在本篇文章中,我们将深入探讨如何使用Python对UCI人类活动识别(HAR)数据集进行分割和预处理,以及运用模型网络CNN对数据集进行训练仿真和可视化解读。
一、UCI-HAR数据集分析及介绍
UCI-HAR数据集是一个公开的数据集,旨在通过智能手机传感器数据进行人类活动识别。这个数据集由30名志愿者在进行日常生活活动时携带带有嵌入式惯性传感器的腰部智能手机生成。数据集中的活动包括行走、上楼梯、下楼梯、坐着、站立和躺着等六种基本活动。
UCI-HAR数据集提供了原始的采样数据和经过预处理的数据。原始数据包括加速度计和陀螺仪的三轴数据,而预处理后的数据则包括时域和频域的特征向量。数据集中的每个样本都包含了丰富的特征信息,如加速度和角速度数据,以及从这些数据中提取的561种特征向量。
执行的六项活动如下:
Walking;Walking Upstairs;Walking Downstairs;Sitting;Standing;Laying
二、UCI-HAR数据集分割及处理
1.环境设置
在正式开始实验前,我们需要确保Python环境中安装了以下库:
numpy:用于高效的数值计算。pandas:用于数据分析和处理。os和sys:Python标准库,用于操作系统级别的操作。
2.数据集下载
首先,我们需要下载UCI-HAR数据集,通过设定一个单独的 download_dataset 函数完成,下载数据集并将其保存到指定的目录,这是下载链接:https://archive.ics.uci.edu/static/public/240/human+activity+recognition+using+smartphones.zip
download_dataset(dataset_name='UCI-HAR',file_url='https://archive.ics.uci.edu/static/public/240/human+activity+recognition+using+smartphones.zip', dataset_dir=dataset_dir
)
3.数据预处理
3.1读取数据
预处理的第一步是将文本格式的数据转换为numpy数组,通过自定义的 xload 和 yload 函数完成。
def xload(X_path):# 遍历每个信号类别的文件路径x = []for each in X_path:# 打开文件,读取每一行,分割字符串并转换为浮点数数组with open(each, 'r') as f:x.append(np.array([eachline.replace(' ', ' ').strip().split(' ') for eachline in f], dtype=np.float32))# 转置数组以匹配预期的形状x = np.transpose(x, (1, 2, 0))return x
xload 函数接收一组文本文件路径,逐行读取数据,去除空白字符,分割字符串,并将每个信号的数据转换为浮点数格式。然后,它通过转置操作调整数据的形状以匹配后续处理的需要。
3.2标签处理
yload 函数用于读取标签数据,并将它们转换为从0开始的整数数组。
def yload(Y_path):# 使用pandas读取CSV文件,转换为numpy数组,并重塑为一维数组y = pd.read_csv(Y_path, header=None).to_numpy().reshape(-1)# 将标签转换为从0开始的整数return y - 1
4.数据分割
UCI-HAR数据集已经预先分割为训练集和测试集。在本次的实验中,我们定义了训练集和测试集的文件路径,并使用 xload 和 yload 函数加载数据。
X_train_path = [dataset + '/train/Inertial Signals/' + signal + 'train.txt' for signal in signal_class]
X_test_path = [dataset + '/test/Inertial Signals/' + signal + 'test.txt' for signal in signal_class]
Y_train_path = dataset + '/train/y_train.txt'
