,包括文本可读性及内容一致性,可读性主要看字面是否通顺、重复及是否有错别字等,一致性主要看前后语义逻辑是否一致、是否同落地页内容一致;二是内容多样性,这直接关系到用户的阅读体验及客户的产品满意度。
03 广告文案生成实践
3.1 基础数据来源
“巧妇难为无米之炊”,要开展文本创意生成的工作,业务关联数据必不可少。当前使用到的文本数据源主要包括:
-
广告展点日志:客户自提标题/描述、用户行为数据
-
广告主落地页:落地页标题、业务描述、知识文章
-
大搜日志: 自然结果展点数据
上述数据来源丰富、数据规模大,也伴随着如下挑战:
-
内容多样:数据长度分布、内容表达形式存在显著差异,对文本表示提出较高要求;
-
质量不一:虽然数据量大,实际上较大比例的数据质量并不达标,如果源端不做好质量控制,势必影响业务目标的优化;
-
场景不一:不同的业务场景下,模型优化的侧重点也不一样,对如何利用已有数据达成业务目标提出更高要求。比如广告标题与广告描述,除了优化点击率、转化率这些核心业务指标,前者更侧重内容简明扼要、准确传达客户核心业务,后者侧重内容丰富多样、允许适度做扩展延伸。
3.2 抽取式创意生成
传统意义上的「抽取式」,类如在文档摘要任务中,从段落中选出一些重要片段排列组合后作为摘要结果,不产生新信息。这里将抽取式生成表示为:从原文中抽取出一些关键信息,进行直接控制型生成(directed generation)。
在创意优化工作的开展初期,我们调研并上线了抽取式的生成策略,取得较好的指标提升。下面介绍抽取式生成在广告描述上的应用,这一方法突出优势在于生成的新文本同原文整体契合度高,也具备一定的泛化表达。
-
信息提取:广告创意中的关键信息,一般表现为核心业务/营销点/品牌词/专名等,而广告描述相对标题更长,内容形式更自然,要完整保留原文关键信息有一定难度。对此,我们采用由粗到精(coarse-to-fine)的选择策略:首先通过wordrank选出高权重词,再以片段为单位,各片段保留次高权重词/专名词,并对被切散的品牌词作策略捞回。
-
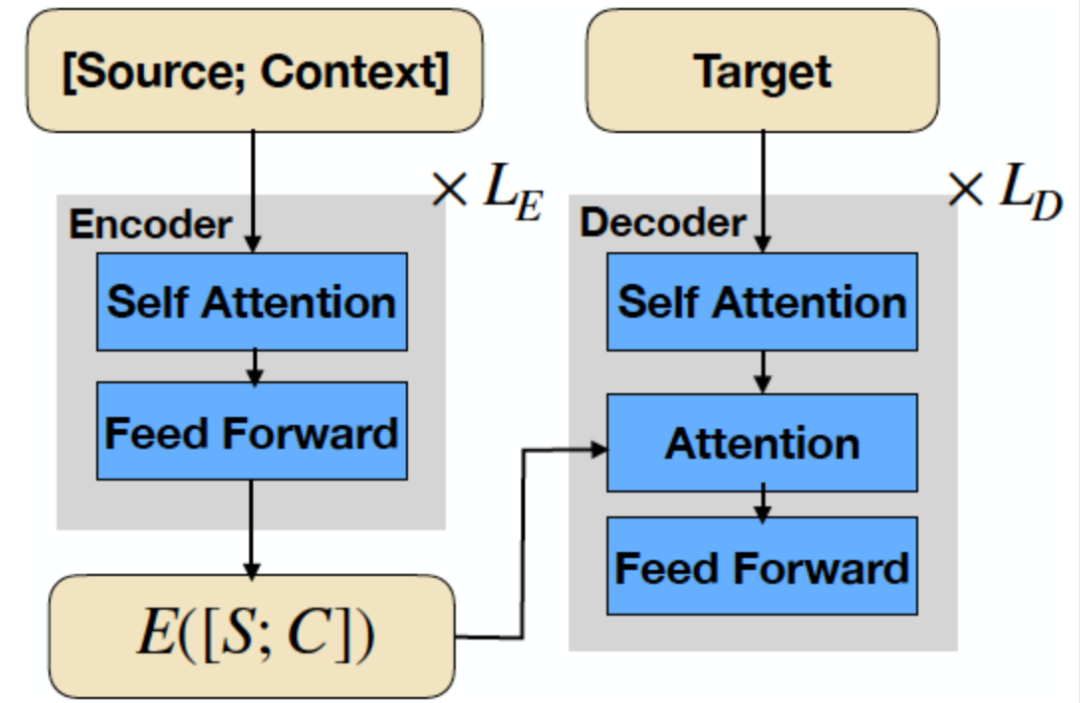
生成模型:采用Transform-based Seq2Seq文本生成框架(如下图),输入端包含Source和 Context 两部分,我们将拍卖词作为 Source,将从描述提取的关键词序列作为Context,Target对应原描述,类似”选词造句”的方式,指导模型学习将离散词组合表述成完整语句的能力。
为兼顾生成质量与业务目标的提升,我们构建了以下重要的控制机制:
-
核心业务一致:拍卖词(bidword)是用户需求及广告主业务的表达,而广告创意普遍包含拍卖词,通过将拍卖词作为 Source,在Encoder Source与Decoder Output构建起强约束(Hard Constrained),保证模型生成的内容同核心业务高度一致;
-
业务目标一致:生成模型本质是一个Language Model,训练目标是最小化词级别的交叉熵损失,而业务目标主要是优化广告点击率,这导致训练任务和业务目标不一致。对此,采样的方案是:假设核心指标同创意质量正相关,则可以按照"触发买词+触发类型+广告位置"进行分桶,分桶目的是尽量降低暴露偏差(Exposure Bias);同一桶内按核心后验指标排序,取头部的创意作为训练语料,从而指导模型学习高质量创意的内容组织与表达方式;
