目录
- 一、主从复制介绍
- 二、搭建主从复制
- 三、主从复制流程
- 四、关于Replication ID
- 五、主从复制核心知识
- 六、主从复制应用场景
- 七、主从复制的注意事项
- 八、读写分离实战
一、主从复制介绍
1、什么是主从复制?

2、为什么要使用主从复制?
- redis-server单点故障。
- 单节点QPS有限。
3、主从复制应用场景分析?
读写分离场景,规避redis单机瓶颈
故障切换,master出问题后还有slave节点可以使用
二、搭建主从复制
主节点以普通模式启动即可,从节点可以在命令行或者在配置文件中开启复制。
1、第一种方式:命令行
# 连接主redis服务器
replicaof[ip] [port]
2、第二种方式:修改从节点配置文件redis.conf
# 配置文件增加
replicaof[ip] [port]
# 从服务器是否只读,默认yes
replicaof-read-only yes
3、退出主从集群的方式
replicaof no one
4、副本进行master密码验证
当主节点有密码设置时,我们需要在从节点配置主节点的密码,进行连接认证。
- 命令行方式:
config set masterauth <password>
- 修改redis.conf配置文件:
masterauth <password>
5、限制master主节点写请求
从Redis2.8开始,支持配置只有当至少N个副本连接上master时,master才接收写请求。因为Redis使用的是异步复制,所有不能确保副本实际能接收到给定的命令写入,会有一定的数据丢失窗口。
异步复制流程如下:
Redis副本每秒ping一次master,确认处理的偏移量。Redis master会记住每个副本ping的最后时间。- 用户可以配置ping延迟不超过指定秒数的最小副本数。
如果有至少N个副本连上master,且ping的延迟小于M秒,那么写请求会被接收,否则会回复错误,该特性的配置参数如下:
min-replicas-to-write <number of replicas>
min-replicas-max-lag <number of seconds>
备注:这里的副本就是从节点,master就是主节点。
6、查看主从复制信息
info replication
三、主从复制流程

- 从服务器通过
psync命令发送旧的主服务器Replication ID和处理的偏移量。 - master收到请求后,如果发送的Replication ID为当前master的,则根据当前偏移量增量同步。
- 如果副本发送的
Replication ID为非当前master的,则进入全量同步:master通过bgsave生成rdb,通过网络传输到副本,副本再加载到内存中(此过程会阻塞)。
四、关于Replication ID
1、Replication ID是什么
Replication ID代表数据集的历史记录,每次master重启或者副本晋升为master,会生成新的Replication ID。副本在与master握手后会继承master的Replication ID。
2、为什么Redis实例会有两个Replication ID
因为副本会晋升为master,故障转移后,晋升的副本仍需记住过去的Replication ID(即前master的ID),新的master会生成一个新的Replication ID作为主ID,旧master的ID作为次ID。
当其它副本与新master进行同步时,副本会用旧master的Replication ID带上偏移量进行部分复制,而不是全量复制。
3、为什么晋升的副本需要修改Replication ID
旧master由于网络分区(无法与其它Redis实例通信),可能仍在充当master的角色,如果晋升的新master继续使用旧master的Replication ID,会违反任意两个具有相同ID和offset的Redis实例有相同数据集的事实。
简而言之,新master和旧master的Repilcation ID和offset虽然都相同,但由于网络分区,晋升为新master的副本与旧master偏移量不一致。
当新master偏移量增长到与旧master相同时,此时数据并不一定一致,而Replication ID和offset是标识唯一数据集的。
五、主从复制核心知识
- Redis默认使用异步复制,从节点和master之间异步确认处理的数据量。
- 一个master可以拥有多个从节点。
- 从节点可以接受其它从节点的连接,从节点可以有下级子从节点。
- 主从同步过程在master侧是非阻塞的,当一个或多个从节点进行初始全量同步或者部分同步,master仍然能处理查询请求。
- 从节点端大部分情况下也是非阻塞的,当从节点进行初始全量同步时,仍然能用旧的数据集处理查询请求(可在配置文件中配置)。
- 从节点初次同步需要删除旧数据,加载新数据,加载新数据集的过程中会阻塞到来的连接请求。