Y_test_path = dataset + '/test/y_test.txt'X_train = xload(X_train_path)
X_test = xload(X_test_path)
Y_train = yload(Y_train_path)
Y_test = yload(Y_test_path)
5.数据保存
预处理后需要将数据保存起来,供下面的训练仿真与可视化使用。这里,我们使用 save_npy_data 函数将数据保存为 .npy 文件。
if SAVE_PATH: # 如果提供了保存路径save_npy_data(dataset_name='UCI_HAR',root_dir=SAVE_PATH,xtrain=X_train,xtest=X_test,ytrain=Y_train,ytest=Y_test)
6.结果展示
最后,输出=出训练集和测试集的形状,以确认数据加载和预处理是否正确。
print('xtrain shape: %s\nxtest shape: %s\nytrain shape: %s\nytest shape: %s' % (X_train.shape, X_test.shape, Y_train.shape, Y_test.shape))
输出结果:
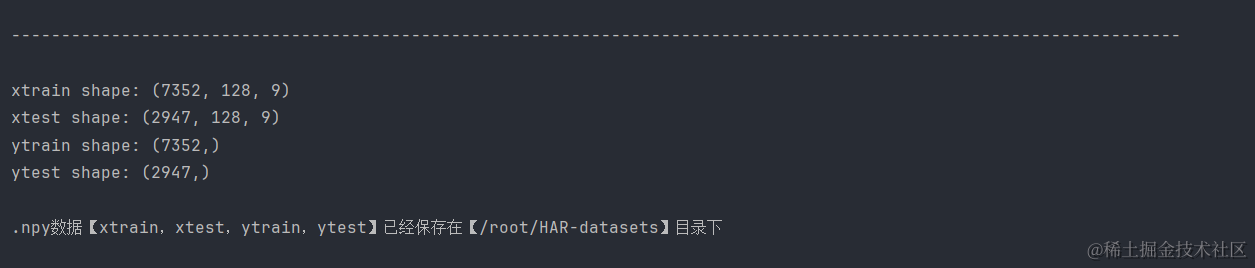
输出结果给出了每个集合的维度信息, X_train.shape 输出 (7352, 128, 9),表示训练集有7352个样本,每个样本有128个时间步长的数据,每个时间步包含9个特征(对应于信号类别)。
通过上述步骤,我们完成了UCI-HAR数据集的下载、预处理、分割和保存。这些步骤为下面的训练仿真与可视化使用任务奠定了基础。预处理后的数据可以直接用于训练模型,而不需要从头开始处理原始数据集。
三、CNN网络训练UCI-HAR数据集
CNN网络我们在之前的文章中已经很详细的介绍了,这里并不做过多的解读。
1.环境设置
确保你的环境中安装了以下Python库:
torch:PyTorch深度学习框架。numpy:用于高效的数值计算。sklearn:用于模型评估。argparse:用于解析命令行参数。
2.参数解析
首先,我们使用 argparse 库来定义和解析命令行参数,这包括数据集、模型、保存路径、批次大小、训练轮数和学习率等。
def parse_args():# ... 省略部分代码 ...args = parser.parse_args()return args
3.主执行流程
在主执行流程中,我们首先定义了数据集和模型的字典,选择想要训练的网络模型。
if __name__ == '__main__':# ... 省略部分代码 ...args = parse_args()# ... 省略部分代码 ...
4.数据集加载与预处理
加载数据集,并将其转换为PyTorch需要的张量格式:
X_train = torch.from_numpy(train_data).float().unsqueeze(1)
X_test = torch.from_numpy(test_data).float().unsqueeze(1)
Y_train = torch.from_numpy(train_label).long()
Y_test = torch.from_numpy(test_label).long()
5.模型构建
构建相应的CNN模型,并将其发送到合适的设备(GPU或CPU)。
net = model_dict[args.model](X_train.shape, category).to(device)
6.训练与评估
接下来,我们定义了优化器、学习率调度器、损失函数,并使用混合精度训练来提高训练效率。
optimizer = torch.optim.AdamW(net.parameters(), lr=LR, weight_decay=0.001)
lr_sch = torch.optim.lr_scheduler.StepLR(optimizer, EP // 3, 0.5)
loss_fn = nn.CrossEntropyLoss()
scaler = GradScaler() # 在训练最开始之前实例化一个GradScaler对象