-
信息区分选择:Context 中关键词序列若全部来自Target,自然也引入了强约束,即输入词均将出现在输出文本中,这种情况下的约束关系同业务目标却不太契合,首先关键信息提取阶段容易引入低质噪声词,再加上模型受众主要是低质广告创意,在其内容整体欠优的情况下,强约束式生成难以保证生成质量。对此,组织训练数据时通过在 Context中随机加入一些干扰词,促使模型具备甄别Context优质信息的能力,缓解强约束式生成带来的泛化性不足以及质量问题。
3.3 抽象式创意生成
抽取式创意生成在质量和业务指标上均取得较好效果,但也存在明显瓶颈,即受限于原文,泛化能力有限,同时依赖关键信息的抽取质量,尤其原始内容整体欠优时难以完成二次优化。对此,我们尝试了抽象式的生成策略:一方面去掉Context中原文的关键信息,解除同 Target 强约束关系;另一方面,引入业务场景相关的原始文本作为指导,类似情景写作,给定当前情景的 topic以及前文信息,生成相匹配的后文。只要控制好核心主题以及业务敏感信息,抽象式生成的探索空间比抽取式开放得多,对创意内容的优化潜力显著提升。
下面介绍抽象式生成策略在广告标题上的应用。广告标题是连接用户与客户最重要的信息渠道,因此除了优化标题点击率,用户体验同样重要,即广告标题(所见)需要同广告落地页(所得)保持一致,"挂羊头卖狗肉”的现象十分有损用户体验。最直接的想法,就是将落地页的文本信息前置到广告标题中。分析发现,落地页文本在内容分布与表达方式上同广告差异较大,直接替换或部分插入的方式不太可取。对此,我们借助抽象式生成策略,将落地页信息加入Context作为指导,期望生成与之匹配且符合广告表达形式的文本,模型如下所示。
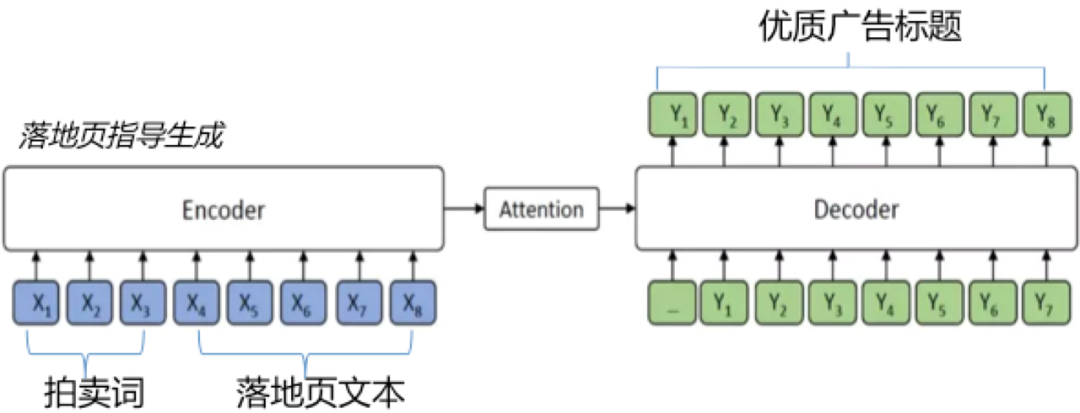
实践过程中,发现很多case 生成质量不佳(字面重复、语义不通顺),而且没有包含落地页的内容,经过分析可能有以下原因:
如前所述,抽象式生成的建模复杂度本身就高,加上训练数据中两端文本在内容分布和表达上的显著差异,进一步加大模型的学习难度;
训练数据中,Target 端广告创意包含Context中落地页信息的占比很小,此外将拍卖词作为Source(保留核心业务),不可避免地引入强约束,进一步削弱Attention 机制对落地页信息的关注,最终在解码输出时自然难以出现同落地页相匹配的内容。
针对以上问题,一方面我们引入 MASS 预训练技术、调大模型结构,另一方面基于信息校验调整训练语料,促使落地页内容更好地融入生成结果。其中,预训练环节比较有效,一定程度缓解调整后平行语料匮乏的问题,同时赋予编码端更强的语义刻画能力、attention机制更好的信息捕捉能力以及解码端更准确的信息表达能力。评估生成效果,模型能够更好参考落地页的内容,结合广告核心业务,生成体验一致的优质广告文案。

04 可借鉴的一些思路
前一节中提到业务开展过程遇到的一些问题,大部分通过模型升级、数据优化及规则校验能够得到有效解决,但对于内容一致性、内容多样性两个重要方面,解决方案并非最优,仍有较大优化空间,参考学术界相关研究,下面列举两个优化思路。
4.1 模型结构改进