六、主从复制应用场景
- 主从复制可以用来支持读写分离。
- 从节点服务器设定为只读,可以用在数据安全的场景下。
- 可以使用主从复制来避免master持久化造成的开销。master关闭持久化,从节点配置为不定期保存或是启用AOF。(注意:重新启动的master将从一个空数据集开始,作为从节点重新同步主节点数据,此时该节点数据也会被清空)
七、主从复制的注意事项
1、读写分离场景
- 数据复制延时导致读到获取数据或者读不到数据(网络原因、从节点阻塞)。
- 从节点故障。
2、全量复制情况下
- 第一次建立主从关系或者Replication ID不匹配会导致全量复制。
- 故障转移的时候也会出现全量复制。
3、复制风暴
- master故障重启,如果从节点比较多,所有从节点都要复制,对服务器的性能,网络的压力都有很大影响。
- 如果一个机器部署了多个master。
4、写能力有限
- 主从复制还是只有一台master,提供的写能力有限。
5、master故障情况下
- 如果是master无持久化,从节点开启持久化来保留数据的场景,建议不要配置redis自动重启。
- 启动redis自动重启,master启动后,无备份数据,可能导致集群数据丢失的情况(备注:可以通过哨兵高可用机制实现进行自动切主)
6、带有效期的key
- 从节点不会让key过期,而是等待master让key过期,过期后master会向从节点发送
DEL命令。 - 在Lua脚本执行期间,不执行任何key过期操作。
八、读写分离实战
@Configuration
public class ReadWriteSeperationConfig {@Beanpublic LettuceConnectionFactory redisConnectionFactory() {LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder().readFrom(ReadFrom.REPLICA_PREFERRED).build();// 地址和端口可以是master实例和可以是replica实例的RedisStandaloneConfiguration serverConfig = new RedisStandaloneConfiguration("127.0.0.1", 6379);serverConfig.setPassword("lyl");return new LettuceConnectionFactory(serverConfig, clientConfig);}
}
备注:读写分离目前有
Lettuce和Redisson客户端等支持,Jedis是不支持的。
客户端可通过info replication命令知道哪台机器是master,哪台是从节点,然后将写命令分发到master,读命令分发到从节点。
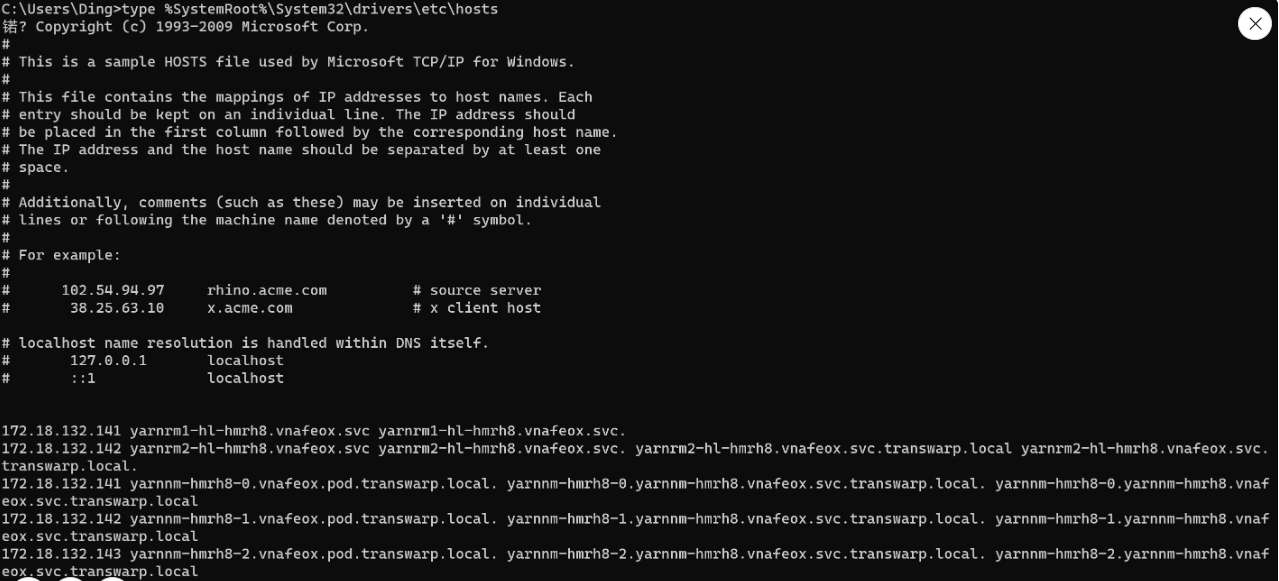
info replication命令返回内容如下:
# Replication
role:master
connected_slaves:1
slave0:ip=122.51.55.180,port=6379,state=online,offset=515783,lag=1
master_replid:2b30a3ace7a265ed5e9afcdc6925cd26cddb8ba5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:515783
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:515783