然后,我们进入训练循环,每个epoch都包括模型训练和评估。
for i in range(EP):net.train()inference_start_time = time.time()for data, label in train_loader:data, label = data.to(device), label.to(device)# 前向过程(model + loss)开启 autocast,混合精度训练with autocast():out = net(data)loss = loss_fn(out, label)optimizer.zero_grad() # 梯度清零scaler.scale(loss).backward() # 梯度放大scaler.step(optimizer) # unscale梯度值scaler.update()lr_sch.step()
7.可视化结果展示
7.1 准确率、精确率、召回率、F1分数、推理时间
在每个epoch结束后,输出准确率、精确率、召回率、F1分数、推理时间。
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
report = classification_report(all_labels, all_preds, output_dict=True, zero_division=1)
precision = report['weighted avg']['precision']
recall = report['weighted avg']['recall']
f1_score = 2 * precision * recall / (precision + recall)
# 计算推理时间
inference_end_time = time.time()
inference_time = inference_end_time - inference_start_time
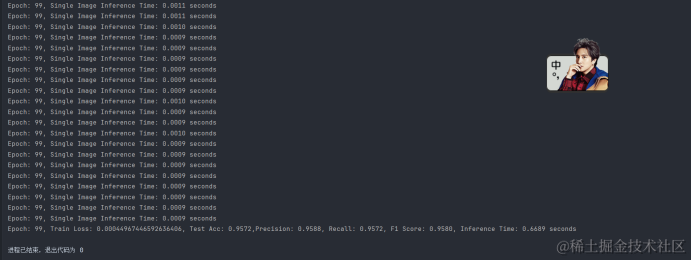
最后得到的准确率、精确率、召回率、F1分数、推理时间分别是:Test Acc:0.9572,Precision: 0.9588,Recall: 0.9572,F1 Score: 0.9580,Inference Time: 0.6689 seconds。
根据上述性能指标,我们可以看出所训练的CNN模型在UCI-HAR数据集上取得了非常优异的性能。准确率、精确率、召回率和F1分数均超过了95%,显示出模型具有很高的分类准确性和鲁棒性。同时,较短的推理时间意味着该模型可以有效地应用于需要快速响应的实际问题中。
接下来,我们将介绍混淆矩阵、雷达图、准确率与损失率的收敛曲线图以及仿真指标的柱状图和折线图的生成方法。
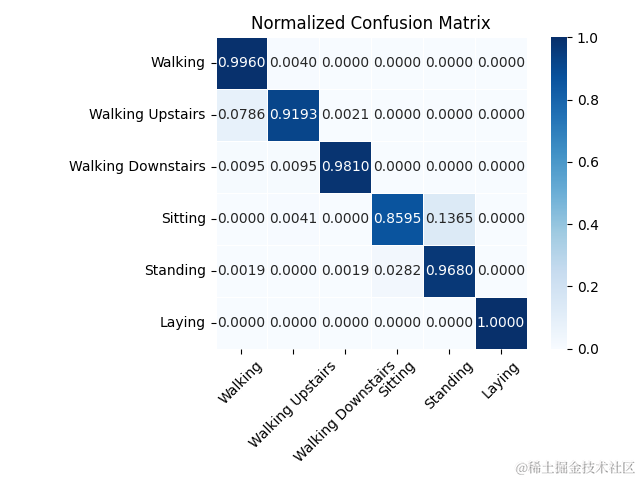
7.2混淆矩阵图
混淆矩阵是一个重要的工具,用于可视化模型在各个类别上的性能。我们首先计算归一化的混淆矩阵,然后使用seaborn的heatmap函数进行绘图。
conf_matrix = confusion_matrix(all_labels, all_preds, normalize='true')
# 自定义类别标签列表
class_labels = ['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying']# 使用 seaborn 的 heatmap 函数绘制归一化的混淆矩阵
ax = sns.heatmap(conf_matrix, annot=True, fmt='.4f', cmap='Blues',xticklabels=class_labels, yticklabels=class_labels,square=True, linewidths=.5)
输出混淆矩阵图:
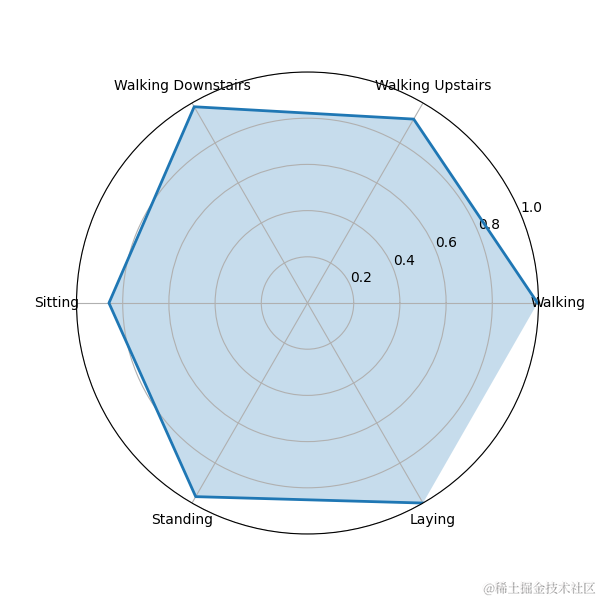
7.3雷达图
雷达图可以展示模型在不同类别上的识别能力。我们使用matplotlib绘制每个行为的雷达图。
# 绘制雷达图
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))# 绘制每个行为的雷达图