目前我们采用的 Seq2Seq 生成框架(如下图),在输入端将Source和 Context 连成一个文本序列送入编码器。整体来看Source 和 Context 在任务中扮演着不同的角色,合并输入容易对编码器的语义特征提取造成干扰。比如,Context 文本一般比 Source 长,且Context往往包含一些噪声,虽然通过训练数据组织构建了强约束关系(Source拍卖词普遍出现在 Target 中),但在从模型结构上看,编码端实际弱化了 Source ,解码端很难对融合编码后的信息进行区分,不利于有效生成,甚至会出现业务偏离的梦幻case,尤其对于抽象式地生成,因为该场景下Source 与Context的内容分布通常差异较大。
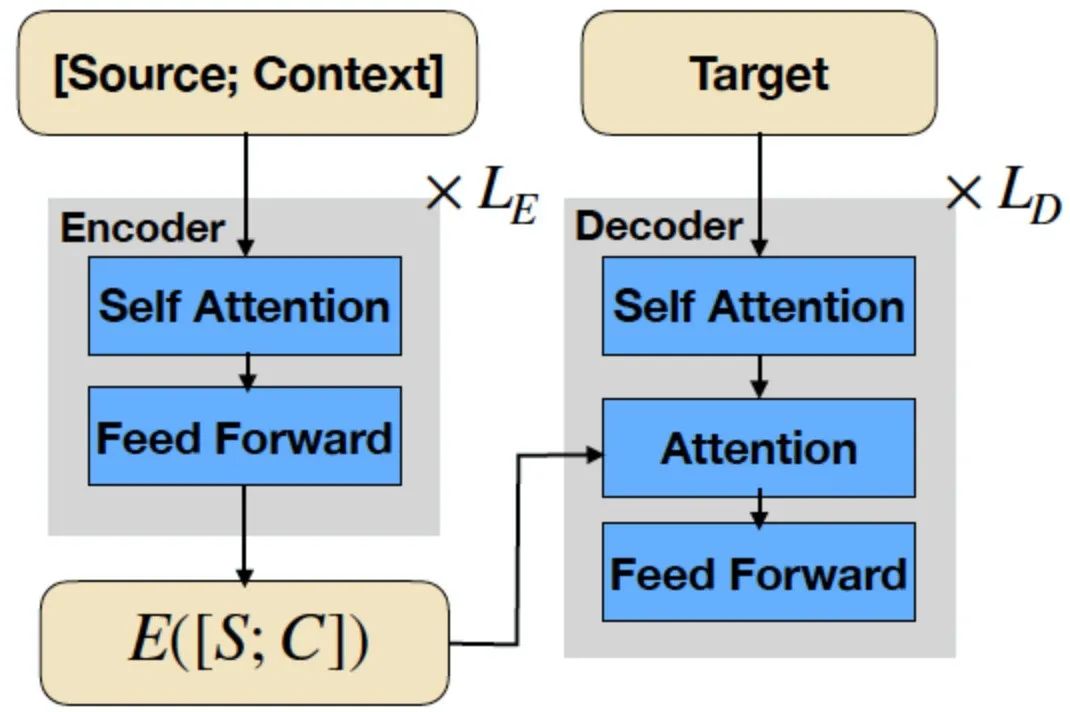
对此,有研究提出将Source 与 Context 区分开来,在输入端两者各自进行编码(见论文[13]),这样能够带来诸多好处:
-
消除编码阶段不同源数据的相互干扰,有利于改善 Encoder语义特征的提取效果;
-
允许根据具体业务需求,为不同来源的数据实施特有的编码控制策略,比如文本过长且包含噪声的 Context容易降低 Encoder 编码效果,对此可以在self-attention模块中加入Softmax temperature以影响概率分布计算结果(如下图),其中 τ 值越大将促使模型更加关注那些得分高的词,即 Context 中的重要信息
-
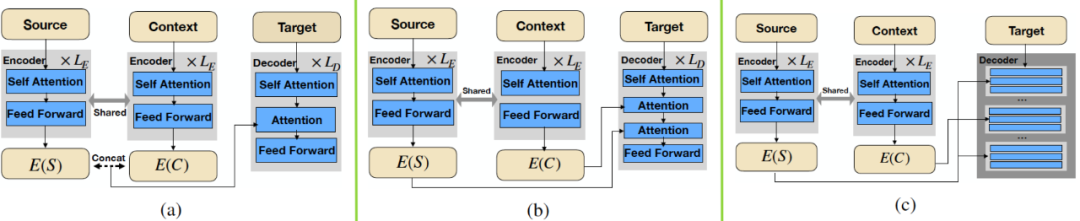
Decoder侧可根据实际需求,对多源数据的隐层表达实施不同的整合策略(如下图),其中:策略(a)直接将 Source 与 Context 的编码向量E(S)与 E©直接 Concat 送入 Decoder 的 Attention 模块;策略(b)先后对 E©与 E(S)分别作Attention,从而一方面实现 Source 与 Context 的信息交互,更加强了 Source对于解码输出的控制,这一策略有助于提升生成文本同 Source 的一致性;策略©在(b)的基础上,通过多轮交替式的 Attention 进一步加强 Source 与 Context 的信息交互。
-
对Context单独编码,便于后续引入更多类型的数据,比如结构化知识、客户属性、用户个性化特征,甚至跨模态的图片/视频向量表达。
此外,论文提出一种数据增强策略,实验论证各项评估指标取得显著提升,具体是:对于每条训练数据(表示为 <S, C> -> T),以一定概率构造S->T或者S->C的新语料,前者指导模型生成与 Source 更相关的内容,后者一方面促使编码器从 Source 提取到与 Context 更相关的信息、另一方面由于 Context 要比 Source 长许多,可视为对解码器作LM预训练。
4.2 外部知识增强
无论是抽取式还是抽象式,生成目标都是对输入信息进行合理准确的扩展与泛化,实际解码预测时主要基于编码器对输入信息的理解表示,输出概率最大的序列。因此,编码器是否能够充分理解输入文本,决定了最终生成的效果。
在人工评测时发现许多"标题党"、"万金油”式的生成文本,比如”XXX,告诉你一个简单的解决方法”、”XXX是一家集研发、生产、销售为一体的公司”、”XXX,欢迎点击咨询”等,在对话任务中称这类现象为"general and meaningless response”。出现这种现象主要在于,仅仅依靠 Source/Context 自身文本,在语义编码阶段难以对业务实体、专名等概念类的词进行充分理解和表示,加之数据驱动的模型容易”偷懒”,从而导致生成文本偏短、偏通用化、业务实体缺失/偏离。
