知乎:啦啦啦啦(已授权)
链接:https://zhuanlan.zhihu.com/p/902522340
论文:O1 Replication Journey: A Strategic Progress Report
链接:https://github.com/GAIR-NLP/O1-Journey
这篇论文记录了一次o1复现尝试,用的方法是自己提出的Journey Training。在此之前,先看作者给出的最终结果: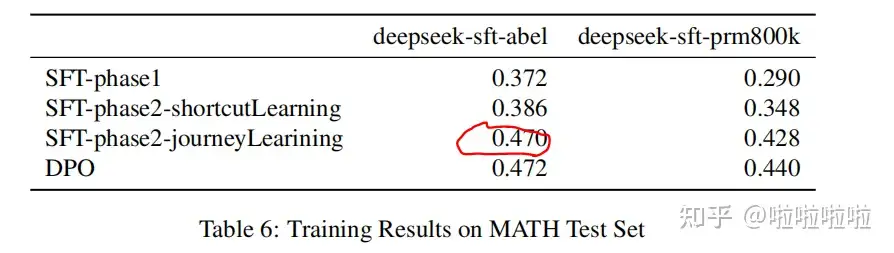 SFT-phase2-journeyLearining 比一般的SFT(即SFT-phase2-shortcutLearning)性能高8%左右。
SFT-phase2-journeyLearining 比一般的SFT(即SFT-phase2-shortcutLearning)性能高8%左右。
SFT-Journey Training 基本做法
先用模型M对327个已知答案的样本进行极长COT思维链的构造。构造过程就是运用常规的树搜索,树分岔的方式是按推理步骤分叉。搜到一些正确路径,例如
question->step0->step1->....->step6->right_answer (这类样本叫shotcut)
还有错误路径,例如
question->step0'->step1'->....->step6'->wrong_answer
极长思维链等于
"question->step0'->step1'->....->step6'->wrong_answer"+ "emmm, 好像不太对,我想一下" + "step0->step1->....->step6->right_answer"
构造完毕。这个样本就叫journey。同一个样本,错误COT路径的数量可以任意多(上面例子只有一个),串联在一起,只要中间加上伪思考语句过渡就好(这种过渡语句由GPT4o润色,比如 “emm,不太对,我看一下”, 哈哈)。正确路径和错误路径并不是毫无关系,错误路径是沿着搜好的正确路径伪造的,还用了深度优先搜索,所以整个journey描述的其实是一次成功的、裁剪过(不然错误路径太多)的深度优先搜索的伪历史。
实验
作者用上面模型M构造的327个极长思维链数据,对模型M进行SFT。为了对比,同时用对应的327个常规短思维链数据(shotcut),对模型进行SFT。发现前者比后者提升了8%正确率。
个人看法
我觉得是不是应该再做个实验对比:把正确答案的shotcut和错误答案的shotcut进行DPO(图1的DPO指的不是这个意思)。以此证明Journey Training比一般的强化学习DPO效果好?
而且,一般认为这样的正样本和错样本拼接在一起或者类似的自我纠错路径直接进行sft,会导致模型崩溃?即模型只学会正确答案,不会有太多自我反思能力的提升。这个问题可以下载这篇论文的原文看一下
https://zhuanlan.zhihu.com/p/843436108
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