ax.plot(angles, beh, linestyle='-', linewidth=2)
ax.fill(angles, beh, alpha=0.25)# 设置雷达图的刻度和标签
ax.set_xticks(angles)
ax.set_xticklabels(['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying'])
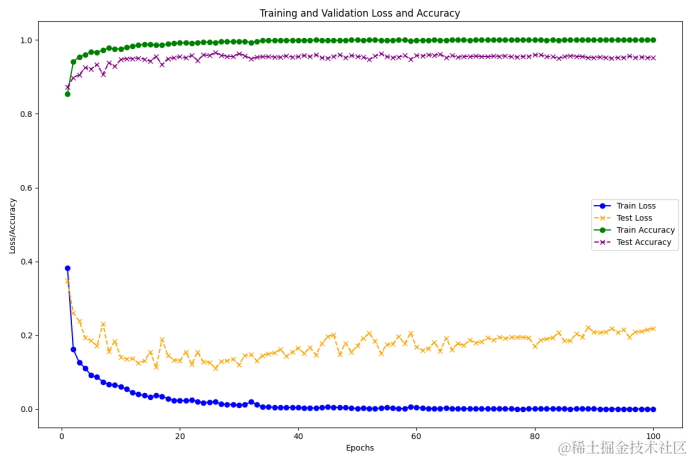
7.4准确率和损失率的收敛曲线图
通过绘制训练损失和测试损失,以及训练准确率和测试准确率的收敛曲线图,我们可以观察模型在训练过程中的稳定性和泛化能力。
# 绘制训练损失和测试损失
plt.plot(range(1, EP + 1), train_losses, label='Train Loss', color='blue', marker='o')
plt.plot(range(1, EP + 1), test_losses, label='Test Loss', color='orange', linestyle='--', marker='x')# 绘制训练准确率和测试准确率
plt.plot(range(1, EP + 1), train_accuracies, label='Train Accuracy', color='green', marker='o')
plt.plot(range(1, EP + 1), test_accuracies, label='Test Accuracy', color='purple', linestyle='--', marker='x')
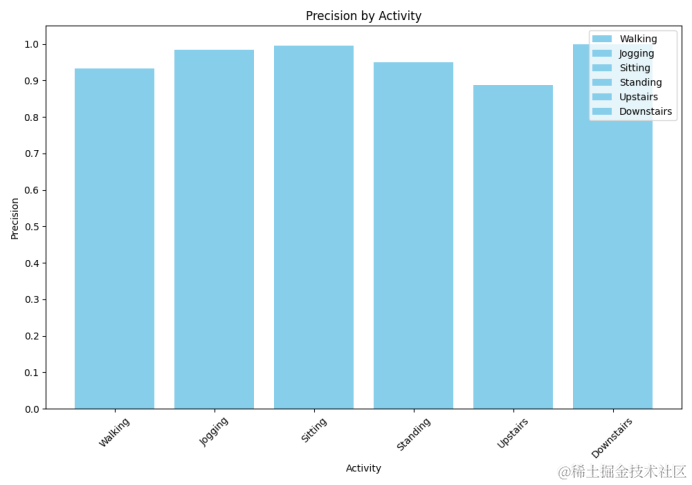
7.5仿真指标柱状图
柱状图可以展示模型在不同类别上的精确率,有助于识别模型在哪些类别上表现更好或更差。
# 自定义类别标签列表
class_labels = ['Walking', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Downstairs']# 计算每个类别的精确率
precisions = {}
for label in unique_labels:# 为当前类别创建一个二进制的标签数组y_true = np.where(all_labels == label, 1, 0)y_pred = np.where(all_preds == label, 1, 0)# 计算当前类别的精确率# 设置 average 参数为 'binary',因为我们现在是针对每个类别单独计算precision = precision_score(y_true, y_pred, average='binary')precisions[label] = precision
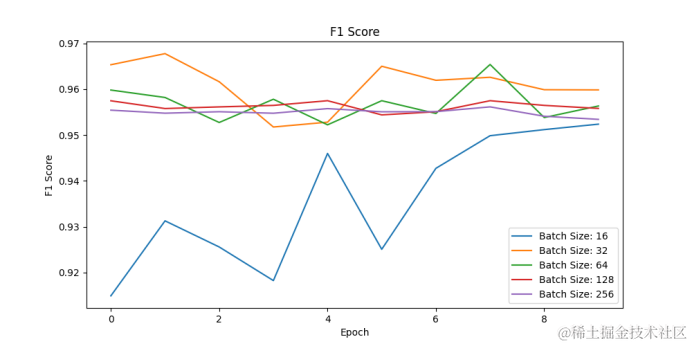
7.6仿真指标折线图
通过改变批处理大小并进行多次实验,我们可以评估批处理大小对模型性能的影响。
# 进行多次实验,每次使用不同的批处理大小
batch_sizes = [16, 32, 64, 128, 256]
f1_scores_per_batch = {BS: [] for BS in batch_sizes}
for BS in batch_sizes:f1_scores_per_batch[BS] = train_and_evaluate(BS, 10, LR)# 绘制不同批处理大小下的加权F1分数
plt.figure(figsize=(10, 5))
for BS, f1_scores in f1_scores_per_batch.items():plt.plot(f1_scores, label=f'Batch Size: {BS}')
在这一部分,我们展示了如何对CNN网络训练的UCI-HAR数据集进行性能评估和可视化。通过混淆矩阵、雷达图、收敛曲线图以及柱状图和折线图,我们可以全面了解模型的性能,并识别模型在不同类别上的表现。这些可视化工具对于模型的调试和优化至关重要。
注意:具体的代码实现和模型细节可以联系作者获取,以便进一步的研究和应用。本文首发于稀土掘金,未经允许禁止转发和二次创作,侵权必究。