常规解决方法是调整/扩充训练语料、在Decoder端加入相关控制策略,一定程度上能够缓解。实际上,Seq2Seq的生成任务普遍存在上述问题,对此,目前业界广泛研究且验证有效的方案是引入外部常识性知识(commonsense knowledge),辅助指导模型作出更全面、更准确的决策。对于如何利用外部知识,一类做法是在监督训练之前,基于知识物料作预训练,加深模型对实体信息的理解,训练语料通常是"实体+描述性定义",如”主机游戏,又名电视游戏,包含掌机游戏和家用机游戏两部分,是一种用来娱乐的交互式媒体”;另一类做法是在监督训练阶段,先从 Source 和 Context 文本中提取出一系列实体词,将实体词作为索引从通用知识库中检索出对应的Knowledge信息,借助 memory 机制将其融入模型中(如下图),实现<Source,Context,Knowledge>三者共同作用训练与生成,具体实现细节见论文[14]。

05 小结
针对文本生成的一系列节点,从模型结构到优化目标,从数据组织到任务迁移,业界不断涌现出众多优秀的研究及实践成果,如大规模预训练模型(ERNIE/PLATO/T5/BART)、图谱知识嵌入、Memory机制、跨模态/跨场景联合建模等等,为技术业务迭代给予很好的借鉴指导,后续有机会再交流,感兴趣的同学可参考[15]~[24]相关资料,欢迎讨论交流。
————END————
参考资料:
[1]Neural machine translation by jointly learning to align and translate,arXiv:1409.0473
[2]Attention Is All You Need,arXiv:1706.03762
[3]ELMO:Deep contextualized word representations,arXiv:1802.05365
[4]OPAI GPT: Improving Language Understanding by Generative Pre-Training
[5]Bert: Pre-training of deep bidirectional transformers for language understanding,arXiv:1810.04805
[6]MASS: Masked Sequence to Sequence Pre-training for Language Generation,arXiv:1905.02450
[7]Generating sequences with recurrent neural networks,arXiv:1308.0850
[8]Distributed Representations of Words and Phrases and their Compositionally, arXiv:1310.4546
[9]Get To The Point: Summarization with Pointer-Generator Networks,arXiv:1704.04368
[10]Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization,arXiv:1808.08745
[11]Pre-trained Models for Natural Language Processing: A Survey,arXiv:2003.08271
[12]Do Massively Pretrained Language Models Make Better Storytellers? ,arXiv:1909.10705
[13]Improving Conditioning in Context-Aware Sequence to Sequence Models,arXiv:1911.09728
[14]CTEG: Enhancing Topic-to-Essay Generation with External Commonsense Knowledge
[15]Unified Language Model Pre-training for Natural Language Understanding and Generation,arXiv:1905.03197
[16]Knowledge Diffusion for Neural Dialogue Generation
[17]Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model,arXiv:1906.01231
[18]Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting,arXiv:1805.11080
[19]What makes a good conversation? How controllable attributes affect human judgments,arXiv:1902.08654
[20]The curious case of neural text degeneration,arXiv:1904.09751
[21]Straight to the Gradient: Learning to Use Novel Tokens for Neural Text Generation,arXiv:2106.07207
[22]Towards Facilitating Empathic Conversations in Online Mental Health Support: A Reinforcement Learning Approach,arXiv:2101.07714
[23]ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation,arXiv:2001.11314
[24]PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable,arXiv:1910.07931
[25]Evaluation of Text Generation: A Survey,arXiv:2006.14799
推荐阅读:
百度工程师教你玩转设计模式(适配器模式)
百度搜索业务交付无人值守实践与探索
分布式ID生成服务的技术原理和项目实战
揭秘百度智能测试在测试评估领域实践
再添神器!Paddle.js 发布 OCR SDK
视频中为什么需要这么多的颜色空间?